
| 动态 | 论文 | 资源 |
感谢大家对
Jittor的关注,下面是基于Jittor开发以及与Jittor相关的最新论文。如有疑问,可以在Github提Issue、或者通过Email:jittor@qq.com联系我们。欢迎大家使用Jittor进行科学研究工作。
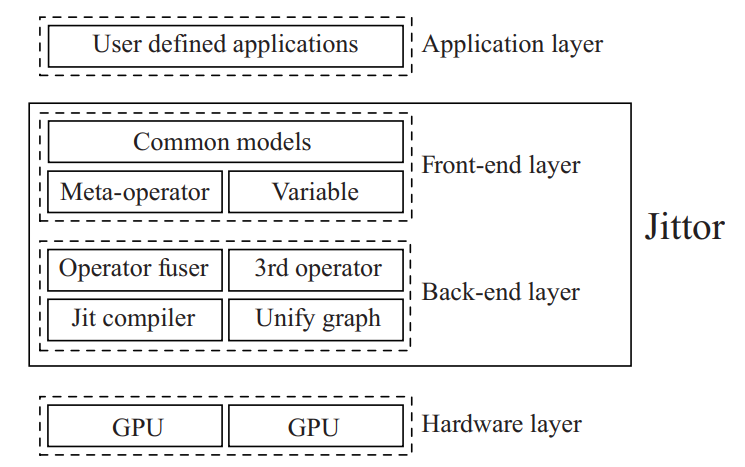
Jittor: a novel deep learning framework with meta-operators and unified graph execution
Science China Information Science,2020, Vol. 63, No. 12, 222103, doi: 10.1007/s11432-020-3097-4.
This paper introduces Jittor, a fully just-in-time (JIT) compiled deep learning framework. With JIT compilation, we can achieve higher performance while making systems highly customizable. Jittor provides classes of Numpy-like operators, which we call meta-operators. A deep learning model built upon these meta-operators is compiled into high-performance CPU or GPU code in real-time. To manage metaoperators, Jittor uses a highly optimized way of executing computation graphs, which we call unified graph execution. This approach is as easy to use as dynamic graph execution yet has the efficiency of static graph execution. It also provides other improvements, including operator fusion, cross iteration fusion, and unified memory.
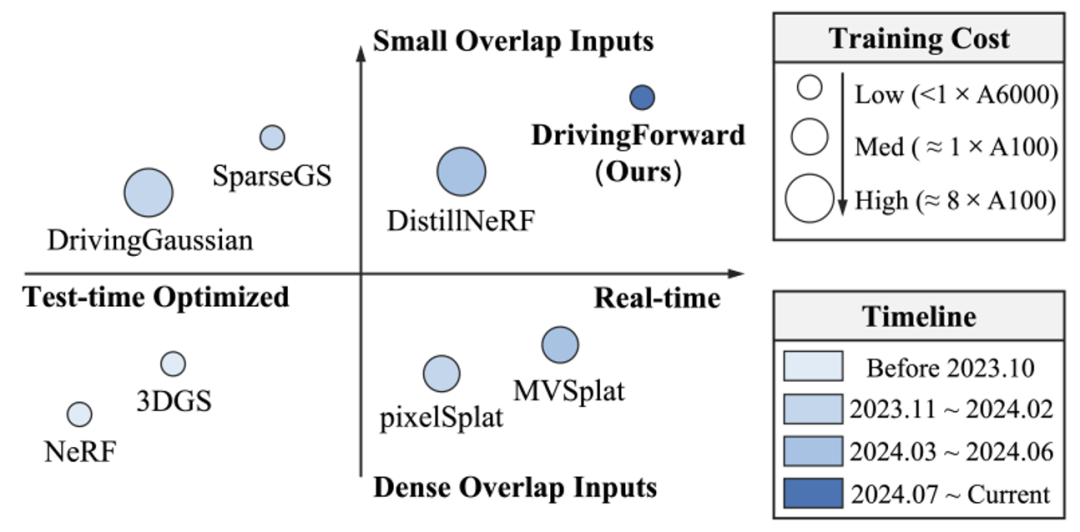
DrivingForward: Feed-forward 3D Gaussian Splatting for Driving Scene Reconstruction from Flexible Surround-view Input
AAAI, 2025
We propose DrivingForward, a feed-forward Gaussian Splatting model that reconstructs driving scenes from flexible surround-view input. Driving scene images from vehicle-mounted cameras are typically sparse, with limited overlap, and the movement of the vehicle further complicates the acquisition of camera extrinsics. To tackle these challenges and achieve real-time reconstruction, we jointly train a pose network, a depth network, and a Gaussian network to predict the Gaussian primitives that represent the driving scenes. The pose network and depth network determine the position of the Gaussian primitives in a self-supervised manner, without using depth ground truth and camera extrinsics during training. The Gaussian network independently predicts primitive parameters from each input image, including covariance, opacity, and spherical harmonics coefficients. At the inference stage, our model can achieve feed-forward reconstruction from flexible multi-frame surround-view input. Experiments on the nuScenes dataset show that our model outperforms existing state-of-the-art feed-forward and scene-optimized reconstruction methods in terms of reconstruction.

Multi-RoI Human Mesh Recovery with Camera Consistency and Contrastive Losses
ECCV, 2024
Besides a 3D mesh, Human Mesh Recovery (HMR) methods usually need to estimate a camera for computing 2D reprojection loss. Previous approaches may encounter the following problem: both the mesh and camera are not correct but the combination of them can yield a low reprojection loss. To alleviate this problem, we define multiple RoIs (region of interest) containing the same human and propose a multiple-RoI-based HMR method. Our key idea is that with multiple RoIs as input, we can estimate multiple local cameras and have the opportunity to design and apply additional constraints between cameras to improve the accuracy of the cameras and, in turn, the accuracy of the corresponding 3D mesh. To implement this idea, we propose a RoI-aware feature fusion network by which we estimate a 3D mesh shared by all RoIs as well as local cameras corresponding to the RoIs. We observe that local cameras can be converted to the camera of the full image through which we construct a local camera consistency loss as the additional constraint imposed on local cameras. Another benefit of introducing multiple RoIs is that we can encapsulate our network into a contrastive learning framework and apply a contrastive loss to regularize the training of our network. Experiments demonstrate the effectiveness of our multi-RoI HMR method and superiority to recent prior arts.
