
清华和腾讯混元、斯坦福等合作,发布首个面向多模态思维链的大模型评测基准 RBench-V
清华大学计图团队联合腾讯混元、斯坦福大学及卡内基梅隆大学等单位在NeurIPS 2025的DB Track上发表论文,推出 RBench-V[1],这是首个专注于视觉推理能力的大模型评测基准。该工作旨在揭示现有多模态大模型在视觉推理上存在的不足,构建了一套系统化的评测框架,以量化衡量模型的多模态思维链与推理能力,并推动多模态智能模型在理解、推理与决策层面的持续演进与优化。
尽管大模型的智能水平在语言理解与生成方面实现了飞跃,但人类智能的核心并不仅仅体现在语言思考上,更体现在跨模态推理与可视化思维的能力上。例如,我们在思考数学几何、物理运动、空间结构时,往往需要“画图”“标注”“想象场景”,形成贯穿视觉与语言交错思维链(Interleaved Visual-Textual Chain of Thought)。
然而,当前多数多模态大模型(Multimodal Large Language Models, MLLMs)仍主要停留在“视觉输入 + 语言输出”的范式:虽然能看图、说话,却无法以视觉的形式持续思考与表达。当模型面对需要画出辅助线、标记物体关系、展示空间轨迹的任务时,大模型往往陷入困境。这种能力缺失,使得模型在几何推理、空间理解、物理想象等核心智能环节上表现脆弱。如图1 所示,示例为‘连点成画’小游戏:参与者需根据点的编号顺序依次连接这些点,绘制出一幅草图,并判断该草图所呈现的图案。即使是目前多模态能力出众的 GPT-4o 模型也无法完成连点成画的小游戏,体现出了目前多模态大模型在视觉推理方面的不足。

图1 多模态大模型与人类在视觉推理任务上的对比
基于此挑战,清华大学、腾讯、斯坦福大学等团队联合提出 RBench-V,首个系统评测模型多模态思维链能力的基准。它不仅关注模型能否理解图像,更考察模型能否在思维链中生成视觉输出、显式展示推理过程。
综上,RBench-V 的意义在于:
从“语言推理”迈向“视觉推理”,弥补多模态智能在“输出侧”的缺环,让AI 不仅能“看图说话”,更能“画图思考”;
量化模型的可视化思考能力,为多模态思维链(M-CoT)研究提供标准化评测框架;
促进人机协同的认知进化,使模型在设计、教育、科学计算等领域具备更高层次的空间与视觉推理能力。
在这一意义上,RBench-V 不只是一个新的评测基准,更是一次paradigm shift,它让我们重新思考:下一代智能,是否应像人类一样,用视觉去推理,去记忆,去思考?
在构建 RBench-V 的过程中,最大的挑战在于如何设计并筛选题目,使其能够真实地评估模型在视觉推理过程中生成多模态输出的能力。如图2所示,RBench-V 中的题目不仅要求模型输出文本答案,还需要模型能够生成超越文本的输出形式,如绘制几何图形(右上示例)或在迷宫中描绘路径(右下示例)。图2中所示的红线并非原题的一部分,而是代表在RBench-V中解决问题时(例如绘制几何图形或在迷宫中描绘路径)的多模态推理过程。
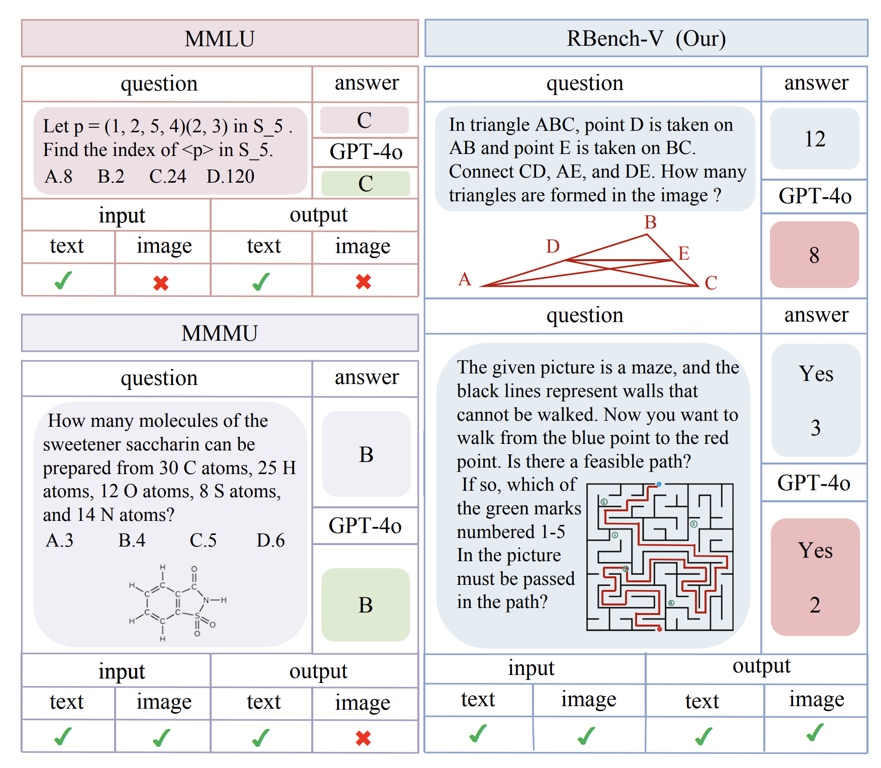
图2 RBench-V数据展示及与MMMU,MMLU的对比
为了建立 RBench-V,我们在题目设计与筛选时遵循一个核心原则:题目的解答过程必须涉及视觉内容的生成或编辑,例如在解题过程中绘制新的图像,或对已有图像进行修改。这样的设计理念来源于大量真实世界的场景,例如GUI 操作、图形绘制、路径规划等,这些任务都依赖于视觉推理过程中的多模态输出。
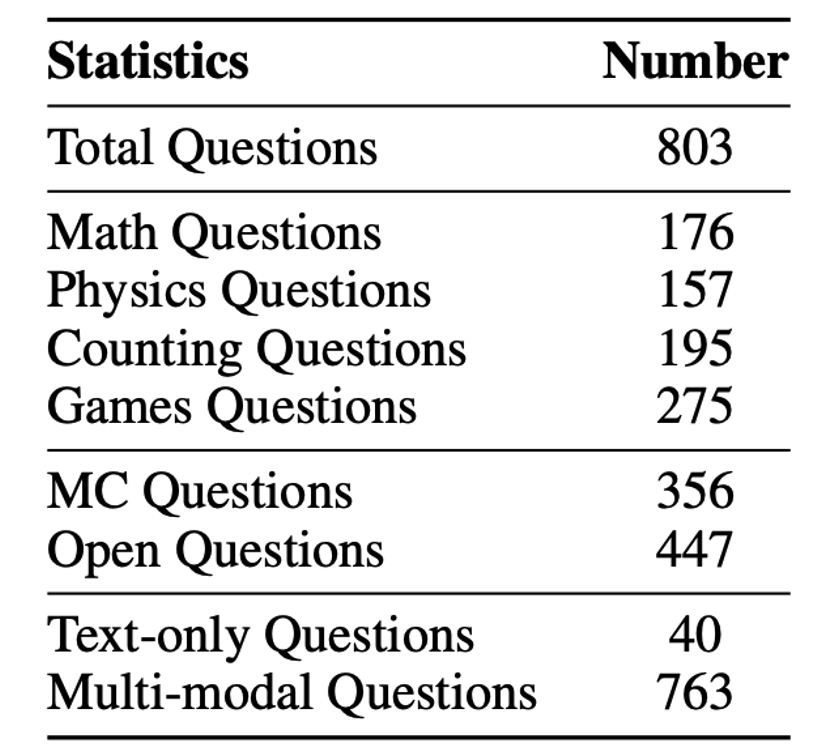
在本研究中,RBench-V 主要聚焦于数学、物理、计数与游戏四大领域。为确保题目的高质量与学术性,我们在数学与物理部分与相关领域专家合作进行命题与审核;对于计数与游戏类题目,则制定了严格的标准,用以指导题目的生成、筛选与质量控制,RBench-V中的数据统计如表 1 所示。
表1:RBench-V 中的数据统计
