
计图开源:基于跨图块感知的交互式遥感图像分割方法
近期,清华大学计图团队与南开大学合作提出了一种基于跨图块感知的交互式遥感图像分割方法CrossCut[1]。该方法通过跨图块提示嵌入驱动及多尺度划分融合策略,有效解决了高分辨率遥感图像中大尺度目标与稀疏细节难以兼顾的难题,并突破了传统方法中图块间信息相互孤立的局限。在推理阶段,该方法支持用户点击信息在全局范围内传播,使得所有图块能够同步感知上下文并协同分割,从而实现对道路、建筑物等复杂目标的无缝提取。该论文已被AAAI 2026录用(Oral),基于计图框架的代码已开源。该论文的口头报告将于1.25日上午9:30-10:30于新加坡EXPO Garnet 213举行,欢迎大家参加!
交互式分割技术[2]旨在利用用户少量的正负点击交互来提取目标,是计算机视觉与图形学领域的重要研究问题之一。目前,交互式分割技术在自然图像处理上已较为成熟,但受限于遥感图像的特殊性,直接迁移现有方法往往难以获得满意的效果。
近年来,随着卫星传感器技术的发展,高分辨率遥感图像的数据量呈爆炸式增长。这类图像具有幅面巨大、目标分布稀疏以及尺度变化剧烈等显著特征。如图1所示,为处理这些图像,现有的主流策略通常是如(a)中在大幅下采样的整图上进行交互或者如(b)中将大图裁剪为多个小图块进行交互。然而,这两种策略在交互式分割任务中均存在致命缺陷:下采样会导致细粒度目标(如狭窄道路、小型车辆)的几何细节彻底丢失;而基于独立图块的处理方式交互量较大,且切断了上下文联系,导致跨越多个图块的大型目标(如河流、桥梁)难以被整体分割。为了解决上述问题,如(c)所示,研究团队合作提出了CrossCut,一种基于跨图块感知(CPA)的交互式遥感图像分割方法。该方法在保留高分辨率细节的同时,打破了图块间的边界限制,实现了点击信息在全局范围内的有效传播与利用。
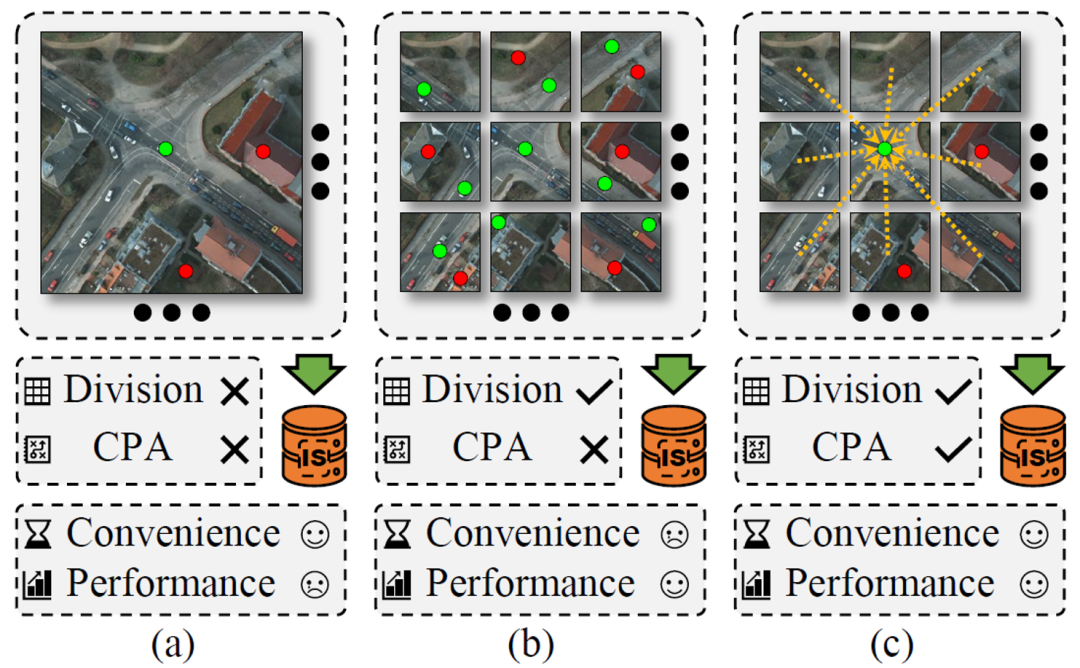
图1 CrossCut方法与其他方法的对比图
该方法将大尺度的遥感图像分割任务重构为一个跨图块协同感知的过程。CrossCut 框架打破了传统方法中图块独立处理的限制,通过显式传播全局信息来引导局部的分割。整个方法包含两个核心模块:首先是在特征提取阶段引入了跨图块提示嵌入模块(CPE),用于解决图块间的信息孤立问题;其次是针对推理阶段设计的多尺度划分融合模块(MDF)。方法的整体框架图如图2所示。
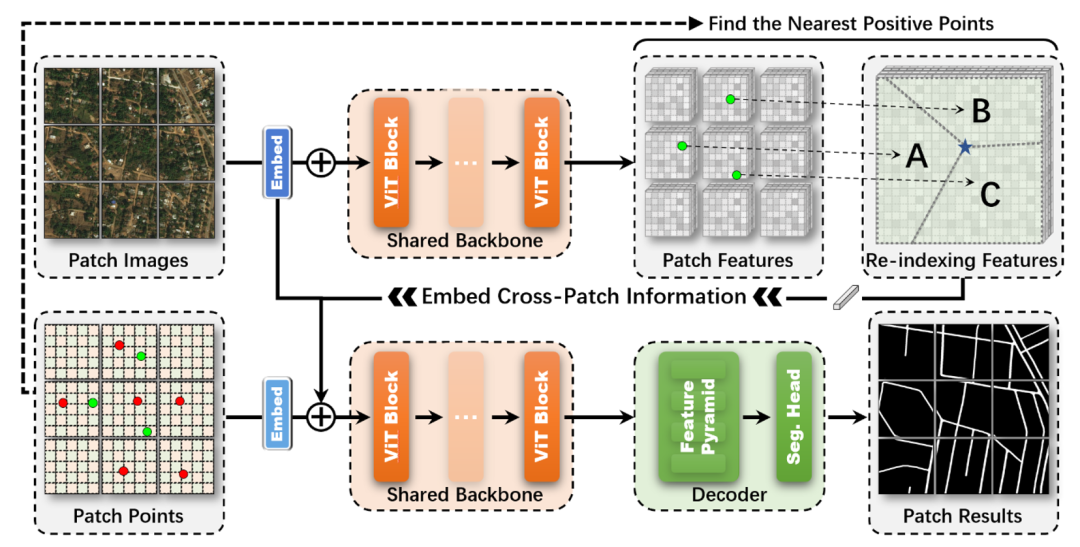
图2 CrossCut 交互式分割框架示意图