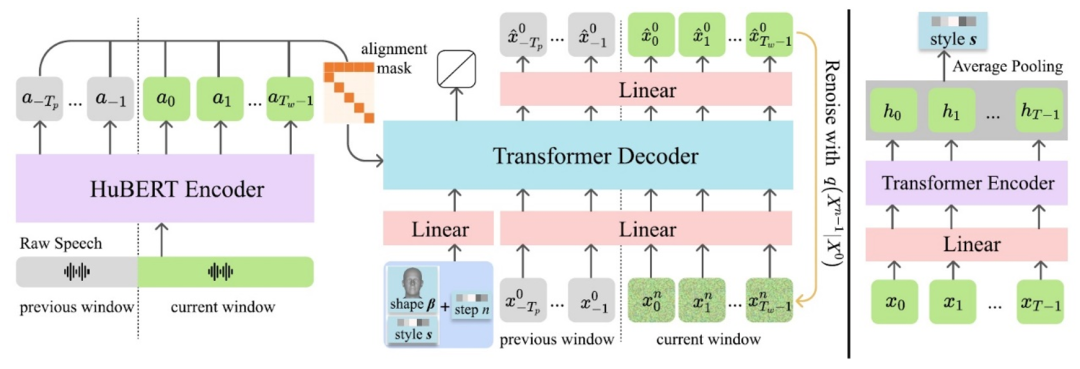
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
ACM Transactions on Graphics (TOG), Volume 43, Issue 4 Article No.: 46, Pages 1 - 9
The generation of stylistic 3D facial animations driven by speech presents a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. In particular, our style includes the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset are at https://diffposetalk.github.io.

Real-time Large-scale Deformation of Gaussian Splatting
ACM Transactions on Graphics (TOG), Volume 43, Issue 6 Article No.: 200, Pages 1 - 17
Neural implicit representations, including Neural Distance Fields and Neural Radiance Fields, have demonstrated significant capabilities for reconstructing surfaces with complicated geometry and topology, and generating novel views of a scene. Nevertheless, it is challenging for users to directly deform or manipulate these implicit representations with large deformations in a real-time fashion. Gaussian Splatting (GS) has recently become a promising method with explicit geometry for representing static scenes and facilitating high-quality and real-time synthesis of novel views. However, it cannot be easily deformed due to the use of discrete Gaussians and the lack of explicit topology. To address this, we develop a novel GS-based method (GaussianMesh) that enables interactive deformation. Our key idea is to design an innovative mesh-based GS representation, which is integrated into Gaussian learning and manipulation. 3D Gaussians are defined over an explicit mesh, and they are bound with each other: the rendering of 3D Gaussians guides the mesh face split for adaptive refinement, and the mesh face split directs the splitting of 3D Gaussians. Moreover, the explicit mesh constraints help regularize the Gaussian distribution, suppressing poor-quality Gaussians (e.g., misaligned Gaussians, long-narrow shaped Gaussians), thus enhancing visual quality and reducing artifacts during deformation. Based on this representation, we further introduce a large-scale Gaussian deformation technique to enable deformable GS, which alters the parameters of 3D Gaussians according to the manipulation of the associated mesh. Our method benefits from existing mesh deformation datasets for more realistic data-driven Gaussian deformation. Extensive experiments show that our approach achieves high-quality reconstruction and effective deformation, while maintaining the promising rendering results at a high frame rate (65 FPS on average on a single commodity GPU).

PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding
CVPR, 2024.
Recent advances in text-to-image generation have made remarkable progress in synthesizing realistic human photos conditioned on given text prompts. However existing personalized generation methods cannot simultaneously satisfy the requirements of high efficiency promising identity (ID) fidelity and flexible text controllability. In this work we introduce PhotoMaker an efficient personalized text-to-image generation method which mainly encodes an arbitrary number of input ID images into a stack ID embedding for preserving ID information. Such an embedding also empowers our method to be applied in many interesting scenarios such as when replacing the corresponding class word and when combining the characteristics of different identities. Besides to better drive the training of our PhotoMaker we propose an ID-oriented data creation pipeline to assemble the training data. Under the nourishment of the dataset constructed through the proposed pipeline our PhotoMaker demonstrates comparable performance to test-time fine-tuning-based methods yet provides significant speed improvements strong generalization capabilities and a wide range of applications.
project page coming soon paper code
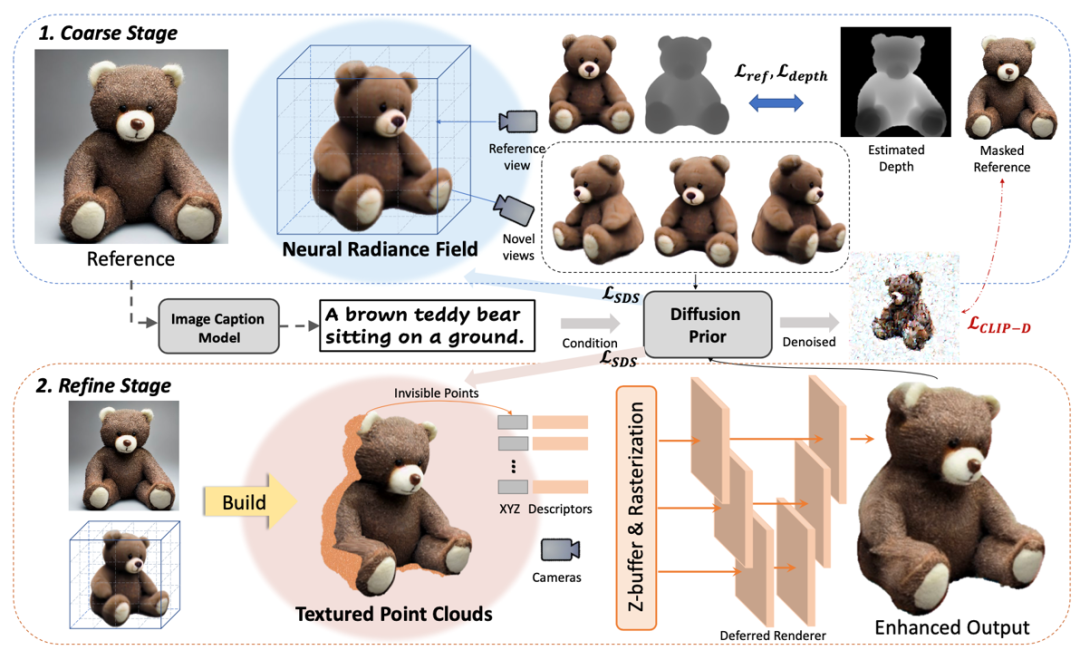
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
ICCV, 2023.
