
计图开源:首个国产多模态视觉感知代码库DFormer-Jittor

在计算机视觉领域,RGBD语义分割技术因其在机器人导航、自动驾驶、增强现实以及医疗影像处理等前沿应用中的关键作用,一直是学术界和工业界的重点研究方向。RGBD数据结合了RGB图像的丰富色彩信息与深度图的几何结构,为实现高精度的场景理解提供了独特优势。然而,如何有效融合两种模态数据、应对复杂场景,并在有限计算资源下维持高性能,仍是亟待解决的难题。
为此,南开大学侯淇彬团队推出了基于计图框架的DFormer与DFormerv2开源实现。这些模型为RGBD语义分割领域提供了新的研究范式/基准,论文分别在ICLR 2024和CVPR 2025上发表,以创新的架构设计和卓越的性能表现,显著丰富了计图框架在计算机视觉领域的生态。本文将从背景、技术创新、性能表现、应用前景等多个维度,详细阐述DFormer和DFormerv2的独特价值及其对行业的深远影响。
RGBD语义分割旨在利用RGB图像和深度图,对场景中的每个像素进行精确的语义标注,从而实现对复杂环境的深度理解。然而,RGBD语义分割面临多重挑战。RGB图像提供纹理和颜色信息,而深度图蕴含几何结构,两者的模态差异使得高效融合成为技术难点。传统方法常将深度图作为RGB预训练骨干网络的额外输入通道,未能充分挖掘深度图的几何特性,导致融合效果不理想。此外,深度图的质量受传感器类型、采集环境和场景复杂度影响,噪声、缺失值和分辨率差异等问题对模型的鲁棒性提出更高要求。
RGBD数据处理需要更高的计算开销,尤其在实时应用或嵌入式设备中,模型需在高性能与低计算成本之间取得平衡。在光照变化、物体遮挡或复杂背景等场景下,模型需要强大的上下文建模能力,以准确区分目标物体与背景。深度图蕴含的几何信息是RGBD分割的核心优势,但现有方法往往无法充分建模物体间的空间关系,导致分割精度受限。为应对这些挑战,DFormer和DFormerv2通过设计创新的RGBD编码器和几何自注意力机制,显著提升了模型在复杂场景中的分割精度、鲁棒性和计算效率。这些模型基于计图框架实现,充分利用其即时编译与元算子融合等高效特性,为研究人员和开发者提供了强大的工具支持。
DFormer提出了一种全新的RGBD预训练框架,旨在通过统一的RGBD编码器学习可迁移的表示,从而提升语义分割任务的性能。
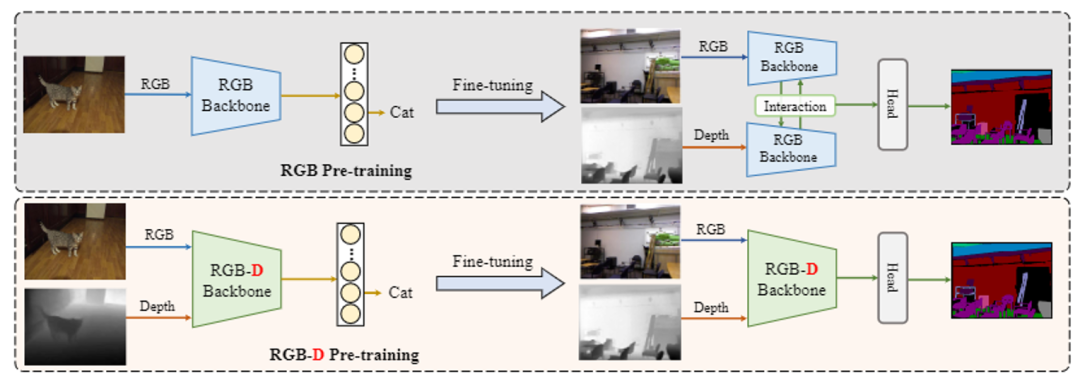