2.1跨图块提示嵌入模块(CPE)
为了解决先前方法中图块间信息孤立的难题,该方法提出了跨图块提示嵌入。跨图块提示嵌入充当了全局信息传播器的角色,它能够提取正点击周围的语义特征,并将这些引导信息传播到所有图块中,从而实现全图范围内的协同分割。整个流程包含以下三个关键步骤:
点击特征提取策略:为了增强模型对用户误触或空间模糊的鲁棒性,CPE 放弃了单像素点的硬编码方式,转而采用软空间选择策略。具体而言,对于每一个正点击,算法生成一个圆盘状的掩码,并在该区域内对重建的全局特征图进行平均池化,从而获得更具代表性的局部特征向量。
基于Voronoi图的全局传播:为实现稀疏点击信息向图像全域的传播,CPE构建了一个最近邻索引图。该策略依据欧氏距离将图像划分为多个Voronoi状区域,将图像中的每一个像素指派给距离其最近的正点击。基于此索引图,构建重索引特征图,使得全图任意位置都能感知到与其最相关的点击特征。
提示生成与注入:重索引特征图经过多层感知机编码后生成全局提示嵌入。该提示随后被调整至输入图块对应的特征尺寸,并以残差形式注入到每个图块的特征提取过程。
2.2多尺度划分融合模块(MDF)
多尺度划分融合模块主要用于解决遥感图像中目标尺度变化剧烈的问题。与传统固定网格切分的推理不同,该模块允许在推理阶段动态调整图块的配置。在推理过程中,首先定义不同的图块划分策略(例如不同的重叠率和裁剪尺寸)。对于每一个像素点,它可能被包含在多个不同视角的图块预测中。该模块汇集来自不同配置下的预测概率图,通过加权融合策略得到最终结果。通过这种方式,CrossCut能够综合利用局部细节和较大感受野的信息,显著提升了对大尺度目标的分割完整性。
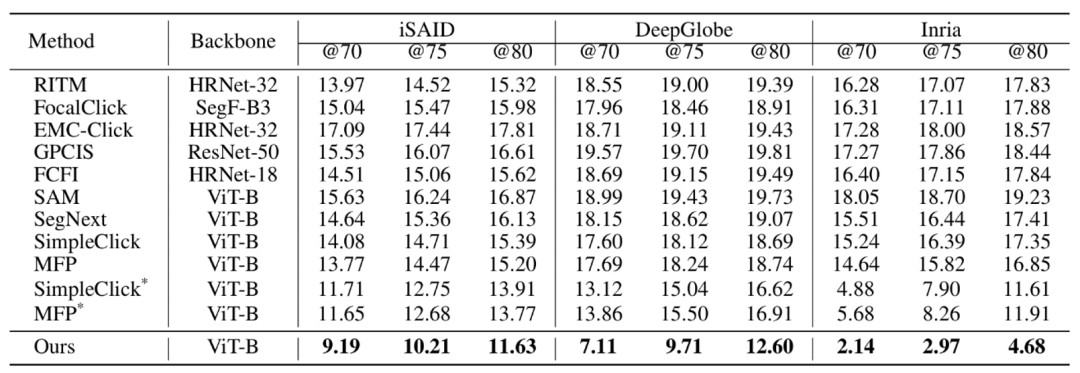
实验结果表明,CrossCut 在DeepGlobe[3](道路)、iSAID[4](实例)、Inria[5](建筑物)等具有挑战性的遥感数据集上均显著优于现有算法(表1、图3)。
在Inria与DeepGlobe数据集上,CrossCut 的交互效率展现出压倒性优势。特别是在建筑物密集分布的Inria数据集上,为达到80%的IoU,CrossCut仅需4.68 次点击,相较于当前最先进的方法(SimpleClick [6] 需要11.61次, MFP[7] 需要11.91次)交互成本降低了60%以上。
表1 CrossCut在多个数据集上与其他算法的对比