我们对多种开源与闭源多模态大语言模型(MLLMs)进行了全面评测,包括:
- 开源模型:如 Qwen2.5-VL,InternVL-3,DeepSeek-VL2 等;
- 闭源模型:如 GPT-4o、Gemini 2.5 Pro、OpenAI o3等;
同时,我们也邀请人类专家来完成 RBench-V 的题目,以比较目前模型和人类专家之间的差距,实验结果如图3和表2所示。从图3可以看出,在视觉推理方面,大模型与人类专家之间仍然存在显著差距。
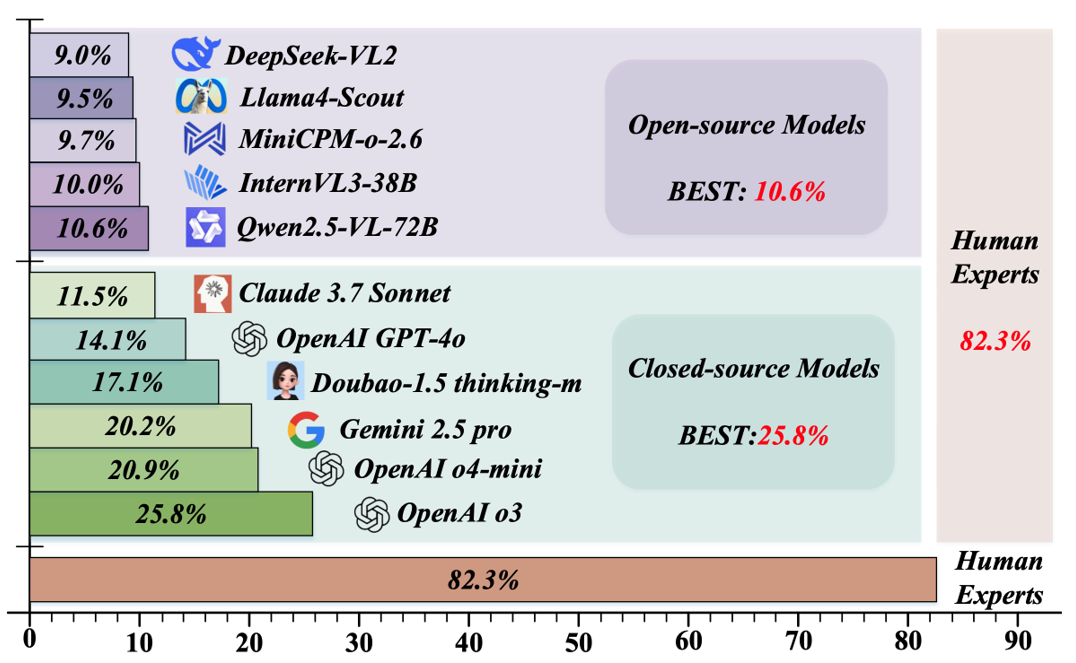
图3 开源模型、闭源模型和人类专家的比较
表2给出国内外主流的开源和闭源大模型在 RBench-V 上的评测结果。
表2 不同开源闭源模型在 RBench-V 上的比较
大模型视觉推理能力评测的发现和启示
发现 1: Scaling Law 是否对该任务有效?
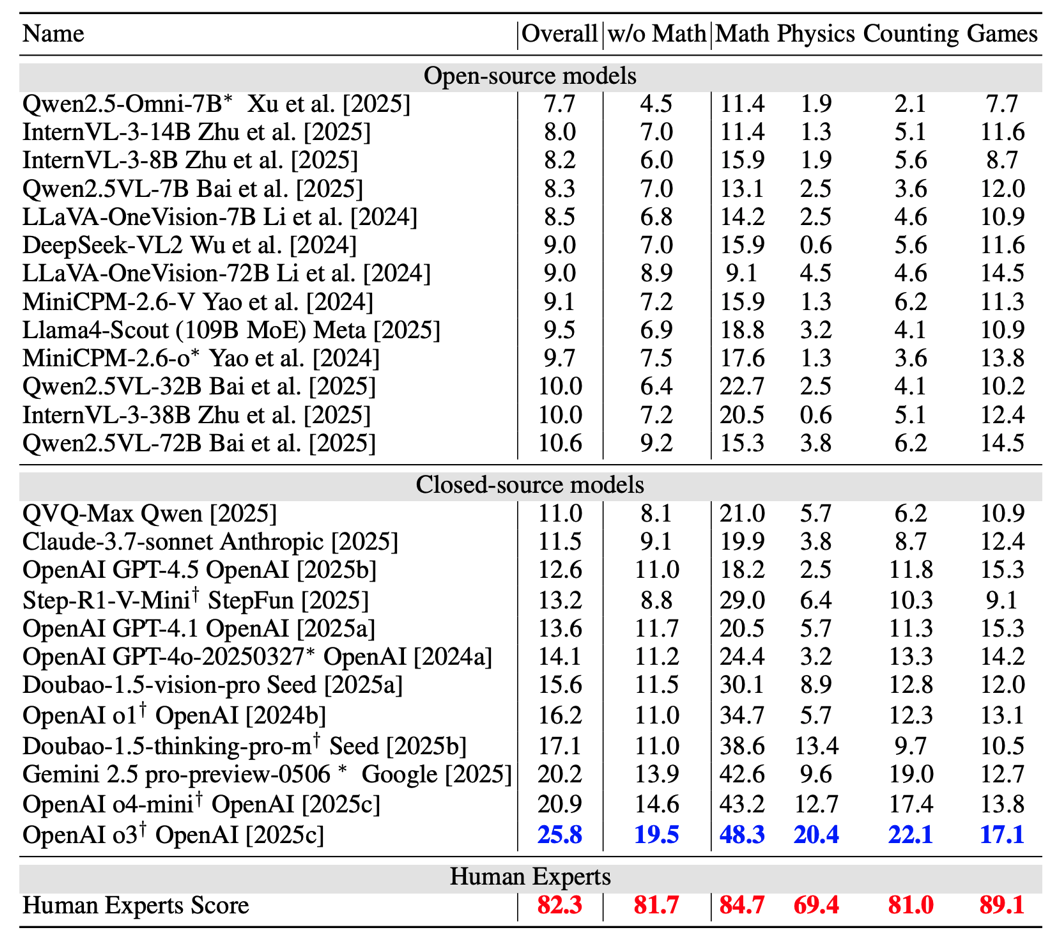
像InternVL 或Qwen-VL 系列这类缺乏多模态思维链(multi-modal CoT)的模型,单纯增加模型规模并不能有效解决视觉推理这一难题。正如表 1 所示,将Qwen2.5-VL 模型的参数规模从32B 扩大到 72B,并没有带来明显的 RBench-V 性能提升。在 InternVL 和 LLaVA-OneVision 系列中也观察到了类似现象。这表明,仅靠模型规模的扩展规律(scaling law)可能不足以应对视觉推理中多模态输出的挑战。
发现 2:模型是否真正学会了视觉推理?
基于文本的“捷径”依然是评估视觉推理能力时的一个普遍干扰因素。尽管模型在总体得分上表现较高,但我们的分析发现,模型常常能够通过利用先验知识或代数式重构来绕过真正的视觉推理,从而在人们认为是“视觉”任务的评测中取得虚高的成绩。如图 4 所示,OpenAI o3通过建立坐标系的代数方法解决了一个需要辅助线的几何问题。
发现 3:在要求多模态思维链的视觉推理过程中,基础模型的表现仍远不及人类表现。