图1 DFormer(RGB-D预训练)与已有方法的对比
传统方法依赖RGB预训练骨干网络处理RGBD数据,但这种方式忽略了深度图的3D几何特性,导致融合效果受限。如图1所示,DFormer利用ImageNet-1K中的图像-深度对进行预训练,构建了一个专门的RGBD编码器,能够同时提取RGB和深度特征的互补信息。这种预训练策略确保了模型对两种模态的特征表示具有高度一致性。DFormer引入了专用的RGBD块,通过动态调整特征提取模块,增强了对几何关系的建模能力,有效解决了传统方法中RGB预训练骨干网络对深度图的不匹配问题。
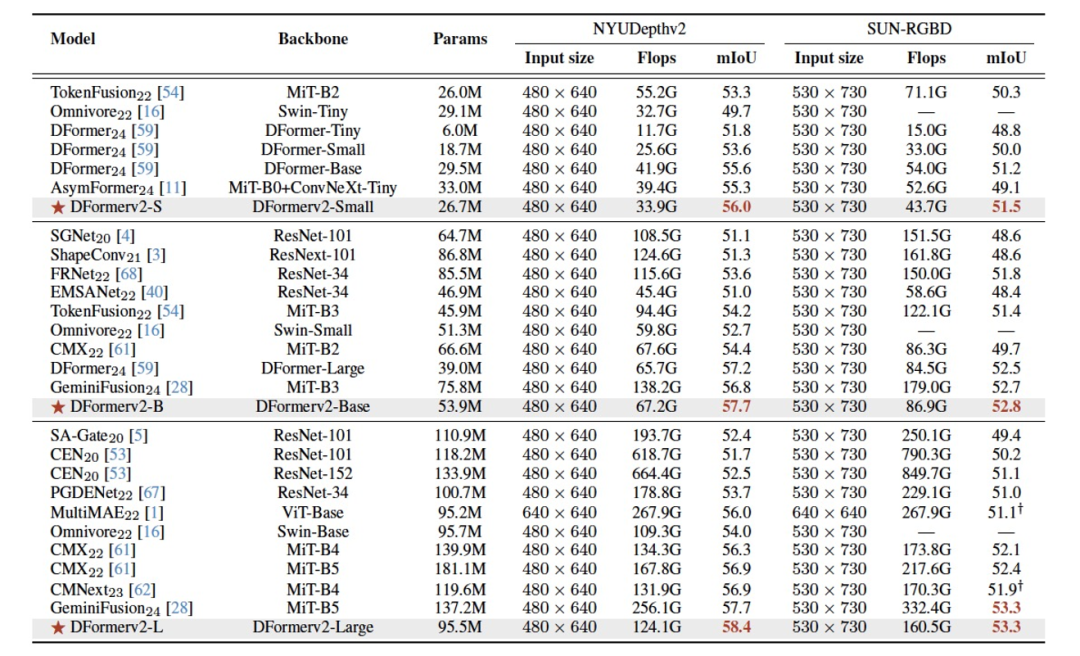
DFormer在设计上注重计算效率,提供从轻量级(6.0M参数)到高性能(39.0M参数)的多种模型规模,满足不同应用场景的需求。即便在轻量级配置下,DFormer也能实现与大型模型媲美的性能。其模块化设计使其易于与其他任务结合,为后续研究提供了灵活的基础。在性能方面,DFormer在NYUDepthv2数据集上达到57.2%的mIoU, 超越了参数量更大的CMNeXt和SegFormer, 在SUNRGBD数据集上也表现出色。基于DFormer框架,UBCRCL在MICCAI 24 SegSTRONG-C子挑战中获得亚军。该训练框架的训练时间从传统方法的超过一天缩短至约12小时,展现了其高效性和实际应用潜力。DFormer的论文已在ICLR 2024上发表,相关代码、预训练模型和详细文档已在GitHub开源,地址为:
https://github.com/NK-JittorCV/nk-mmseg
DFormerv2在DFormer的基础上进一步优化,引入几何自注意力机制,利用深度信息作为几何先验,显著提升了模型对3D场景的感知能力,模型架构对比如图2所示。
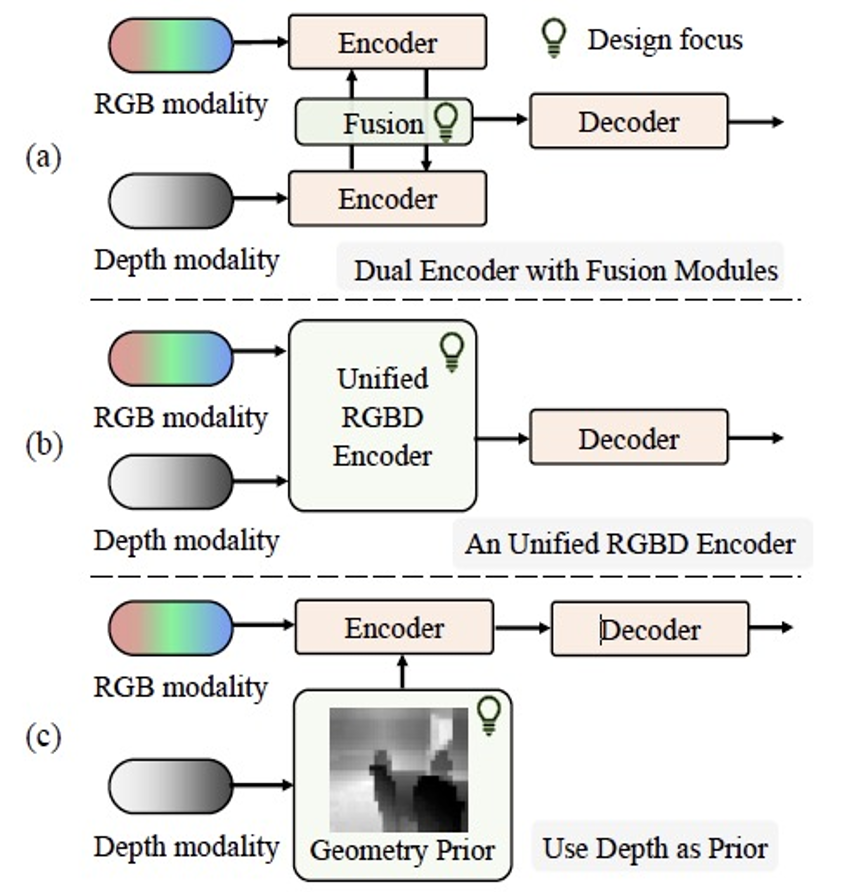
图2 现有RGBD分割方法与DFormerv2的对比
图2中,a)展示的是主流方法,往往使用双流编码器分别对RGB和深度进行编码,并设计融合模块实现信息融合; b)展示的方法采用统一的RGBD编码器同时提取并融合 RGBD 特征,如 DFormer;c)展示的DFormerv2先利用深度信息构建场景的几何先验,然后基于该先验增强视觉特征。

