
第六届“计图”人工智能算法挑战赛启动
计图(Jittor)人工智能算法挑战赛是在国家自然科学基金委信息科学部指导下,由北京信息科学与技术国家研究中心和清华大学-腾讯互联网创新技术联合实验室于2021年创办、基于清华大学Jittor深度学习框架的人工智能算法大赛。
大赛面向所有在校学生和AI 相关领域从业人士开放,旨在通过竞技的方式提升人们对数据分析与处理的算法研究与技术应用的能力,推动我国自主人工智能平台的生态建设和人工智能研究和应用的深入。
挑战赛邀请人工智能领域的权威专家和相关领导参加指导委员会,并组建了包括高校、研究院所的学者和IT企业的学者和资深技术专家在内的专家委员会,负责挑战赛的评审。指导委员会和专家委员会的名单如下。
指导委员会 (按字母顺序):
1. 戴琼海,清华大学教授、中国工程院院士、中国人工智能学会理事长
2. 胡事民,清华大学教授、中国科学院院士、中国计算机学会副理事长
3. 刘 克,国家自然科学基金委信息科学部原常务副主任
4. 梅 宏,北京大学教授、中国科学院院士
5. 沈向洋,粤港澳大湾区数字经济研究院理事长、美国工程院外籍院士
6. 王怀民,国防科技大学教授、中国科学院院士
7. 吴国政,国家自然科学基金委信息科学部二处(计算机、人工智能)处长
8. 徐宗本,西安交通大学教授、中国科学院院士
9. 查红彬,北京大学教授
10. 张 钹,清华大学教授、中国科学院院士
11. 章 毅,四川大学教授
12. 周志华,南京大学教授、中国科学院院士
专家委员会(按字母顺序)
1. 白 翔,华中科技大学教授
2. 程明明,南开大学教授
3. 董未名,中科院自动化所研究员
4. 高 林,中科院计算所研究员
5. 郭延文,南京大学教授
6. 黄 华,北京师范大学教授
7. 李庆利,华东师范大学教授
8. 刘 偲,北京航空航天大学教授
9. 吕 琳,山东大学教授
10. 孟德宇,西安交通大学教授
11. 闵卫东,南昌大学教授
12. 童若锋,浙江大学教授
13. 王巨宏,腾讯公司技术委员会主任
14. 王志衡,国家自然科学基金委信息科学部二处(计算机、人工智能)副处长
15. 魏哲巍, 中国人民大学教授
16. 严骏驰,上海交通大学教授
17. 张 蕾,四川大学教授
18. 张松海,清华大学教授
19. 郑伟诗,中山大学教授
20. 左旺孟,哈尔滨工业大学教授
21. 周明辉, 北京大学教授
本届挑战赛设置两个热身赛(基于引用网络的论文分类任务和点云分类)和两个正式赛道(基于图学习的动态推荐任务和点云去噪任务),均要求使用计图深度学习框架完成。参赛团队需要通过至少一个热身赛才能参加两个正式赛道。
比赛报名和参赛的入口为:
https://www.educoder.net/competitions/Jittor-7
热身赛
热身赛的目的是帮助选手学习计图,并对参赛团队进行初筛,参赛团队需要通过至少一个热身赛才能参加两个正式赛道。
热身赛一:基于引用网络的论文分类任务
赛题介绍:该任务是在论文引用数据集 Cora 上训练图卷积网络(GCN)模型,用于对论文主题进行分类。在该数据集中,节点代表论文,边表示论文之间的引用关系,节点的属性为论文标题与摘要所对应的词袋(BoW)特征。组织方提供了示例代码,涵盖数据下载、模型定义、训练步骤等主要功能。
热身赛二:点云分类
赛题介绍:该任务是在经典的三维形状数据集 ModelNet40[1] 上训练点云分类模型,用于对三维点云所属类别进行预测分类。在该数据集中,每个样本由从物体网格表面均匀采样并归一化至单位球的2048 个三维点组成,涵盖了飞机、椅子、桌子等 40 个常见物体类别。组织方基于计图(Jittor)深度学习框架提供了点云 Transformer(PCT)[2] 方法作为 Baseline 的示例代码,涵盖数据下载与加载、模型定义、训练步骤和推理预测等主要功能。
赛道一:基于图学习的动态推荐任务
近年来,随着推荐系统、社交网络、交易网络等应用场景的快速发展,基于图学习的动态推荐任务逐渐成为研究热点。在这些场景中,用户与物品、作者、网页等实体之间的交互关系会随着时间不断演化,形成具有丰富时序信息的动态图结构。与传统静态推荐或静态图推荐不同,动态推荐任务不仅需要建模图结构,还需要刻画用户行为的演化过程以及潜在的时序模式。