In this work, we investigate the problem of creating high-fidelity 3D content from only a single image. This is inherently challenging: it essentially involves estimating the underlying 3D geometry while simultaneously hallucinating unseen textures. To address this challenge, we leverage prior knowledge from a well-trained 2D diffusion model to act as 3D-aware supervision for 3D creation. Our approach, Make-It-3D, employs a two-stage optimization pipeline: the first stage optimizes a neural radiance field by incorporating constraints from the reference image at the frontal view and diffusion prior at novel views; the second stage transforms the coarse model into textured point clouds and further elevates the realism with diffusion prior while leveraging the high-quality textures from the reference image. Extensive experiments demonstrate that our method outperforms prior works by a large margin, resulting in faithful reconstructions and impressive visual quality. Our method presents the first attempt to achieve high-quality 3D creation from a single image for general objects and enables various applications such as text-to-3D creation and texture editing.
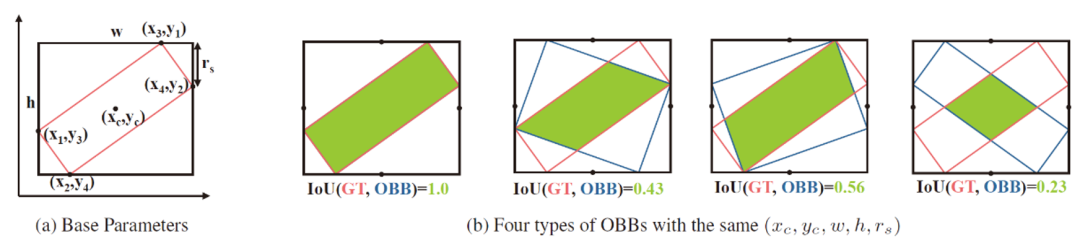
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
CVPR, 2024.
Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
project page coming soon paper code

HSDF, Hybrid Sign and Distance Field for Modeling Surfaces with Arbitrary Topologies
NeurIPS, 2022.
Neural implicit function based on signed distance field (SDF) has achieved impressive progress in reconstructing 3D models with high fidelity. However, such approaches can only represent closed shapes. Recent works based on unsigned distance function (UDF) are proposed to handle both watertight and open surfaces. Nonetheless, as UDF is signless, its direct output is limited to point cloud, which imposes an additional challenge on extracting high-quality meshes from discrete points.To address this issue, we present a new learnable implicit representation, coded HSDF, that connects the good ends of SDF and UDF. In particular, HSDF is able to represent arbitrary topologies containing both closed and open surfaces while being compatible with existing iso-surface extraction techniques for easy field-to-mesh conversion. In addition to predicting a UDF, we propose to learn an additional sign field via a simple classifier. Unlike traditional SDF, HSDF is able to locate the surface of interest before level surface extraction by generating surface points following NDF~\cite{chibane2020ndf}. We are then able to obtain open surfaces via an adaptive meshing approach that only instantiates regions containing surface into a polygon mesh. We also propose HSDF-Net, a dedicated learning framework that factorizes the learning of HSDF into two easier problems. Experiments on multiple datasets show that HSDF outperforms state-of-the-art techniques both qualitatively and quantitatively.
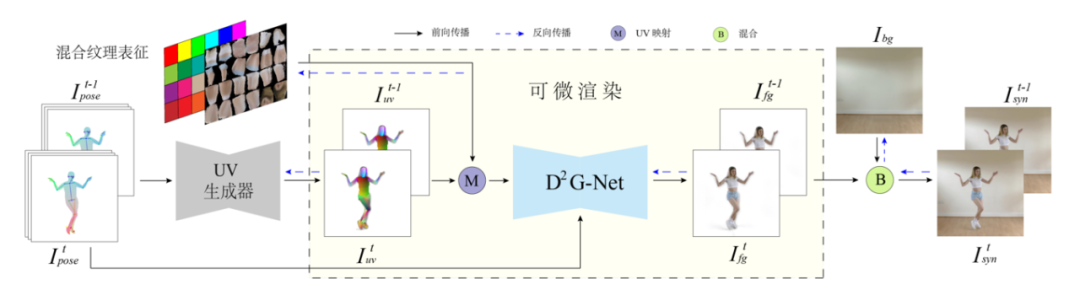
Robust Pose Transfer with Dynamic Details using Neural Video Rendering
IEEE TPAMI, 2022, 1-8.
