
基于华为昇腾的大模型推理框架JittorInfer全面升级并正式开源
继上次清华大学计图(Jittor)团队发布在华为昇腾平台上完成DeepSeek系列大模型高效适配的初步成果后,团队持续对自研的推理框架JittorInfer进行深度迭代与优化,引入了多项系统级优化技术,实现了性能的再次显著提升。

今天,这套高性能、自主可控、基于华为昇腾的大模型推理框架 JittorInfer,即日起向全社区开源!在此诚挚邀请社区同仁与我们携手,共同助力国产AI 生态的建设与发展。
项目地址:
https://github.com/Jittor/JittorInfer
Part 1
项目背景与动机
大语言模型(LLMs)的蓬勃发展,对底层算力平台的效率提出了前所未有的挑战。尽管业界涌现了以vLLM为代表的高性能推理框架,但其优化重心长期聚焦于NVIDIA的CUDA生态,这使得它们在向国产硬件平台迁移时,普遍面临适配成本高、优化经验不共通、性能难以完全发挥等一系列问题。
为打通“国产大模型 × 国产软件 × 国产算力”的全栈技术链路,清华大学计图团队在华为昇腾硬件上对DeepSeek系列模型展开了系统性的适配与优化工作。团队前期的工作已经验证了这条技术路线的可行性,成功在单台8卡昇腾服务器上运行了DeepSeek R1模型,并在DeepSeek V2上取得了相较于vLLM(Ascend版本)平均超53%的性能提升。为了进一步挖掘国产硬件的潜力,近期我们对这套昇腾大模型推理框架JittorInfer进行了再次升级。
Part 2
JittorInfer再次升级
为了进一步提升硬件性能、解决推理过程中的深层瓶颈,JittorInfer在本次升级中引入了“算子融合下发”和“全链路服务端优化”等一系列关键技术。
升级点一:大模型算子融合下发
大模型推理过程由成千上万个细粒度的算子构成。在传统的执行模式下,CPU需要逐一向AI芯片“下发”这些算子的执行指令。这个“下发”动作本身存在不可忽略的开销,当算子数量极多时,CPU会耗费大量时间在调度上,而此刻强大的AI计算单元却处于空闲等待状态,造成了严重的资源浪费。