此外,论文对交互效率曲线进行了可视化分析(图3):在极少点击的情况下,CrossCut的 mIoU-NoC 曲线斜率显著高于其他基线(如SAM [8])。这说明跨图块提示嵌入(CPE)模块确实让模型学会了在全局范围内理解用户的点击意图,成功打破了图块间的信息孤立,而不仅仅是拟合局部的像素分布。
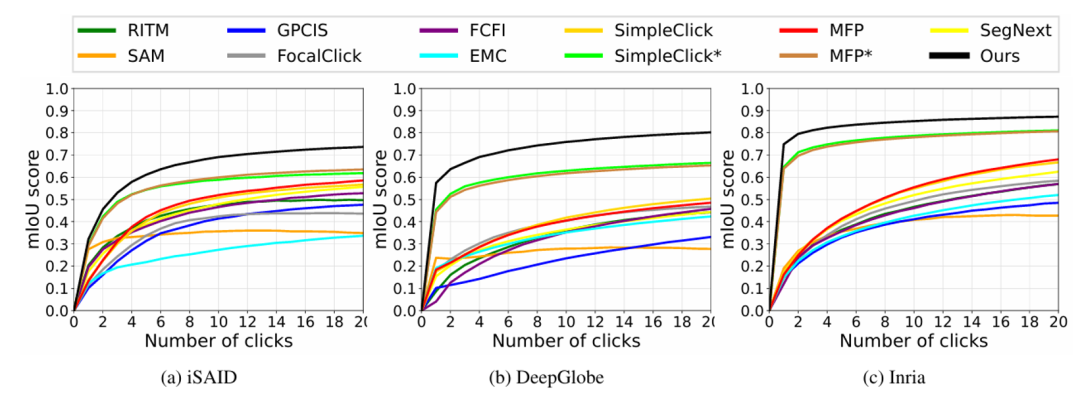
图3 mIoU-NoC 性能曲线对比图
由可视化结果图(图4)可知,CrossCut 拥有较强的泛化能力:无论是细长且连续的道路,还是离散分布的飞行器,模型均能准确捕捉。得益于多尺度划分融合策略,CrossCut 能够同时利用 2x2、3x3 等不同切分策略下的上下文信息,在复杂几何条件下依然能保持边界的锐利与完整。
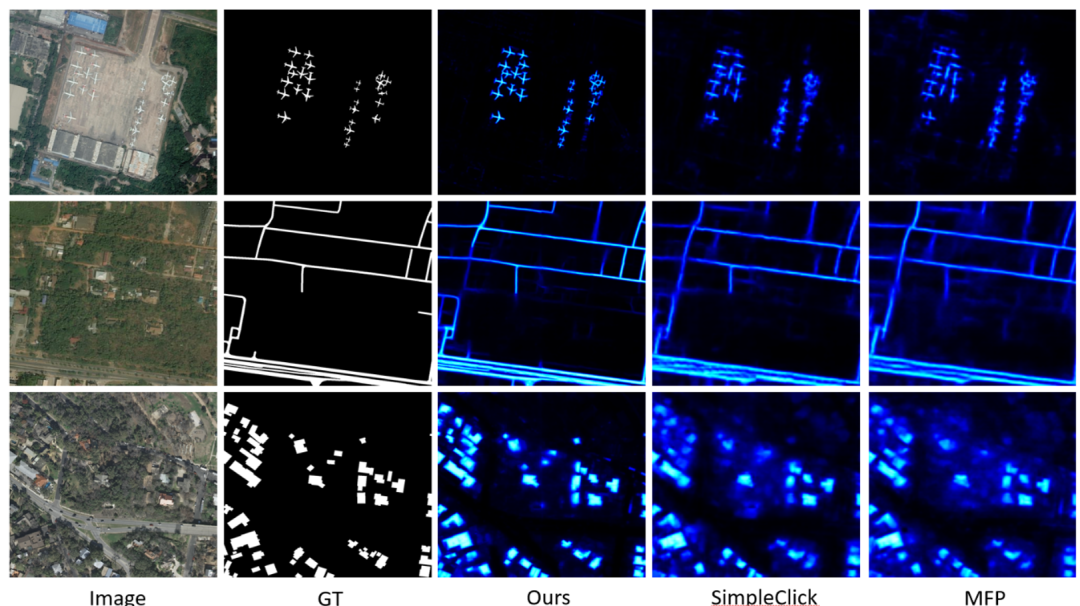
图4 不同数据集下5次点击生成结果的可视化图
该项目的计图代码已在Github上开源:
https://github.com/nanzhou02/CrossCut
计图(Jittor)是清华大学开源的自主深度学习框架[9],完全基于动态编译,采用元算子融合和统一计算图的新技术,并支持国产硬件。元算子易于使用,便于算子的开发和优化,而统一计算图则是融合了静态计算图和动态计算图的诸多优点,在易于使用的同时提供高性能的优化。计图官网为:
https://cg.cs.tsinghua.edu.cn/jittor/
引用文献
Zheng Lin, Nan Zhou, Yuhan Wang, Bojian Zhang. CrossCut: Cross-Patch Aware Interactive Segmentation for Remote Sensing Images. AAAI, 2026.
Hiba Ramadan, Chaymae Lachqar, Hamid Tairi. A Survey of Recent Interactive Image Segmentation Methods. CVMJ, 2020.
Ilke Demir, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, Ramesh Raskar. DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images. CVPR, 2018.