Pose transfer of human videos aims to generate a high-fidelity video of a target person imitating actions of a source person. A few studies have made great progress either through image translation with deep latent features or neural rendering with explicit 3D features. However, both of them rely on large amounts of training data to generate realistic results, and the performance degrades on more accessible Internet videos due to insufficient training frames. In this paper, we demonstrate that the dynamic details can be preserved even when trained from short monocular videos. Overall, we propose a neural video rendering framework coupled with an image-translation-based dynamic details generation network (D 2 G-Net), which fully utilizes both the stability of explicit 3D features and the capacity of learning components. To be specific, a novel hybrid texture representation is presented to encode both the static and pose-varying appearance characteristics, which is then mapped to the image space and rendered as a detail-rich frame in the neural rendering stage. Through extensive comparisons, we demonstrate that our neural human video renderer is capable of achieving both clearer dynamic details and more robust performance even on accessible short videos with only 2 k ∼ 4 k frames, as illustrated in Fig. 1.
project page coming soon paper code
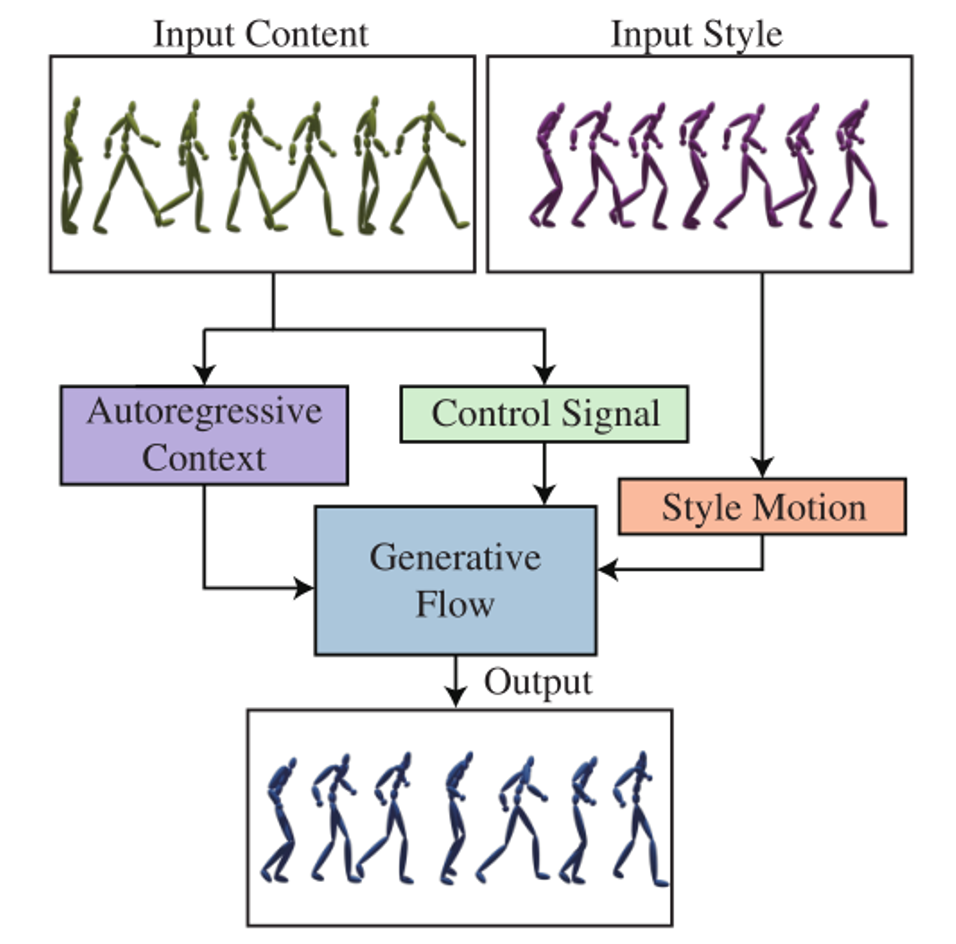
Autoregressive Stylized Motion Synthesis with Generative Flow
CVPR 2021.
Transferring the motion style from one animation clip to another, while preserving the motion content of the latter, has been a long-standing problem in character animation. Most existing data-driven approaches are supervised and rely on paired data, where motions with the same content are performed in different styles. In addition, these approaches are limited to transfer of styles that were seen during training. In this paper, we present a novel data-driven framework for motion style transfer, which learns from an unpaired collection of motions with style labels, and enables transferring motion styles not observed during training. Furthermore, our framework is able to extract motion styles directly from videos, bypassing 3D reconstruction, and apply them to the 3D input motion. Our style transfer network encodes motions into two latent codes, for content and for style, each of which plays a different role in the decoding (synthesis) process. While the content code is decoded into the output motion by several temporal convolutional layers, the style code modifies deep features via temporally invariant adaptive instance normalization (AdaIN). Moreover, while the content code is encoded from 3D joint rotations, we learn a common embedding for style from either 3D or 2D joint positions, enabling style extraction from videos. Our results are comparable to the state-of-the-art, despite not requiring paired training data, and outperform other methods when transferring previously unseen styles. To our knowledge, we are the first to demonstrate style transfer directly from videos to 3D animations - an ability which enables one to extend the set of style examples far beyond motions captured by MoCap systems.
project page coming soon paper code
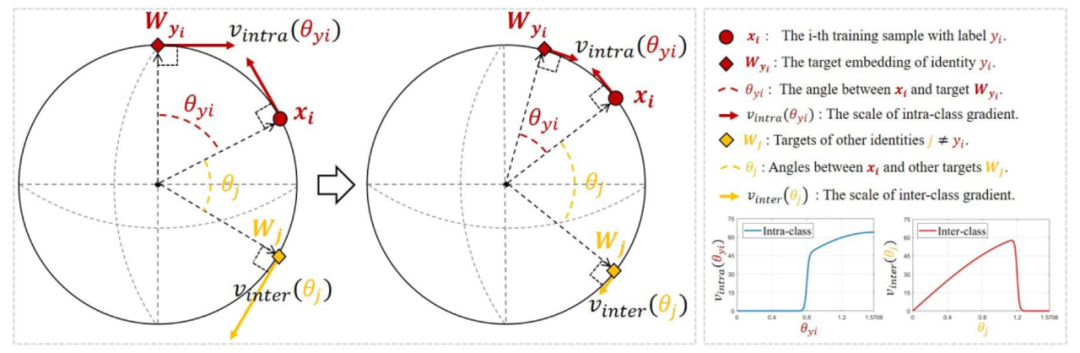
SFace: sigmoid-constrained hypersphere lossfor robust face recognition
IEEE Transactions on Image Processing, Vol. 30, 2587-2598, 2021.
