
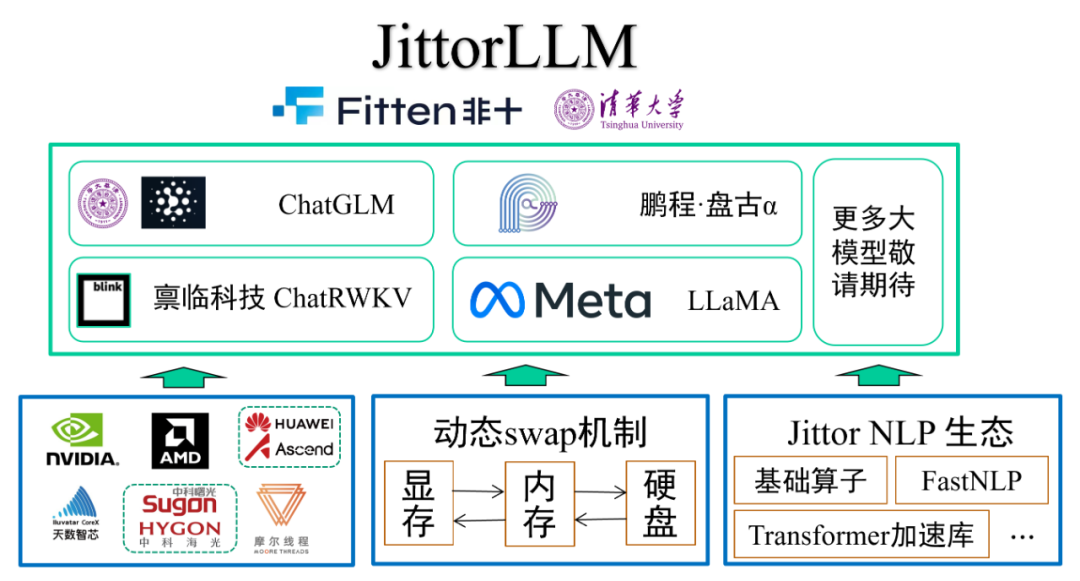















Jittor(计图): 即时编译深度学习框架
Jittor 是一个基于即时编译和元算子的高性能深度学习框架,整个框架在即时编译的同时,还集成了强大的Op编译器和调优器,为您的模型生成定制化的高性能代码。
Jittor前端语言为Python。前端使用了模块化的设计,类似于PyTorch,Keras,后端则使用高性能语言编写,如CUDA,C++。
下面的代码演示了如何一步一步使用Python代码,从头对一个双层神经网络建模。
import jittor as jt
from jittor import Module
from jittor import nn
class Model(Module):
def __init__(self):
self.layer1 = nn.Linear(1, 10)
self.relu = nn.Relu()
self.layer2 = nn.Linear(10, 1)
def execute (self,x) :
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
def get_data(n): # generate random data for training test.
for i in range(n):
x = np.random.rand(batch_size, 1)
y = x*x
yield jt.float32(x), jt.float32(y)
model = Model()
learning_rate = 0.1
optim = nn.SGD(model.parameters(), learning_rate)
for i,(x,y) in enumerate(get_data(n)):
pred_y = model(x)
loss = ((pred_y - y)**2)
loss_mean = loss.mean()
optim.step (loss_mean)
print(f"step {i}, loss = {loss_mean.data.sum()}")
大纲
教程
在教程部分,我们将简要解释Jittor的基本概念。
要使用Jittor训练模型,您需要了解两个主要概念:
- Var:Jittor的基本数据类型
- Operations:Jittor的算子与numpy类似
数据类型
首先,让我们开始使用Var。Var是jittor的基本数据类型,为了运算更加高效Jittor中的计算过程是异步的。 如果要访问数据,可以使用Var.data进行同步数据访问。
import jittor as jt
a = jt.float32([1,2,3])
print (a)
print (a.data)
# Output: float32[3,]
# Output: [ 1. 2. 3.]
此外我们可以给变量起一个名字。
a.name('a')
print(a.name())
# Output: a
数据运算
Jittor的算子与numpy类似。 让我们尝试一些运算, 我们通过Opjt.float32创建Var a和b,并将它们相加。 输出这些变量相关信息,可以看出它们具有相同的形状和类型。
import jittor as jt
a = jt.float32([1,2,3])
b = jt.float32([4,5,6])
c = a*b
print(a,b,c)
print(type(a), type(b), type(c))
# Output: float32[3,] float32[3,] float32[3,]
# Output: <class 'jittor_core.Var'> <class 'jittor_core.Var'> <class 'jittor_core.Var'>
除此之外,我们使用的所有算子jt.xxx(Var,...)都具有别名Var.xxx(...)。 例如:
c.max() # alias of jt.max(a)
c.add(a) # alias of jt.add(c, a)
c.min(keepdims=True) # alias of jt.min(c, keepdims=True)
如果您想知道Jittor支持的所有运算,可以运行help(jt.ops)。 您在jt.ops.xxx中找到的所有运算都可以通过别名jt.xxx。
help(jt.ops)
# Output:
# abs(x: core.Var) -> core.Var
# add(x: core.Var, y: core.Var) -> core.Var
# array(data: array) -> core.Var
# binary(x: core.Var, y: core.Var, op: str) -> core.Var
# ......
更多教程
如果您想进一步了解Jittor,请查看以下教程:
- 快速开始
- 进阶
贡献
Jittor还很年轻。它可能存在错误和问题。请在我们的错误跟踪系统中报告它们。我们欢迎您为Jittor做出贡献。此外,如果您对Jittor有任何想法,请告诉我们,Email:jittor@qq.com。
版权声明
如LICENSE.txt文件中所示,Jittor使用Apache 2.0版权协议。