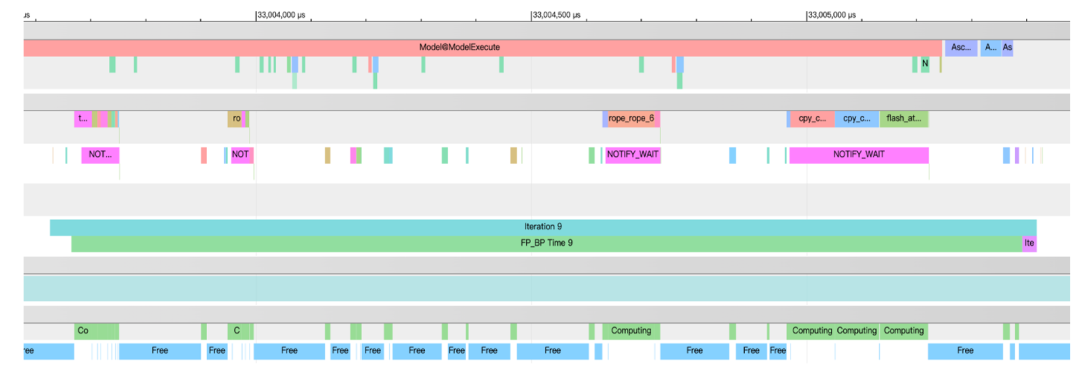
图1 cpu算子融合下发优化前的执行timeline
JittorInfer实现了一种先进的“算子融合下发”机制,其原理类似于CUDA Graphs。我们将推理图中的一个完整操作序列(包含各类元算子)预先“融合”成一个单一的、可复用的计算单元。在实际推理时,CPU不再需要进行成百上千次的独立下发,而只需执行一次下发操作,就能触发整个融合后的计算图在AI芯片上“端到端”地高效执行。这一创新极大地减少了CPU与AI芯片之间的交互开销,将CPU从繁重的调度任务中解放出来,从而确保了计算单元能够持续处于高负载状态,最大化硬件的有效利用率。
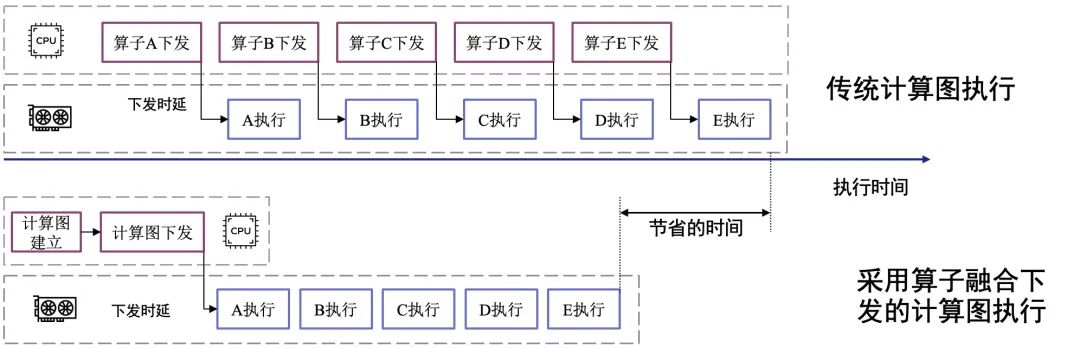
图2 大模型算子融合下发示意图
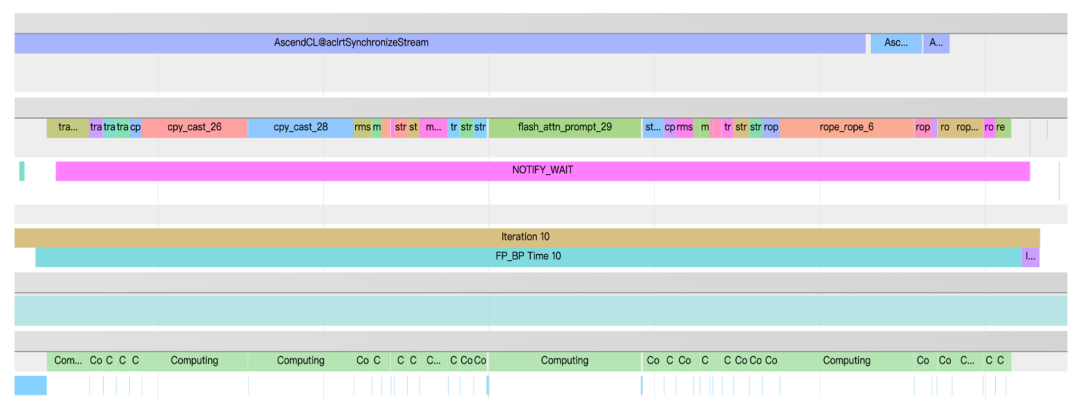
图3 cpu算子融合下发优化后的执行timeline
升级点二:全链路服务端优化
一个优秀的推理系统,优化不能止步于模型本身。我们分析了从请求接收到结果返回的整个服务端流程,并针对性地解决了三大性能瓶颈:
优化PCIe传输瓶颈:将采样逻辑下沉至NPU:在标准的LLM解码流程中,模型在NPU上计算出代表词汇表概率分布的logits向量后,需要将其完整地通过数据总线传传回CPU,由CPU完成采样(即选择下一个词)。对于拥有数万词汇表的大模型,logits向量体积庞大,频繁的异构传输构成了通信瓶颈,直接限制了token的生成速度。我们将采样/解码逻辑从CPU下沉到了NPU内部执行。整个“logits → token ID”的过程在加速器芯片内闭环完成,最终只需将代表结果的token ID传回CPU。这一改动将CPU与NPU数据总线上的通信量基本消除,有效降低了解码延迟,显著提升了吞吐能力。

