
前言
Pytorch凭借其成熟性和易用性,受到了大家的欢迎,是目前学术界使用最为广泛的深度学习框架之一。
为了方便大家尽快地使用和了解Jittor,我们提供了一个简单的Pytorch模型代码转Jittor模型的脚本。我们经过大量用户调研,发现大家更容易接受Class+Module的代码书写风格,因此Jittor强调底层代码的优化和创新,在前端仍采用大家熟悉的Class+Module方式。这为Pytorch模型代码转Jittor提供了很大的便利。
我们提供了简单的脚本来转换模型model代码,其他代码(数据集、训练代码)暂不支持转换。
在本教程中,第一部分,我们会展示如何使用该脚本转换您的Pytorch代码,我们将torchvision.models里提供的AlexNet[1]、VGG[2]、ResNet[3]、SqueezeNet[4]、Wide ResNet[5]转换成了Jittor的模型;第二部分,我们将简单介绍转换原理,以便用户自行修改转换脚本。第三部分,我们将介绍如何正确地测试Pytorch和Jittor的时间性能;第四部分,将展示Pytorch的model和Jittor的model在相同条件下的时间性能测试结果。
第一部分 如何使用转换脚本
首先,按照安装教程成功安装Jittor。将您的模型代码放在下面测试代码中的pytorch_code里或者通过文件读入,然后运行convert(pytorch_code)来完成转换。示例代码如下。
from jittor.utils.pytorch_converter import convert
pytorch_code="""
from torch import nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
"""
jittor_code = convert(pytorch_code)
print(jittor_code)
你将会得到如下输出,成功转换!
import jittor as jt
from jittor import init
from jittor import nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv(3, 64, 11, stride=4, padding=2),
nn.ReLU(),
nn.Pool(3, stride=2, op='maximum'),
nn.Conv(64, 192, 5, padding=2),
nn.ReLU(),
nn.Pool(3, stride=2, op='maximum'),
nn.Conv(192, 384, 3, padding=1),
nn.ReLU(),
nn.Conv(384, 256, 3, padding=1),
nn.ReLU(),
nn.Conv(256, 256, 3, padding=1),
nn.ReLU(),
nn.Pool(3, stride=2, op='maximum')
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(((256 * 6) * 6), 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
def execute(self, x):
x = self.features(x)
x = jt.flatten(x, start_dim=1)
x = self.classifier(x)
return x
我们对torchvision.models里提供的AlexNet[1]、VGG[2]、ResNet[3]、SqueezeNet[4]、Wide ResNet[5]进行了转换,并进行了前向时间测试。
第二部分 转换原理
在pytorch_converter.py里有一张映射表pjmap,通过这张表可以将Pytorch的函数转换为Jittor的函数。
下面举例说明Pytorch的AvgPool2d是如何转换为Jittor的Pool的。
下面是Pytorch的AvgPool2d的实现。
class AvgPool2d(Module):
def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None):
...
def forword(self, x):
...
假如您在Jittor中实现了Pool,如下。
class Pool(Module):
def __init__(self, kernel_size, stride=None, padding=0, dilation=None, return_indices=None, ceil_mode=False, op="maximum"):
...
def execute(self, x):
...