Deep face recognition has achieved great success due to large-scale training databases and rapidly developing loss functions. The existing algorithms devote to realizing an ideal idea: minimizing the intra-class distance and maximizing the inter-class distance. However, they may neglect that there are also low quality training images which should not be optimized in this strict way. Considering the imperfection of training databases, we propose that intra-class and inter-class objectives can be optimized in a moderate way to mitigate overfitting problem, and further propose a novel loss function, named sigmoid-constrained hypersphere loss (SFace). Specifically, SFace imposes intra-class and inter-class constraints on a hypersphere manifold, which are controlled by two sigmoid gradient re-scale functions respectively. The sigmoid curves precisely re-scale the intra-class and inter-class gradients so that training samples can be optimized to some degree. Therefore, SFace can make a better balance between decreasing the intra-class distances for clean examples and preventing overfitting to the label noise, and contributes more robust deep face recognition models. Extensive experiments of models trained on CASIA-WebFace, VGGFace2, and MS-Celeb-1M databases, and evaluated on several face recognition benchmarks, such as LFW, MegaFace and IJB-C databases, have demonstrated the superiority of SFace.
project page coming soon paper code
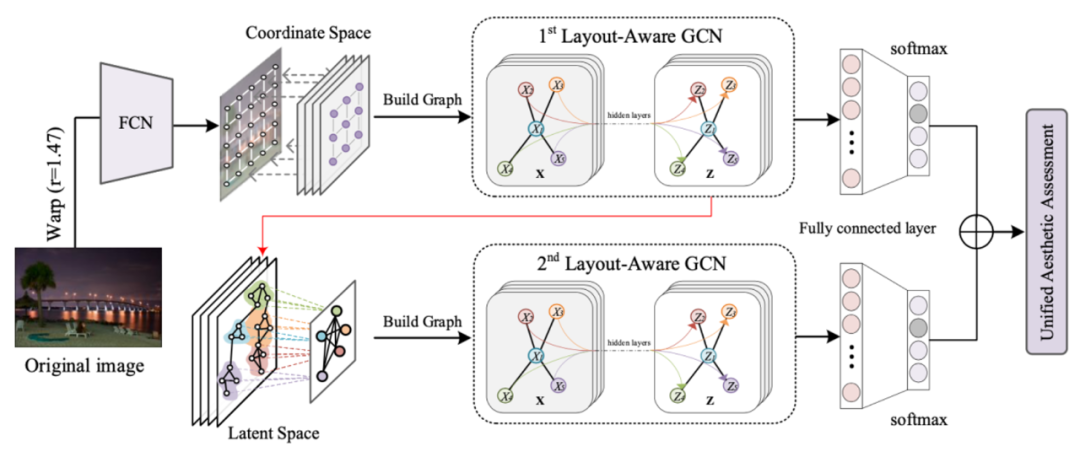
Hierarchical Layout-Aware GraphConvolutional Network for Unified Aesthetics Assessment
CVPR 2021.
Learning computational models of image aesthetics can have a substantial impact on visual art and graphic design. Although automatic image aesthetics assessment is a challenging topic by its subjective nature, psychological studies have confirmed a strong correlation between image layouts and perceived image quality. While previous state-of-the-art methods attempt to learn holistic information using deep Convolutional Neural Networks (CNNs), our approach is motivated by the fact that Graph Convolutional Network (GCN) architecture is conceivably more suited for modeling complex relations among image regions than vanilla convolutional layers. Specifically, we present a Hierarchical Layout-Aware Graph Convolutional Network (HLA-GCN) to capture layout information. It is a dedicated double-subnet neural network consisting of two LAGCN modules. The first LA-GCN module constructs an aesthetics-related graph in the coordinate space and performs reasoning over spatial nodes. The second LA-GCN module performs graph reasoning after aggregating significant regions in a latent space. The model output is a hierarchical representation with layout-aware features from both spatial and aggregated nodes for unified aesthetics assessment. Extensive evaluations show that our proposed model outperforms the state-of-the-art on the AVA and AADB datasets across three different tasks. The code is available at http://github.com/days1011/HLAGCN.
project page coming soon paper code
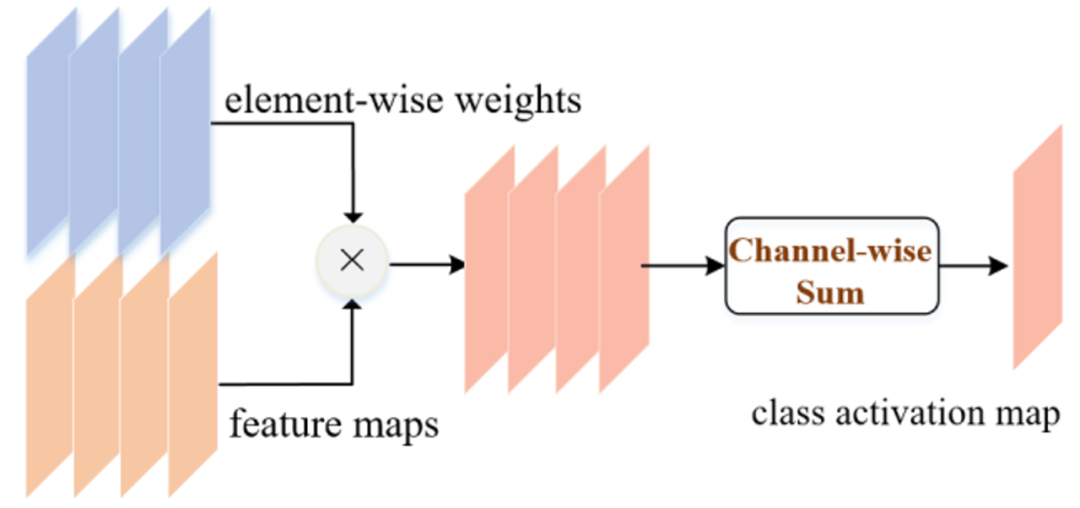
LayerCAM: Exploring Hierarchical Class Activation Maps for Localization
IEEE Transactions on Image Processing 2021.
