RBench公布最新大模型推理能力排行榜,GPT-5以微弱优势排名第一
大模型的智能正在进入一个新的衡量维度:推理。与单纯的知识记忆和复述不同,真正的智能体现在应对复杂问题时能否进行缜密的分析、严谨的推导和明智的决策——这正是推理能力的核心,也是模型在数学、编程、科学问答等高级任务中展现类人思维的关键。
过去一年,整个行业见证了推理能力的“寒武纪大爆发”。这股浪潮由OpenAI在2024年9月推出的o1模型点燃,并迅速席卷全球。仅仅数月后,2025年1月,DeepSeek R1的横空出世,让开源大模型第一次拥有了比肩闭源顶尖模型的复杂推理能力,成为一个历史性的时刻。紧随其后,国内外厂商纷纷入局,从Qwen的‘thinking’系列到OpenAI的o3,大家不约而同地将研发焦点对准了“先思考、再回答”这一核心范式,致力于提升模型的多步推理能力。
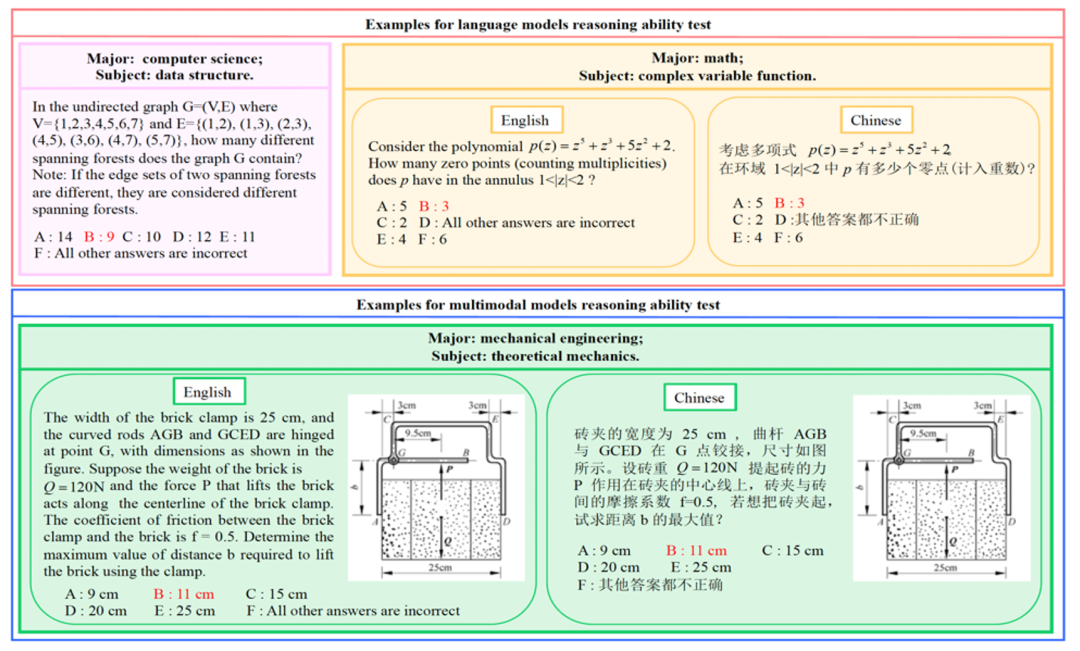
为了准确刻画这场技术革命的演进,社区需要一个可靠且系统的评测基准。清华大学联合斯坦福大学、卡内基梅隆大学等机构在 ICML 2025 [1] 上提出的 Reasoning Bench(RBench)便扮演了这一角色。它凭借覆盖学科广、题目难度高且兼顾中英双语的特点,为我们提供了一个绝佳的观察窗口。在接下来的内容中,我们将依托RBench的最新评测数据,对各大模型的表现进行系统性梳理,并回顾这场由o1开启的推理革命在过去一年中的发展脉络。
Part 1
RBench 上大模型的最新排名
近期,我们在 RBench 上测试了大量最新的开源和闭源的模型(截止到2025年9月), 它们的分数与排名如下表所示:

表1 RBench上闭源模型的最新排名
表2 RBench上开源模型的最新排名
1. 性能分层:三个梯队的形成
当前的推理模型市场已不再是混沌一片,而是形成了清晰的性能梯队:
第一梯队 (75+分 | SOTA级别): 由 GPT-5 (76.9) 和 DeepSeek-V3.1-Think (75.9) 组成。这标志着一个重要的行业里程碑:开源模型首次在顶级推理基准上达到了与最强闭源模型并驾齐驱的水平。开源模型不再是简单的追赶,而是在技术和性能上实现了对齐。
第二梯队(60-75): 这个区间汇集了顶级的开源和闭源模型,包括 DeepSeek-V3.1 (74.8), GLM-4.5 (73.6), OpenAI 的上一代旗舰o1 (69.6)以及豆包的推理专版模型。这个梯队的存在表明,强大的推理能力已不再是单一厂商的独家优势,而是一个竞争激烈、多强并驱的赛道。
第三梯队(<60分): 有趣的是,一年前还被视为行业标杆的 GPT-4o (52.6) 和 Claude 3.5 Sonnet (57.4) 在这个榜单上已不具备领先优势。这并非说明它们变弱了,而是凸显了过去一年里,专门针对“推理”进行优化的模型与通用模型之间已经拉开了显著的“推理代差”。
2. OpenAI的“王者”地位:从绝对领先到微弱优势
GPT-5的榜首位置,是OpenAI“以massive compute 换取 reasoning”战略的必然结果。从2024年的o1到2025年的GPT-5,OpenAI通过持续投入海量的训练和推理时算力,稳步提升其模型的推理水平。然而,与一年前o1发布时对市场形成的绝对压制不同,如今GPT-5的领先优势已缩小到“一个身位”以内。这表明,虽然暴力计算依然有效,但开源社区通过更高效的技术路径(详见Part 2),找到了缩短差距的有效方法。