那么您需要在pytorch_converter.py的pjmap中添加下面这个转换映射项,来完成AvgPool2d到Pool的映射。
# Pytorch的函数名称
'AvgPool2d': {
'pytorch': {
'args': 'kernel_size, stride=None, padding=0, dilation=1, return_indices=False', # Pytorch的参数
},
'jittor': {
'module': 'nn', # 该函数在Jittor的哪个module
'name': 'Pool', # Jittor对应的函数名称
'args': 'kernel_size, stride=None, padding=0, dilation=None, return_indices=None, ceil_mode=False, op="maximum"' # Jittor参数
},
'links': {},
'extras': {
"op": "'mean'",
},
},
其中,extras中填写给某个参数赋值。因为Jittor的Pool默认op是maximum,如果不额外赋值为mean,上面的项是转的MaxPool2d。
除了extras,还有links和delete两个选项供大家使用。下面举例它们的用法。
links用于参数名称不一样,但是代表的含义一样的情况,可以使用links把参数对应起来。例如uniform_的参数名称不同的,但是含义相同,就可以按照下面的写法来写。
'uniform_': {
'pytorch': {
'args': "tensor, a=0.0, b=1.0",
},
'jittor': {
'module': 'init',
'name': 'uniform_',
'args': 'var, low, high'
},
'links': {'tensor': 'var', 'a': 'low', 'b': 'high'},
'extras': {},
},
delete用于删除一些参数,因为这些参数在Jittor中不再使用。例如ReLU中的inplace在Jittor中已不再使用,可以直接把它添加到delete中。
'ReLU': {
'pytorch': {
'args': 'inplace=False',
},
'jittor': {
'module': 'nn',
'name': 'ReLU',
'args': ''
},
'links': {},
'extras': {},
'delete': ['inplace'],
},
总结一下,需要将Pytorch和Jittor对应函数的名称和参数列表填入,如果需要用到下面三项可按功能使用。若函数名称、参数列表完全相同,即不需转换,便可不用增加转换映射项。
extras:用于给变量额外赋值links:用于将名称不一样但含义相同的参数对应起来delete:用于删除Jittor不再使用的参数
我们提供了接口pjmap_append用于添加转换映射项,函数参数如下:
pytorch_func_name: Pytorch函数名称pytorch_args: Pytorch参数列表jittor_func_module: Jittor函数属于哪个Modulejittor_func_name: Jittor函数名称jittor_args: Jittor参数列表extras: 参数赋值links: 连接参数delete: 删除参数
下面展示使用该接口将Pytorch的AvgPool2d是如何转换为Jittor的Pool。
from jittor.utils.pytorch_converter import pjmap_append
pjmap_append(pytorch_func_name='AvgPool2d',
pytorch_args='kernel_size, stride=None, padding=0, dilation=1, return_indices=False',
jittor_func_module='nn',
jittor_func_name='Pool',
jittor_args='kernel_size, stride=None, padding=0, dilation=None, return_indices=None, ceil_mode=False, op="maximum"',
extras={"op": "'mean'"})
第三部分 时间性能测试方法
首先,为了保证速度测试不受任何其他因素干扰,我们先定义一张bs,3,224,224的numpy图像,然后转换成torch.Tensor以及jittor.array,以此保证输入两个框架模型的矩阵相同。其次,Jittor加载Pytorch的初始化参数来保证参数完全相同,一来保证速度不受参数不同的影响,二来查看两个框架的输出是否一样来检查结果正确与否。
import torch
import jittor as jt
jt.flags.use_cuda = 1
# 定义numpy输入矩阵
bs = 32
test_img = np.random.random((bs,3,224,224)).astype('float32')
# 定义 pytorch & jittor 输入矩阵
pytorch_test_img = torch.Tensor(test_img).cuda()
jittor_test_img = jt.array(test_img)
# 跑turns次前向求平均值
turns = 100
# 定义 pytorch & jittor 的xxx模型,如vgg
pytorch_model = xxx().cuda()
jittor_model = xxx()
# 把模型都设置为eval来防止dropout层对输出结果的随机影响
pytorch_model.eval()
jittor_model.eval()
# jittor加载pytorch的初始化参数来保证参数完全相同
jittor_model.load_parameters(pytorch_model.state_dict())