The class activation maps are generated from the final convolutional layer of CNN. They can highlight discriminative object regions for the class of interest. These discovered object regions have been widely used for weakly-supervised tasks. However, due to the small spatial resolution of the final convolutional layer, such class activation maps often locate coarse regions of the target objects, limiting the performance of weaklysupervised tasks that need pixel-accurate object locations. Thus, we aim to generate more fine-grained object localization information from the class activation maps to locate the target objects more accurately. In this paper, by rethinking the relationships between the feature maps and their corresponding gradients, we propose a simple yet effective method, called LayerCAM. It can produce reliable class activation maps for different layers of CNN. This property enables us to collect object localization information from coarse (rough spatial localization) to fine (precise fine-grained details) levels. We further integrate them into a high-quality class activation map, where the object-related pixels can be better highlighted. To evaluate the quality of the class activation maps produced by LayerCAM, we apply them to weakly-supervised object localization and semantic segmentation. Experiments demonstrate that the class activation maps generated by our method are more effective and reliable than those by the existing attention methods. The code will be made publicly available.
project page coming soon paper code

Concealed Object Detection
IEEE TPAMI, 2021.
We present a comprehensive study on a new task named camouflaged object detection (COD), which aims to identify objects that are “seamlessly” embedded in their surroundings. The high intrinsic similarities between the target object and the background make COD far more challenging than the traditional object detection task. To address this issue, we elaborately collect a novel dataset, called COD10K, which comprises 10,000 images covering camouflaged objects in various natural scenes, over 78 object categories. All the images are densely annotated with category, bounding-box, object-/instance-level, and matting level labels. This dataset could serve as a catalyst for progressing many vision tasks, e.g., localization, segmentation, and alpha-matting, etc. In addition, we develop a simple but effective framework for COD, termed Search Identification Network (SINet). Without any bells and whistles, SINet outperforms various state-of-the-art object detection baselines on all datasets tested, making it a robust, general framework that can help facilitate future research in COD. Finally, we conduct a large-scale COD study, evaluating 13 cutting-edge models, providing some interesting findings, and showing several potential applications. Our research offers the community an opportunity to explore more in this new field. The code will be available at https://github.com/DengPingFan/SINet/

Deep Hough Transform for Semantic Line Detection
IEEE TPAMI, 2021.
In this paper, we put forward a simple yet effective method to detect meaningful straight lines, a.k.a. semantic lines, in given scenes. Prior methods take line detection as a special case of object detection, while neglect the inherent characteristics of lines, leading to less efficient and suboptimal results. We propose a one-shot end-to-end framework by incorporating the classical Hough transform into deeply learned representations. By parameterizing lines with slopes and biases, we perform Hough transform to translate deep representations to the parametric space and then directly detect lines in the parametric space. More concretely, we aggregate features along candidate lines on the feature map plane and then assign the aggregated features to corresponding locations in the parametric domain. Consequently, the problem of detecting semantic lines in the spatial domain is transformed to spotting individual points in the parametric domain, making the post-processing steps,i.e.non-maximal suppression, more efficient. Furthermore, our method makes it easy to extract contextual line features, that are critical to accurate line detection. Experimental results on a public dataset demonstrate the advantages of our method over state-of-the-arts.
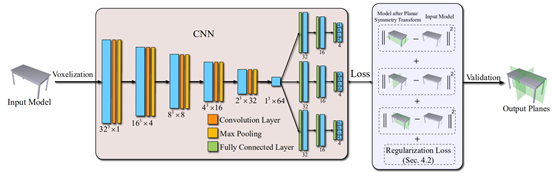
PRS-Net: Planar Reflective Symmetry Detection Net for 3D Models
IEEE Transactions on Visualization and Computer Graphics, 2020.
In geometry processing, symmetry is a universal type of high-level structural information of 3D models and benefits many geometry processing tasks including shape segmentation, alignment, matching, and completion. Thus it is an important problem to analyze various symmetry forms of 3D shapes. Planar reflective symmetry is the most fundamental one. Traditional methods based on spatial sampling can be time-consuming and may not be able to identify all the symmetry planes. In this paper, we present a novel learning framework to automatically discover global planar reflective symmetry of a 3D shape. Our framework trains an unsupervised 3D convolutional neural network to extract global model features and then outputs possible global symmetry parameters, where input shapes are represented using voxels. We introduce a dedicated symmetry distance loss along with a regularization loss to avoid generating duplicated symmetry planes. Our network can also identify generalized cylinders by predicting their rotation axes. We further provide a method to remove invalid and duplicated planes and axes. We demonstrate that our method is able to produce reliable and accurate results. Our neural network based method is hundreds of times faster than the state-of-the-art methods, which are based on sampling. Our method is also robust even with noisy or incomplete input surfaces.