Syed Waqas Zamir, Aditya Arora, Akshita Gupta, Salman Khan, Guolei Sun, Fahad Shahbaz Khan, Fan Zhu, Ling Shao, Gui-Song Xia, Xiang Bai. iSAID: A Large-Scale Dataset for Instance Segmentation in Aerial Images. CVPR, 2019.
Emmanuel Maggiori, Yuliya Tarabalka, Guillaume Charpiat, Pierre Alliez. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. IGARSS, 2017.
Qin Liu, Zhenlin Xu, Gedas Bertasius, Marc Niethammer. SimpleClick: Interactive Image Segmentation with Simple Vision Transformers. ICCV, 2023.
Chaewon Lee, Seon-Ho Lee, Chang-Su Kim. Mfp: Making Full Use of Probability Maps for Interactive Image Segmentation. CVPR, 2024.
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. Segment Anything. ICCV, 2023.
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, and Wen-Yang Zhou. Jittor: A Novel Deep Learning Framework with Meta-Operators and Unified Graph Execution. Science China Information Science, 2020.
视频大模型离“人类水平”还有多远?Video-Bench:构建三层级类人能力评估体系 | CVMJ Spotlight Computational Visual Media第11卷第6期导读 SIGGRAPH ASIA 2025开幕,多位华人学者获最佳论文奖和时间检验奖 三维场景高保真实时重建 | CVMJ Spotlight 清华和腾讯混元、斯坦福等合作,发布首个面向多模态思维链的大模型评测基准 RBench-V
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