下面是测试Pytorch前向传播的代码,在被测试代码pytorch_result = pytorch_model(pytorch_test_img)前后都执行torch.cuda.synchronize()来保证测得的时间是该测试代码的时间。
# 测试Pytorch一次前向传播的平均用时
for i in range(10):
pytorch_result = pytorch_model(pytorch_test_img) # Pytorch热身
torch.cuda.synchronize()
sta = time.time()
for i in range(turns):
pytorch_result = pytorch_model(pytorch_test_img)
torch.cuda.synchronize() # 只有运行了torch.cuda.synchronize()才会真正地运行,时间才是有效的,因此执行forward前后都要执行这句话
end = time.time()
tc_time = round((end - sta) / turns, 5) # 执行turns次的平均时间,输出时保留5位小数
tc_fps = round(bs * turns / (end - sta),0) # 计算FPS
print(f"- Pytorch {key} forward average time cost: {tc_time}, Batch Size: {bs}, FPS: {tc_fps}")
下面是测试Jittor前向传播的代码,在被测试代码jittor_result = jittor_model(jittor_test_img)前后都执行jt.sync_all(True)来保证测得的时间是该测试代码的时间。
# 测试Jittor一次前向传播的平均用时
for i in range(10):
jittor_result = jittor_model(jittor_test_img) # Jittor热身
jittor_result.sync()
jt.sync_all(True)
# sync_all(true)是把计算图发射到计算设备上,并且同步。只有运行了jt.sync_all(True)才会真正地运行,时间才是有效的,因此执行forward前后都要执行这句话
sta = time.time()
for i in range(turns):
jittor_result = jittor_model(jittor_test_img)
jittor_result.sync() # sync是把计算图发送到计算设备上
jt.sync_all(True)
end = time.time()
jt_time = round((time.time() - sta) / turns, 5) # 执行turns次的平均时间,输出时保留5位小数
jt_fps = round(bs * turns / (end - sta),0) # 计算FPS
print(f"- Jittor {key} forward average time cost: {jt_time}, Batch Size: {bs}, FPS: {jt_fps}")
同时我们使用Jittor与Pytorch输出结果的相对误差保证模型的正确性。
threshold = 1e-3
# 计算 pytorch & jittor 前向结果相对误差. 如果误差小于threshold,则测试通过.
x = pytorch_result.detach().cpu().numpy() + 1
y = jittor_result.numpy() + 1
relative_error = abs(x - y) / abs(y)
diff = relative_error.mean()
assert diff < threshold, f"[*] {yourmodelname} forward fails..., Relative Error: {diff}"
print(f"[*] {yourmodelname} forword passes with Relative Error {diff}")
第四部分 时间性能测试结果对比
介绍了这么多,终于到了惊心动魄的时刻!下面展示我们用第一部分介绍的转换脚本将torchvision.models里提供的AlexNet[1]、VGG[2]、ResNet[3]、SqueezeNet[4]、Wide ResNet[5]转换成Jittor的模型,并在不同的batch size下,Jittor与PyTorch的单次前向性能对比,图1中横轴为不同Batch size,纵轴为FPS(每秒处理的图像数)。实验环境为:GPU为1080ti,显存11GB,CPU为i7-6850K,内存32GB,使用32位浮点数计算。
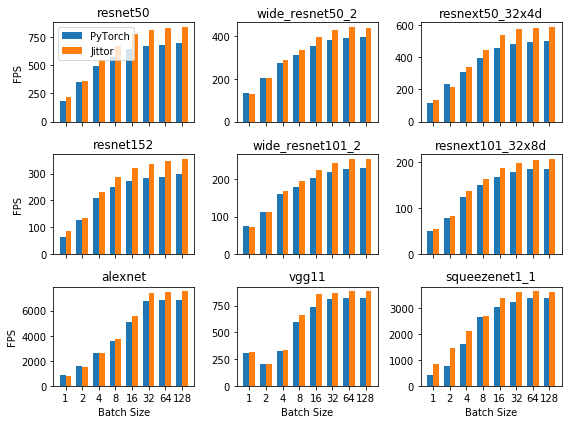
可以看出Jittor在这些常用骨干网络上的速度非常可观,大多数网络Jittor会有速度的提升。欢迎大家使用Jittor来加速自己的模型训练。
如果大家对时间测试或者测试结果有什么问题的话,欢迎在Github提Issue、或者通过Email:jittor@qq.com联系我们。
参考文献
- Krizhevsky, Alex. “One weird trick for parallelizing convolutional neural networks.” arXiv preprint arXiv:1404.5997 (2014).
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Iandola, Forrest N., et al. “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size.” arXiv preprint arXiv:1602.07360 (2016).
- Zagoruyko, Sergey, and Nikos Komodakis. “Wide residual networks.” arXiv preprint arXiv:1605.07146 (2016).