本赛题聚焦于动态图上的未来交互预测问题。给定历史时序交互数据,模型需要学习节点表示及其演化规律,从而预测未来最有可能产生的新交互。该任务广泛应用于商品推荐、好友推荐、论文引用预测、网页跳转预测等实际场景,具有重要的研究价值与应用意义。近年来研究表明[3],常见动态图推荐数据集中存在较高比例的重复推荐,模型容易依赖历史连接记忆,而忽视对真实动态模式的建模。因此,如何提升模型对“未来新内容”的推荐能力,以及在动态环境下的泛化能力,成为该方向的重要挑战。
本赛题基于开源图学习框架JittorGeometric 进行设计,鼓励参赛者结合动态图神经网络、图 Transformer、序列建模等方法,对大规模动态交互数据进行高效建模,并完成未来链接预测任务。赛题将提供来自真实世界的推荐图数据,参赛者需基于历史交互序列进行表示学习,并对验证集和测试集中的候选连接进行排序或打分。官方提供基于JittorGeometric 实现的 CRAFT 方法作为Baseline[4]。
赛道二:基于深度学习的点云降噪任务
近年来,随着三维传感技术(如激光雷达、结构光扫描、深度相机等)的快速发展,点云数据已成为三维计算机视觉和图形学领域最重要的数据表示形式之一。然而,受限于传感器精度、环境干扰等因素,实际获取的点云往往包含大量偏离真实物体表面的噪声。与传统依赖手工设计几何先验的滤波方法不同,基于深度学习的点云降噪任务能够通过强大的数据驱动能力学习局部几何特征和噪声模式,从而更鲁棒地还原真实表面,逐渐成为该领域的研究热点。
本赛题聚焦于基于深度学习的点云降噪任务。给定从三维物体表面采样并受噪声污染的点云,模型需要预测每个点的位移向量,将含噪点“推回”到真实物体表面附近,输出降噪后的干净点云。该任务广泛应用于高质量三维重建、表面法向估计、自动驾驶与机器人感知以及文化遗产数字化等实际场景,具有重要的研究价值与应用意义。实际应用中,噪声分布的多样性、尖锐边缘等几何细节的保持,以及面对大规模点云时的计算可扩展性与泛化能力,成为了该方向的重要技术挑战。
本赛题基于计图(Jittor)[6]深度学习框架进行设计,鼓励参赛者结合强大的点云特征提取网络、注意力机制、多步迭代策略或基于分数匹配的扩散模型等方法,对含噪点云进行高效建模与降噪。赛题将提供基于常见三维物体(如ShapeNet)的大规模点云数据集,参赛者需预测位移向量以恢复真实几何表面。官方提供基于 Jittor 实现的 StraightPCF[5] 方法以及采用动态图卷积特征提取与MLP 解码器的位移预测架构作为 Baseline。
本届Jittor人工智能算法挑战赛4月9日启动,4月18日发布A榜评测数据集,7月15日报名截止,9月决赛答辩;具体时间安排如下。
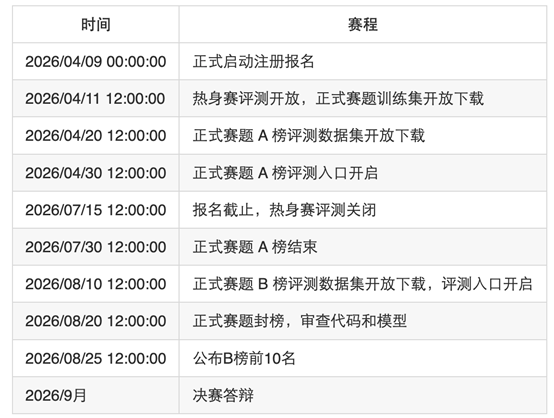
所有参赛选手都必须在头歌平台注册报名,参赛选手需确保注册时提交信息准确有效。
https://www.educoder.net/competitions/Jittor-7
参赛者在规定时间内须使用Jittor深度学习框架进行模型的设计、训练和预测。
为了帮助用户快速上手计图,Jittor团队联合头歌平台发布计图深度学习框架实践课程。本课程全面、系统地介绍了Jittor深度学习框架的基础模块、模型训练测试流程、基础网络结构编写、计算机视觉任务实现以及模型库的使用。学习本课程需要有一定的Python编程基础以及一定的深度学习基础。
Jittor深度学习框架实践课程的主页是:
https://www.educoder.net/paths/89rcg6jn
Jittor的教程和相关信息,详见Jittor官网、GitHub网页或Gitlink网页:
https://cg.cs.tsinghua.edu.cn/jittor/
https://github.com/Jittor/Jittor
https://www.gitlink.org.cn/Jittor/jittor
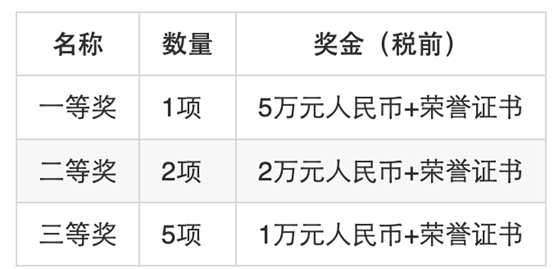