正如表2 和图3 所示,即便是目前表现最好的模型 o3,其总体准确率也仅为25.8%,与人类专家 82.3% 的得分相比仍存在显著差距。这一巨大的性能差距凸显了当前基础模型在需要多模态思维链的视觉推理任务时的局限性。
图4给出了OpenAI o3的解题示意图,左图是o3在RBench-V 中通过将几何问题转化为代数问题并引入坐标系,正确回答了一道数学题,而人类通常会采用几何方法来解答。右图说明o3未能正确回答一道人机交互类游戏题。蓝色高亮部分标出了错误原因,核心问题在于模型未能按照指令绘制所需的连线。

图4 OpenAI o3 的解题示意图
目前,该项目中所有使用的数据已经在huggingface 上开源,地址为:
https://huggingface.co/datasets/R-Bench/R-Bench-V
关于项目的更多信息,请访问项目官网:
https://evalmodels.github.io/rbenchv/
论文链接:
https://arxiv.org/pdf/2505.16770
参考文献
Guo M H, Chu X, Yang Q, et al. RBench-V: A primary assessment for visual reasoning models with multi-modal outputs, NeurIPS 2025, arXiv preprint arXiv:2505.16770, 2025.
计图高斯库JGaussian开源 第五届计图人工智能挑战赛决赛顺利举行,16支队伍获奖! Computational Visual Media第11卷第4期导读 基于预积分渲染的可重光照神经表面方法NeuS-PIR | CVMJ Spotlight 基于华为昇腾的大模型推理框架JittorInfer全面升级并正式开源
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
