
计图(Jittor)发布1.1版本:新增骨干网络、JIT功能升级、支持多卡训练
清华大学深度学习框架—计图(Jittor)于3月20日发布后,研发团队收到了大量的反馈,感谢大家的关注与支持。
经过研发团队的努力,Jittor的新版本V1.1上线了。主要变化包括:
- 增加了大量骨干网络的支持,增强了辅助转换脚本的能力,降低用户开发和移植模型的难度。
- JIT(动态编译)功能升级,可支持高性能的自定义算子开发,并降低了用户开发自定义算子的难度。
- 新增分布式功能,用户无需修改代码,只需要修改启动命令,单卡版本的训练程序可以直接无缝部署到多卡甚至多机上。
此外,Jittor还新增支持了大量神经网络算子,完善了对深度神经网络开发的支持。
新增骨干网络
本次发布的Jittor 1.1版本在模型库中新增了大量基础骨干网络,用户可以基于这些基础骨干网络搭建自己的深度学习模型。这些骨干网络参数与PyTorch参数格式兼容,可以相互加载调用,方便用户学习和迁移。
本次更新的骨干网络包括:
import jittor.models
from jittor.models import \
alexnet, \
googlenet, \
inception_v3, \
mnasnet, \
mobilenet_v2, \
resnext101_32x8d, \
shufflenetv2, \
squeezenet, \
wide_resnet101_2
# 更多主干网络支持请参考
print(dir(jittor.models))
下面是对AlexNet、VGG、ResNet、Wide ResNet和SqueezeNet等多种骨干网络,在不同的batch size下,Jittor与PyTorch的单次前向性能对比,图1中横轴为不同Batch size,纵轴为FPS(每秒处理的图像数)。实验环境为:GPU为1080ti,显存11GB,CPU为i7-6850K,内存32GB,使用32位浮点数计算。
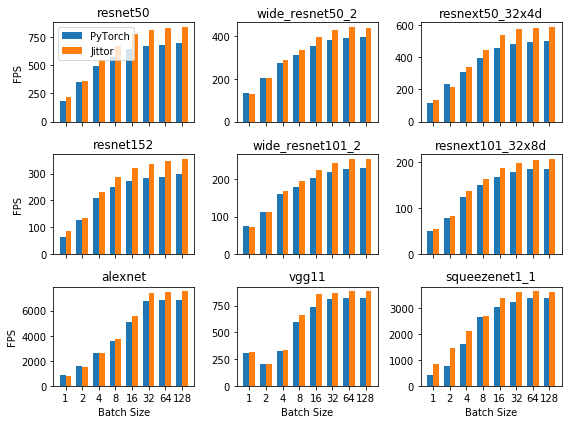
可以看出Jittor在这些常用骨干网络上的速度非常可观,大多数网络Jittor会有速度的提升。欢迎大家使用Jittor来加速自己的模型。 后续的版本中,Jittor将不断增加对更多骨干网络的支持,敬请期待。
增强辅助转换脚本
此次更新还提供了简单的辅助转换脚本,支持从PyTorch转换模型代码,暂不支持模型以外代码,下面是一个简单的实例:
from jittor.utils.pytorch_converter import convert
pytorch_code = """
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 3)
self.conv2 = nn.Conv2d(10, 32, 3)
self.fc = nn.Linear(1200, 100)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
"""
jittor_code = convert(pytorch_code)
print("## Generate Jittor code:", jittor_code)
exec(jittor_code)
model = Model()
print("## Jittor model:", model)
上面的脚本将输出计图模型代码,以及一个可用的模型:
## 生成的计图代码:
import jittor as jt
from jittor import init
from jittor import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv(1, 10, 3)
self.conv2 = nn.Conv(10, 32, 3)
self.fc = nn.Linear(1200, 100)
def execute(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view((x.shape[0], (- 1)))
x = self.fc(x)
return x
## 计图模型:
Model(
conv1: Conv(1, 10, (3, 3), (1, 1), (0, 0), (1, 1), groups=1, bias=float[10,])
conv2: Conv(10, 32, (3, 3), (1, 1), (0, 0), (1, 1), groups=1, bias=float[32,])
fc: Linear(1200, 100, float32[100,], None)
)
关于模型转换脚本的详细使用请参考计图官方教程。
JIT功能升级
Jittor 1.1版本的 JIT(动态编译)功能的增强,主要体现在code算子的功能增强上。Code算子是一个基于高性能语言的动态编译算子,允许用户直接在Python中内联C++/CUDA代码,只需要寥寥数行代码,就可以完成高性能的自定义算子开发,降低用户开发自定义算子的难度。
下面的实例展示了如何使用code算子,使用数行代码实现三维点云中十分常用的K近邻查找。Code算子的设计和实现让用户既可以享受到Python语言的便捷与易用性,又可以获得高性能语言的性能。
a = jt.random((n,3))
b = jt.code([n, k], "int32", [a],
cpu_header="#include <algorithm>",
cpu_src="""
using namespace std;
auto n=out_shape0, k=out_shape1;
// 使用openmp实现自动并行化
#pragma omp parallel for
for (int i=0; i<n; i++) {
// 存储k近邻的距离和下标
vector<pair<float,int>> id(n);
for (int j=0; j<n; j++) {
auto dx = @in0(i,0)-@in0(j,0);
auto dy = @in0(i,1)-@in0(j,1);
auto dz = @in0(i,2)-@in0(j,2);