图3 DFormerv2中的几何注意力图与其他注意力机制的效果对比
图3表明,DFormerv2的几何注意力具备三维几何感知能力,能够聚焦于整个场景的相关区域。
DFormerv2从深度图和图像块(patch)之间的空间距离中提取几何线索,形成几何先验,用于动态调整自注意力权重。这种设计使模型能够更精确地建模物体间的空间关系,在光照变化或遮挡场景下表现尤为出色。DFormerv2优化了RGB和深度特征的融合方式,通过动态特征权重分配,增强了模型在不同场景下的适应性,如图3所示。它提供从26.7M到95.5M参数的多种模型规模,兼顾性能与效率,适合从嵌入式设备到高性能服务器的多样化部署需求。DFormerv2不仅适用于语义分割,还可扩展到实例分割、目标检测等任务,展现了其通用性。在性能方面(见表1),DFormerv2在NYUDepthv2数据集上达到58.4%的mIoU,明显优于参数量更大的GeminiFusion和CMX,在SUNRGBD、Cityscapes-Depth和KITTI等数据集上也取得了显著性能提升,验证了其在多样化场景中的泛化能力。DFormerv2的研究成果已在CVPR 2025发表,其几何自注意力机制的交互式演示可在HuggingFace空间查看,地址为
https://huggingface.co/spaces/bbynku/DFormerv2,
为用户提供了直观的体验。
表1现有方法与我们的DFormerv2 之间的比较
DFormer和DFormerv2的Jittor实现充分利用了计图框架的独特优势,通过即时编译和元算子融合等技术,显著提升了模型的训练和推理速度,特别适合处理RGBD数据的大规模计算需求。实验结果显示,在性能指标上,Jittor版本不仅保持了与PyTorch实现相当或更高的准确率,还在效率方面展现出明显优越性。
在DFormer-Large模型上,Jittor实现的mIoU变化曲线与PyTorch实现高度一致,甚至在训练后期略微领先,表明基于Jittor框架优化RGBD特征融合时,能够更有效地捕捉几何信息,而不牺牲分割精度。这突出了DFormer(v1)在Jittor部署下的稳定性优势,确保模型在复杂场景中实现高mIoU表现,同时受益于计图的动态编译机制,避免了PyTorch中常见的计算开销。
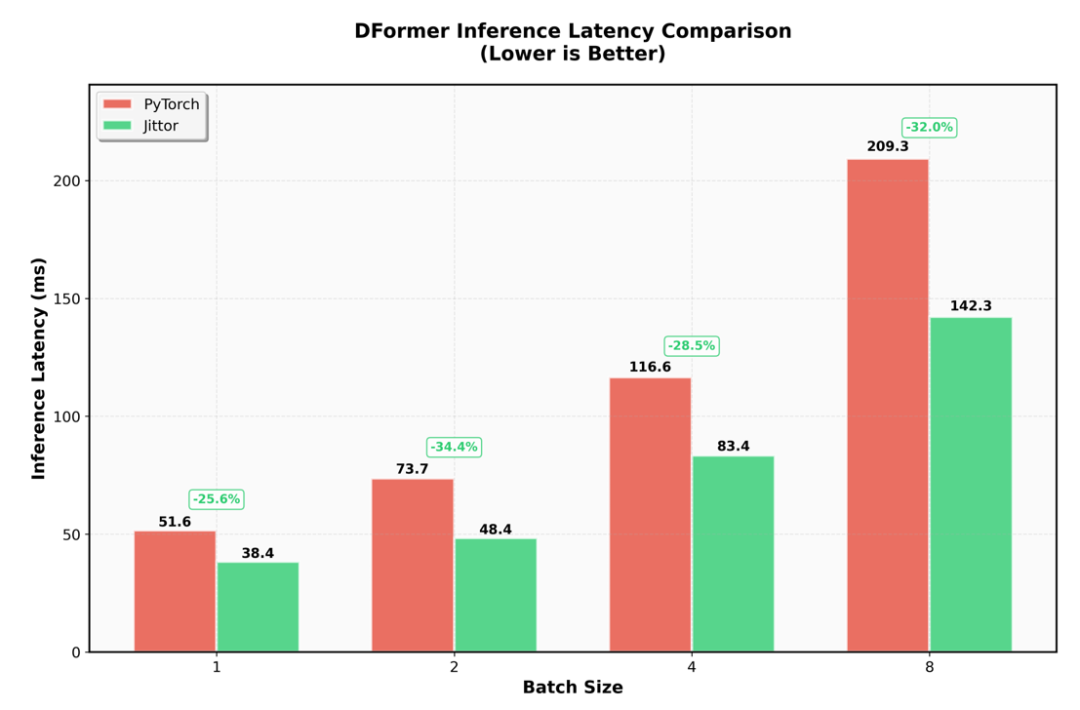