3. 开源生态的“中国力量”:从参与者到引领者
这份榜单最引人注目的趋势之一,是开源模型排行榜的头部几乎被中国机构占据。DeepSeek、智谱AI(GLM) 和阿里巴巴(Qwen)发布的模型包揽了开源榜单的前列。这不仅证明了开源生态的全面成熟,更是一个强烈的信号:在“推理”这一大模型技术的核心腹地,中国顶尖AI团队已经从过去的“追随者”成长为能够定义SOTA(State-of-the-Art)的“引领者”,并且正在系统性地缩小与美国顶尖机构的差距。
Part 2
OpenAI o1发布一年来的模型发展趋势
自OpenAI o1发布以来的一年,大模型领域的发展并非简单的分数追逐,而是围绕“如何构建更强大的推理能力”这一核心问题,逐步形成了一套清晰的技术范式。这一范式由三个相互关联、层层递进的趋势所驱动:目标范式的转变、训练方法的革新以及模型架构的演进。
1. 范式之变:从“快思考”到“慢思考”,推理能力成为共识
早期大模型(如GPT-3.5)更擅长快速、直觉地生成流畅文本。而OpenAI o1的发布,则标志着业界首次将推理能力作为大规模商业化产品的核心。
这一转变的核心在于,模型被设计为在生成最终答案前,先进行一步显式的内部“思考”(即思维链)。这个过程虽然在推理时需要更多的计算,却能显著提升模型在复杂问题上的逻辑推导能力。o1的成功迅速确立了这一方向的价值,此后,DeepSeek R1、Qwen的“thinking”系列以及GLM-4.5等模型纷纷跟进,将“先思考,再回答”作为其核心设计,标志着推理能力已成为行业共识。
2. 训练之革:GRPO技术,让高效强化学习成为可能
确立了推理能力的目标后,下一个挑战是如何经济高效地教会模型生成正确且有用的思维链。传统的强化学习流程(如PPO)极其复杂且计算昂贵,是许多机构难以逾越的障碍。
DeepSeek在其模型中开创性地使用了“组相对策略优化”(GRPO, Group Relative Policy Optimization),为这一难题提供了优雅的解决方案。GRPO的核心创新在于,它让模型对同一问题生成多个候选答案,并用一个奖励函数进行评分和内部归一化,从而创造出稳定有效的学习信号,而无需依赖独立的价值模型(value model)。GRPO极大地降低了训练推理模型的复杂度和计算开销,使得算力有限的机构也能训练出顶尖的推理模型,这也是DeepSeek R1等开源模型能迅速崛起的关键技术支撑。
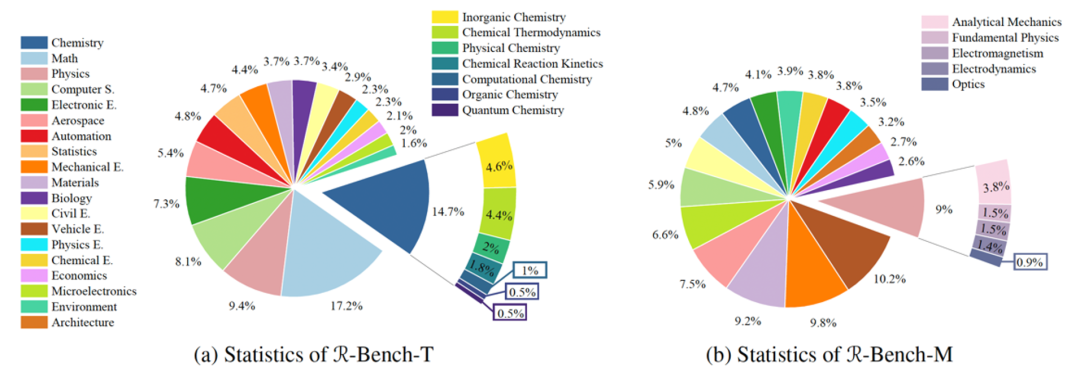
表3 不同模型架构和参数的对比
3. 架构之基:混合专家(MoE),实现规模与效率的平衡
有了明确的目标和高效的训练方法,最后一个关键环节是模型架构。为了处理高难度推理,模型需要巨大的知识储备和参数规模,但这又会带来高昂的推理成本。混合专家(Mixture-of-Experts, MoE)架构成为了解决这一矛盾的关键。