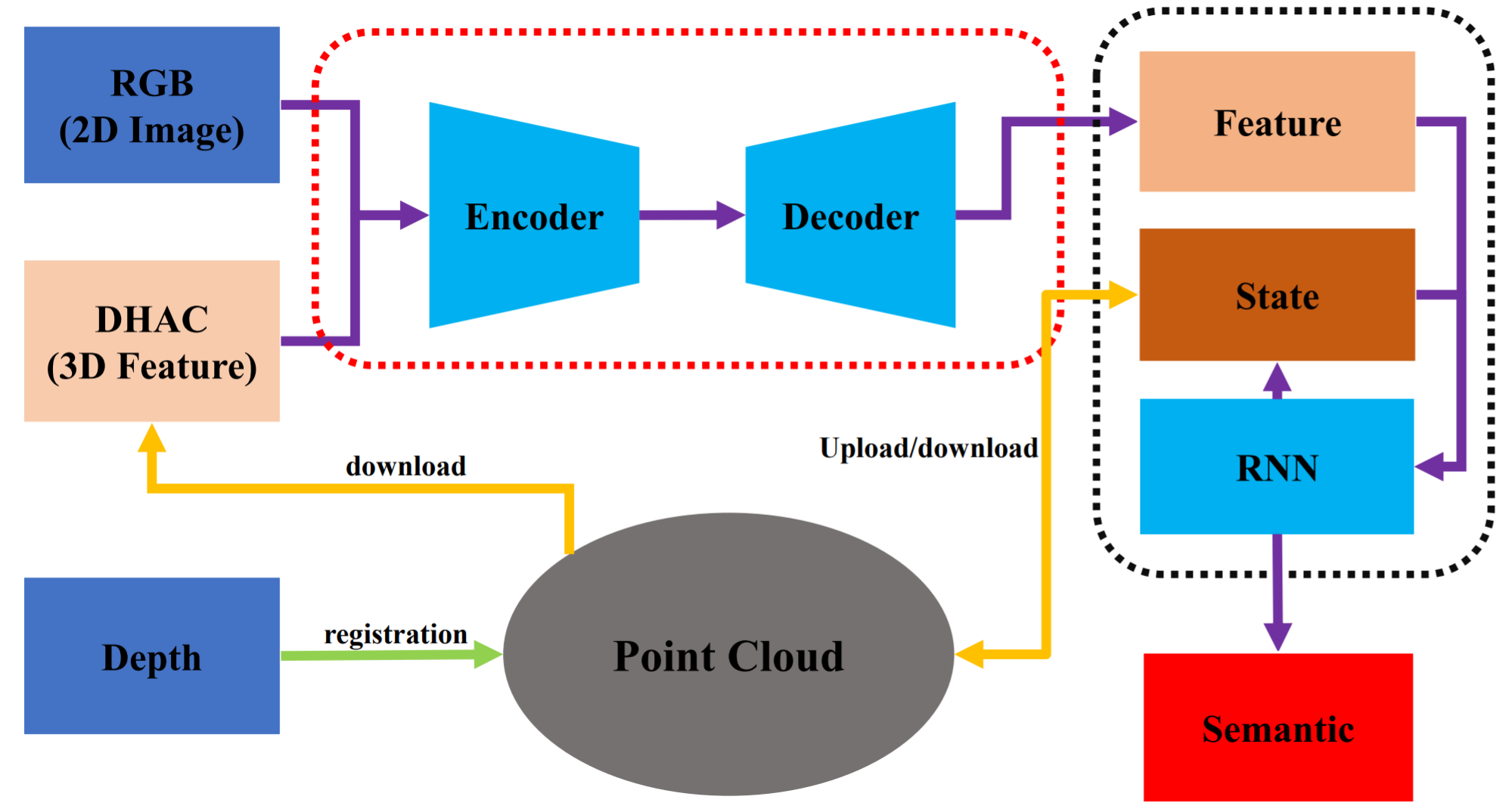
LinkNet: 2D-3D linked multi-modal network for online semantic segmentation of RGB-D videos
Computers & Graphics, 2021.
This paper proposes LinkNet, a 2D-3D linked multi-modal network served for online semantic segmentation of RGB-D videos, which is essential for real-time applications such as robot navigation. Existing methods for RGB-D semantic segmentation usually work in the regular image domain, which allows efficient processing using convolutional neural networks (CNNs). However, RGB-D videos are captured from a 3D scene, and different frames can contain useful information of the same local region from different views. Working solely in the image domain fails to utilize such crucial information. Our novel approach is based on joint 2D and 3D analysis. The online process is realized simultaneously with 3D scene reconstruction, from which we set up 2D-3D links between continuous RGB-D frames and 3D point cloud. We combine image color and view-insensitive geometric features generated from the 3D point cloud for multi-modal semantic feature learning. Our LinkNet further uses a recurrent neural network (RNN) module to dynamically maintain the hidden semantic states during 3D fusion, and refines the voxel-based labeling results. The experimental results on SceneNet [1] and ScanNet [2] demonstrate that the semantic segmentation results of our framework are stable and effective.
project page coming soon paper code
DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control
ACM Transactions on Graphics, 40(4), 90: 1--90: 15, 2021. (SIGGRAPH 2021)
Recent facial image synthesis methods have been mainly based on conditional generative models. Sketch-based conditions can effectively describe the geometry of faces, including the contours of facial components, hair structures, as well as salient edges (e.g., wrinkles) on face surfaces but lack effective control of appearance, which is influenced by color, material, lighting condition, etc. To have more control of generated results, one possible approach is to apply existing disentangling works to disentangle face images into geometry and appearance representations. However, existing disentangling methods are not optimized for human face editing, and cannot achieve fine control of facial details such as wrinkles. To address this issue, we propose DeepFaceEditing, a structured disentanglement framework specifically designed for face images to support face generation and editing with disentangled control of geometry and appearance. We adopt a local-to-global approach to incorporate the face domain knowledge: local component images are decomposed into geometry and appearance representations, which are fused consistently using a global fusion module to improve generation quality. We exploit sketches to assist in extracting a better geometry representation, which also supports intuitive geometry editing via sketching. The resulting method can either extract the geometry and appearance representations from face images, or directly extract the geometry representation from face sketches. Such representations allow users to easily edit and synthesize face images, with decoupled control of their geometry and appearance. Both qualitative and quantitative evaluations show the superior detail and appearance control abilities of our method compared to state-of-the-art methods.
project page paper coming soon code

DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Previous online 3D dense reconstruction methods struggle to achieve the balance between memory storage and surface quality, largely due to the usage of stagnant underlying geometry representation, such as TSDF (truncated signed distance functions) or surfels, without any knowledge of the scene priors. In this paper, we present DI-Fusion (Deep Implicit Fusion), based on a novel 3D representation, i.e. Probabilistic Local Implicit Voxels (PLIVoxs), for online 3D reconstruction with a commodity RGB-D camera. Our PLIVox encodes scene priors considering both the local geometry and uncertainty parameterized by a deep neural network. With such deep priors, we are able to perform online implicit 3D reconstruction achieving state-ofthe-art camera trajectory estimation accuracy and mapping quality, while achieving better storage efficiency compared with previous online 3D reconstruction approaches. Our implementation is available at https://www.github.com/huangjh-pub/di-fusion.