图4 采样逻辑下沉至NPU
升级服务端调度机制:从“广播”到“精准提醒”:在高并发场景下,原有的服务端HTTP任务队列机制存在冗余。每当有新请求到来时,系统会向所有等待的HTTP线程进行“广播”提醒,即便其中大部分线程并非处理该请求的目标。这种“全量广播”机制在请求密集时会产生不必要的调度开销,加重CPU负载,如图5所示,优化前的任务队列机制会向所有HTTP 线程进行广播唤醒,导致部分线程被无效唤醒。我们对任务队列机制进行了优化,将其从“广播”模式修改为“单播”模式。现在,系统仅对消息队列中真正建立了查询请求的目标线程进行精准提醒,避免了无效的唤醒和上下文切换,从而显著降低了高并发下的CPU负载。
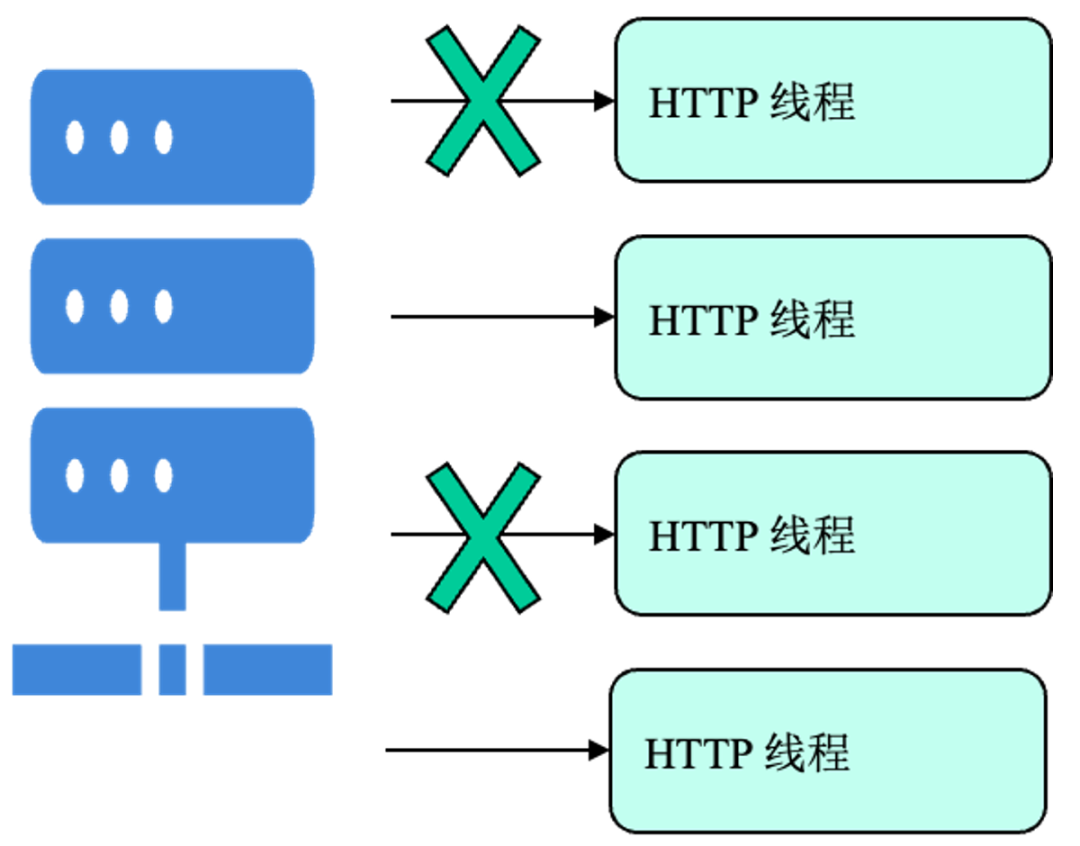
图5 优化前的任务队列机制导致部分线程被无效唤醒
升级KV Cache查询效率:用bitset替代平衡树:KV Cache是实现高效生成式推理的关键,需要对其内存块的被请求的使用状态进行管理。原有实现使用平衡树(如C++中的std::set)来维护这一状态。然而,对于仅需表示“占用/未占用”(0/1)的二元信息,平衡树这种复杂数据结构的查询开销相对较大,影响了整体效率。我们使用bitset(位表)替代了平衡树。bitset利用单个比特位来表示一个内存块的状态,可以通过高效的位运算来完成状态的查询和修改。这个修改提升了KV Cache的状态管理效率,降低了常数开销,为整体性能的提升做出了贡献。
图6 bitset替代平衡树
Part 3
JittorInfer性能结果对比
通过上述一系列系统性的技术升级,结合我们已有的底层算子库深度优化等工作,JittorInfer的推理性能再次实现了飞跃:
在单张华为昇腾910系列卡上运行DeepSeek V2-Lite (16B)模型,JittorInfer的推理性能相较于vLLM-Ascend平均提升幅度高达356.7%。