与传统模型所有参数在每次计算时都被激活(密集激活)不同,MoE架构包含多个“专家”网络和一个“路由器”。路由器会为每个输入 token 智能地选择一小部分专家进行计算(稀疏激活)。这种设计使得模型可以在拥有巨大的总参数量(如DeepSeek-V3的6710亿)的同时,每次推理只激活其中一小部分(如370亿),从而在保持低廉推理成本的同时,获得巨大模型规模带来的强大能力。如表3,各个机构也逐步将其开发的大模型架构转为MoE架构。
Part 3
未来发展趋势
在高效训练方法(如GRPO)和规模化效率架构(如MoE)的共同推动下,大模型推理能力在过去一年取得了显著的进步。然而,当前的推理主要局限于模型内部的、纯文本的逻辑链条。展望未来,推理能力的下一个前沿将是打破这些界限,向着更接近人类真实问题解决能力的范式演进。
1. 从文本到多模态:图文交错推理
当前的大模型推理主要在文本世界中进行,但这与人类认知存在根本差异。人类知识体系,尤其是在科学、工程和教育领域,是深度图文融合的。未来的推理模型必须能够处理和理解散布在文本、图表、公式和示意图中的信息,拥有进行类似人类一样的图文交错推理(Interleaved Text-Image Reasoning)的能力。
2. 从“思考”到“行动”:智能体增强推理
“思维链”让模型学会了“思考”,而智能体(Agent)则赋予模型“行动”的能力。这意味着模型不再是一个封闭的推理器,而是可以主动与外部世界或工具交互,以获取信息、验证假设和执行任务。
智能体增强推理(Agent-augmented reasoning)的核心循环是“规划-行动-观察-反思”。模型首先将复杂问题分解成一系列步骤(规划),然后为每个步骤选择并调用合适的外部工具,如代码解释器、网络浏览器、计算器或专用API(行动)。它会分析工具返回的结果(观察),并根据新信息调整后续的推理路径(反思)。这种范式极大地扩展了模型的边界。它能解决传统模型无法处理的问题:需要实时信息(如“今天下午从北京到上海最快的交通方式是什么?”)、精确数学计算、或与外部软件系统交互的任务。这使得推理不再是纯粹的智力游戏,而是解决现实世界问题的实用工具。
3. 开源生态的持续加速
2025年见证了开源社区创新的惊人速度:DeepSeek R1(1月)、Qwen3(4月)、GLM-4.5(7月)和DeepSeek-V3.1(8月)相继发布。这种快速迭代得益于开放协作和GRPO等高效训练技术,与闭源大模型更为审慎、单一的发布周期形成鲜明对比。这些模型普遍采用 MIT、Apache 2.0 等宽松的许可证,极大地推动了它们的普及和二次创新。可以预见,未来最前沿的推理技术(如图文推理、智能体)也将更快地在开源社区中涌现和成熟。
Meng-Hao Guo, Jiajun Xu, Yi Zhang, Jiaxi Song, Haoyang Peng, Yi-Xuan Deng, Xinzhi Dong, Kiyohiro Nakayama, Zhengyang Geng, Chen Wang, Bolin Ni, Guo-Wei Yang, Yongming Rao, Houwen Peng, Han Hu, Gordon Wetzstein, Shi-min Hu. RBench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation. ICML, 2025.
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。