project page coming soon paper code
Representative Batch Normalization with Feature Calibration
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral)
Batch Normalization (BatchNorm) has become the default component in modern neural networks to stabilize training. In BatchNorm, centering and scaling operations, along with mean and variance statistics, are utilized for feature standardization over the batch dimension. The batch dependency of BatchNorm enables stable training and better representation of the network, while inevitably ignores the representation differences among instances. We propose to add a simple yet effective feature calibration scheme into the centering and scaling operations of BatchNorm, enhancing the instance-specific representations with the negligible computational cost. The centering calibration strengthens informative features and reduces noisy features. The scaling calibration restricts the feature intensity to form a more stable feature distribution. Our proposed variant of BatchNorm, namely Representative BatchNorm, can be plugged into existing methods to boost the performance of various tasks such as classification, detection, and segmentation. The source code is available in http://mmcheng.net/rbn.
project page coming soon paper code
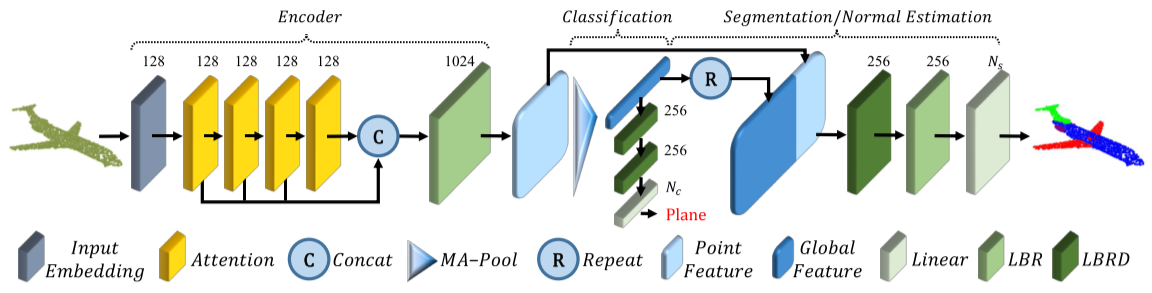
Pct: Point cloud transformer
Computational Visual Media, 2021, Vol. 7, https://doi.org/10.1007/s41095-021-0229-5.
The irregular domain and lack ofordering make it challenging to design deep neural networks for point cloud processing. This paper presents a novel framework named Point Cloud Transformer(PCT) for point cloud learning. PCT is based on Transformer, which achieves huge success in natural language processing and displays great potential in image processing. It is inherently permutation invariant for processing a sequence of points, making it well-suited for point cloud learning. To better capture local context within the point cloud, we enhance input embedding with the support offarthest point sampling and nearest neighbor search. Extensive experiments demonstrate that the PCT achieves the state-of-the-art performance on shape classification, part segmentation and normal estimation tasks.
project page coming soon paper code

DeepFaceDrawing: Deep Generation of Face Images from Sketches
ACM Transactions on Graphics, 39(4), 72: 1-72: 16, 2020. (SIGGRAPH 2020)
Recent deep image-to-image translation techniques allow fast generation of face images from freehand sketches. However, existing solutions tend to overfit to sketches, thus requiring professional sketches or even edge maps as input. To address this issue, our key idea is to implicitly model the shape space of plausible face images and synthesize a face image in this space to approximate an input sketch. We take a local-to-global approach. We first learn feature embeddings of key face components, and push corresponding parts of input sketches towards underlying component manifolds defined by the feature vectors of face component samples. We also propose another deep neural network to learn the mapping from the embedded component features to realistic images with multi-channel feature maps as intermediate results to improve the information flow. Our method essentially uses input sketches as soft constraints and is thus able to produce high-quality face images even from rough and/or incomplete sketches. Our tool is easy to use even for non-artists, while still supporting fine-grained control of shape details. Both qualitative and quantitative evaluations show the superior generation ability of our system to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
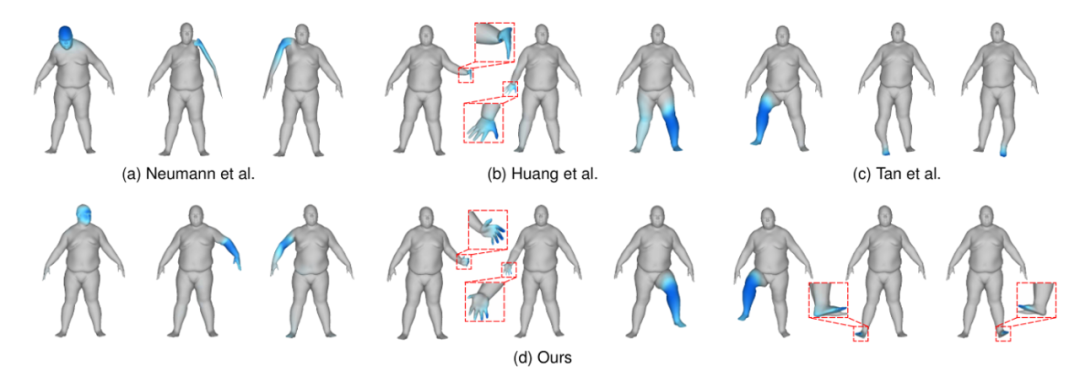
Mesh-based Variational Autoencoders for Localized Deformation Component Analysis
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
Spatially localized deformation components are very useful for shape analysis and synthesis in 3D geometry processing. Several methods have recently been developed, with an aim to extract intuitive and interpretable deformation components. However, these techniques suffer from fundamental limitations especially for meshes with noise or large-scale nonlinear deformations, and may not always be able to identify important deformation components. In this paper we propose a novel mesh-based variational autoencoder architecture that is able to cope with meshes with irregular connectivity and nonlinear deformations. To help localize deformations, we introduce sparse regularization along with spectral graph convolutional operations. Through modifying the regularization formulation and allowing dynamic change of sparsity ranges, we improve the visual quality and reconstruction ability. Our system also provides a nonlinear approach to reconstruction of meshes using the extracted basis, which is more effective than the current linear combination approach. We further develop a neural shape editing method, achieving shape editing and deformation component extraction in a unified framework and ensuring plausibility of the edited shapes. Extensive experiments show that our method outperforms state-of-the-art methods in both qualitative and quantitative evaluations. We also demonstrate the effectiveness of our method for neural shape editing.
project page coming soon paper code