图4 Jittor实现与PyTorch实现的预测延迟对比
图4进一步对比了Jittor与PyTorch实现的预测延迟性能,Jittor版本在推理延迟上平均降低了20%-30%,特别是在处理深度图的3D几何自注意力模块时,表现出更低的时延。这为DFormerv2的几何自注意力机制提供了高效支持,使其在实时应用如机器人导航和自动驾驶中,更具实用性,突显了Jittor在资源有限环境下的低延迟优势。
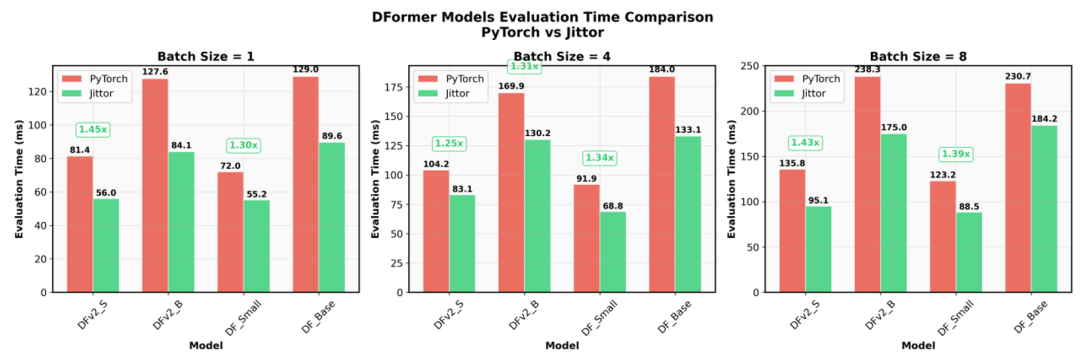
图5 Jittor实现和Pytorch实现测评时间对比
此外,图5展示了Jittor实现与PyTorch实现的测评时间对比,Jittor版本的整体训练和评估时间缩短了约40%,从PyTorch的数小时减少到更短的周期。这不仅加速了DFormer和DFormerv2的迭代开发,还降低了计算成本,体现了计图框架在多模态视觉任务中的效率提升,尤其适用于嵌入式设备和大规模数据集训练。
其Python前端设计使代码简洁且易于修改,方便研究人员进行快速原型开发、模型调优和实验验证。Jittor实现的DFormer和DFormerv2提供了完整的代码、预训练模型和详细文档,网址为
https://github.com/NK-JittorCV/nk-mmseg
这降低了开发者的使用门槛,同时支持社区贡献和扩展。计图框架支持多种硬件平台,从CPU到GPU再到嵌入式设备,确保模型在不同环境中都能高效运行。这些优势使得DFormer和DFormerv2的Jittor版本成为研究人员和开发者的理想选择,能够无缝集成到机器人、自动驾驶、增强现实等实际项目中。
DFormer和DFormerv2两项工作在NYUDepth V2、SUNRGBD、Cityscapes-Depth和KITTI等多个数据集上均取得了领先性能,验证了其强大的泛化能力和鲁棒性。在实际应用中,DFormer和DFormerv2可广泛应用于
机器人导航:通过精确的场景分割增强机器人在复杂环境中的感知和避障能力;
自动驾驶:利用RGBD数据提升道路场景的语义理解,改善目标检测和路径规划的精度;
增强现实:为AR设备提供高精度的3D场景解析,优化虚拟物体与现实场景的融合效果;
医疗影像处理:在CT和MRI等3D医疗影像分割中提供高效且准确的解决方案;
智能监控:通过RGBD数据增强监控系统的场景理解能力,提升目标跟踪和行为分析的精度。