选手可2-3人组队或单人成队参赛,每位选手只能加入一支队伍,报名截止日期之后不允许更改队员。本次竞赛的奖金共28万,两个赛题分别评审,每个赛题的奖项如下。
获得两个赛道第一名的团队,将应邀将创新的模型和算法成果,撰文在Computational Visual Media(IEEE)以short communication的形式发表。CVMJ的影响因子为18.3,在Web of Science的计算机-软件工程的132个期刊中排名第一。
比赛成绩优秀者,还可以获得腾讯校园招聘(包括实习)的绿色通道或其他便利,可提升简历曝光度及面试发起率。
挑战赛的评奖以B榜成绩为准。竞赛组委会对排在B榜前列队伍进行模型和代码审核,要求在Jittor平台上,复现榜单最优成绩;遴选通过审核的每个赛道前10名参赛队伍进入决赛答辩。
大赛还设赛事交流QQ群:717152103,提供在线学习讨论。敬请关注!
欢迎在校学生和AI相关领域从业人士注册参赛!
参考文献
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, Jianxiong Xiao, 3D ShapeNets: A deep representation for volumetric shapes. CVPR 2015: 1912-1920
Meng-Hao Guo, Junxiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin, Shi-Min Hu, PCT: Point cloud transformer. Computational Visual Media, 2021, 7(2): 187-199.
Farimah Poursafaei, Shenyang Huang, Kellin Pelrine, Reihaneh Rabbany, Towards better evaluation for dynamic link prediction, Advances in Neural Information Processing Systems (NeurIPS), 2022, 32928-32941.
Yi Lu, Runlin Lei, Fengran Mo, Yanping Zheng, Zhewei Wei, and Yuhang Ye, Future Link Prediction Without Memory or Aggregation, Advances in Neural Information Processing Systems (NeurIPS), 2025.
Dasith de Silva Edirimuni, Xuequan Lu, Gang Li, Lei Wei, Antonio Robles-Kelly, Hongdong Li, StraightPCF: Straight Point Cloud Filtering, CVPR 2024, 20721-20730.
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, Wen-Yang Zhou, Jittor: a novel deep learning framework with meta-operators and unified graph execution, Science China Information Sciences 2020, 63(12), 222103.
Computational Visual Media第12卷第2期导读 计图开源:首个国产多模态视觉感知代码库DFormer-Jittor Computational Visual Media第12卷第1期导读 ICLR 2026 | 下载破35万!清华&腾讯发布MLLMs全栈套件Bee:含首个大规模多模态推理数据集 视频大模型离“人类水平”还有多远?Video-Bench:构建三层级类人能力评估体系 | CVMJ Spotlight
可通过下方二维码,关注清华大学图形学实验室,了解图形学、人工智能、深度学习框架、CVMJ期刊和CVM会议的相关资讯。