id[j] = {dx*dx+dy*dy+dz*dz, j};
}
// 使用c++算法库的nth_element排序
nth_element(id.begin(),
id.begin()+k, id.end());
// 将下标输出到计图的变量中
for (int j=0; j<k; j++)
@out(i,j) = id[j].second;
}"""
)
我们将计图使用code算子实现的K近邻查找,和PyTorch的算子用时进行比较,速度对比如下(k=10,点云数量n=[100,1000,10000]):
| 参数 | n=100 | n=1000 | n=10000 |
|---|---|---|---|
| PyTorch | 433 µs | 7.6 ms | 623 ms |
| Jittor | 68 µs | 5.9 ms | 484 ms |
| 速度对比 | 6.4X | 1.29X | 1.29X |
注:此处使用的K近邻算法为暴力算法,还存在更优的算法实现,由于文章篇幅有限,此处仅用于展示Code算子的使用。
本次更新大幅度提升了code算子的易用性和可读性,主要包含以下几点:
- code 算子 可以有多个输出
- code 算子 允许输出动态大小的变量
- code 算子 内部可以写注释
- code 算子 可以通过@alias为input和outputs增加别名,增加代码可读性
具体文档请参考help(jt.code)和我们提供的教程,计图为您提供了多种实例以供参考。目前内联C++代码支持CUDA和openmp,未来会加入更多语言和库的支持,敬请期待。
分布式接口
计图本次分布式更新主要基于MPI(Message Passing Interface),依赖OpenMPI,用户可以使用如下命令安装OpenMPI:
sudo apt install openmpi-bin openmpi-common libopenmpi-dev
OpenMPI安装完成以后,用户无需修改代码,需要做的仅仅是修改启动命令行,计图就会用数据并行的方式自动完成并行操作。
# 单卡训练代码
python3.7 -m jittor.test.test_resnet
# 分布式多卡训练代码
mpirun -np 4 python3.7 -m jittor.test.test_resnet
# 指定特定显卡的多卡训练代码
CUDA_VISIBLE_DEVICES="2,3" mpirun -np 2 python3.7 -m jittor.test.test_resnet
这种便捷性的背后是计图的分布式算子的支撑,计图支持的mpi算子后端会使用nccl进行进一步的加速。计图所有分布式算法的开发均在Python前端完成,这让分布式算法的灵活度增强,开发分布式算法的难度也大大降低。下面的代码是使用计图实现分布式同步批归一化层的实例代码:
def execute(self, x):
if self.is_train:
xmean = jt.mean(x, dims=[0,2,3], keepdims=1)
x2mean = jt.mean(x*x, dims=[0,2,3], keepdims=1)
if self.sync and jt.mpi:
xmean = xmean.mpi_all_reduce("mean")
x2mean = x2mean.mpi_all_reduce("mean")
xvar = x2mean-xmean*xmean
norm_x = (x-xmean)/jt.sqrt(xvar+self.eps)
self.running_mean += (xmean.sum([0,2,3])-self.running_mean)*self.momentum
self.running_var += (xvar.sum([0,2,3])-self.running_var)*self.momentum
else:
running_mean = self.running_mean.broadcast(x, [0,2,3])
running_var = self.running_var.broadcast(x, [0,2,3])
norm_x = (x-running_mean)/jt.sqrt(running_var+self.eps)
w = self.weight.broadcast(x, [0,2,3])
b = self.bias.broadcast(x, [0,2,3])
return norm_x * w + b
这次更新,我们开放了mpi算子的稳定接口,用户可以自行使用mpi算子开发所需的自定义的分布式算法,相关文档请参考help(jittor.mpi.ops)和计图分布式教程。基于这些mpi算子接口,研发团队已经集成了如下三种分布式相关的算法:
- 分布式数据并行加载
- 分布式优化器
- 分布式同步批归一化层
其他更新
教程更新列表:
算子更新列表:
- group conv
- 三角函数,反三角函数,双曲函数,反双曲函数支持
- flatten
- view
- permute
- adapool
- PReLU
- LeakyReLU
- ReLU6
- ReflectionPad2d
- ZeroPad2d
- ConstantPad2d
- ReplicationPad2d
- PixelShuffle
- Upsample
损失函数更新列表:
- MSELoss
- BCELoss
- L1Loss
- BCEWithLogitsLoss
分布式相关算子:
- mpi_all_reduce
- mpi_reduce
- mpi_broadcast
- nccl_all_reduce
- nccl_reduce
- nccl_broadcast
安装与反馈
计图的安装请参考:https://cg.cs.tsinghua.edu.cn/jittor/download/
如果您在使用中碰到任何问题,欢迎邮件联系我们:jittor@qq.com,或者在计图的Github发布issue。
更多信息,请参见我们的主页:https://cg.cs.tsinghua.edu.cn/jittor/
感谢各位用户的支持和建议,计图研发团队将会持续不断地发布新特性和内容,请关注我们的实验室公众号:“图形学与几何计算”。