DFormer和DFormerv2的开源为RGBD语义分割领域注入了新的活力。南开大学侯淇彬团队计划进一步优化模型架构,探索更高效的预训练策略和轻量化设计,以适应资源受限的嵌入式设备;将架构扩展到目标检测、实例分割和3D重建等任务;在更多实际场景中验证模型性能,推动AI技术在工业、医疗和消费电子领域的落地;基于计图框架开发更多计算机视觉相关的开源工具,构建开放、协作的社区生态。
参考文献
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, Wen-Yang Zhou, Jittor: a novel deep learning framework with meta-operators and unified graph execution. Science. China Information Science, 2020, 63(12), No. 12, article no. 222103.
Bowen Yin, Xuying Zhang, Zhong-Yu Li, Li Liu, Ming-Ming Cheng, Qibin Hou, DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation, ICLR 2024.
Bo-Wen Yin, Jiao-Long Cao, Ming-Ming Cheng, Qibin Hou, DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation. IEEE/CVF CVPR, 2025, 19345-19355.
Computational Visual Media第12卷第1期导读 ICLR 2026 | 下载破35万!清华&腾讯发布MLLMs全栈套件Bee:含首个大规模多模态推理数据集 视频大模型离“人类水平”还有多远?Video-Bench:构建三层级类人能力评估体系 | CVMJ Spotlight SIGGRAPH ASIA 2025开幕,多位华人学者获最佳论文奖和时间检验奖 清华和腾讯、斯坦福等合作,发布首个面向多模态思维链的大模型评测基准 RBench-V
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