在单机8卡华为昇腾910系列服务器上运行DeepSeek V2 (236B)模型,JittorInfer的推理性能相较于vLLM-Ascend平均提升87.8%,相比我们上一版成果(53%)提升显著。
下面展示了JittorInfer框架升级后的推理速度的详细对比,以及相关的运行效果。
表1 华为910系列-单卡DeepSeek V2-Lite模型与vLLM速度对比
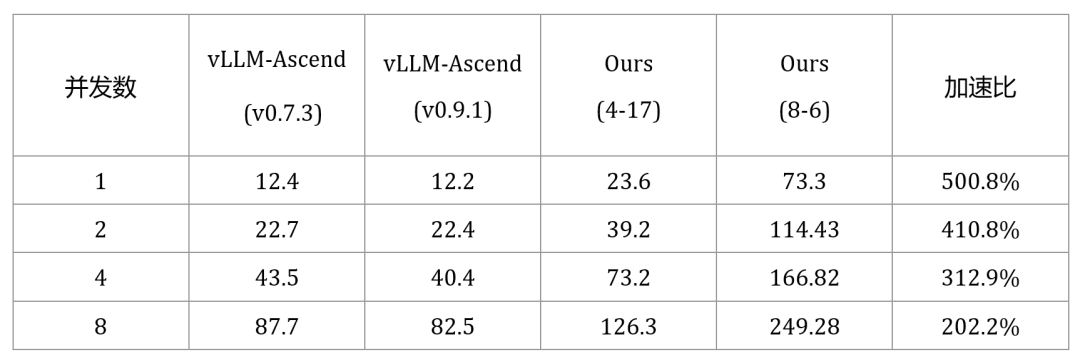
表2 华为910系列-单机(8卡)DeepSeek V2模型与vLLM速度对比
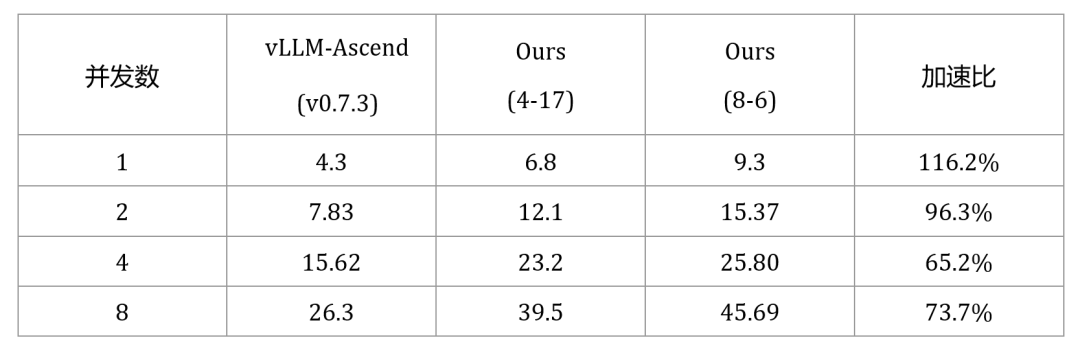
图7 16并发推理demo
Part 4
开源与下一步规划
开放与协作是技术生态繁荣的基石。JittorInfer正式开源,希望将这些技术成果回馈社区,为所有致力于国产AI技术发展的开发者和企业提供一个强大、高效的工具,共同为华为昇腾AI基础软硬件平台注入新的活力。
项目地址:
https://github.com/Jittor/JittorInfer
JittorInfer微信交流群:

下一步规划
深度优化单卡推理版本,重点提升高并发处理速度,并扩展对更多主流模型的支持。
持续挖掘单机8卡推理版本的性能潜力。
开发并优化面向大规模集群的多节点推理版本。
我们诚挚地欢迎所有的人工智能、大模型的爱好者、研究者和开发者加入我们,共同为国产人工智能生态的发展做出贡献。
Part 4
致谢
本项目的开发与开源离不开各方的大力支持与协作。在此,我们谨向所有参与和支持本项目的单位与个人致以诚挚的感谢。感谢计图联盟成员单位的积极贡献,包括清华大学计算机系翟季冬教授团队(黄书鸿、杨雨晴、宗瓒)、南开大学程明明教授团队(范登平教授、朱子轩)以及北京非十科技有限公司,他们在模型调试与实验验证方面做出了重要贡献;感谢华为半导体图灵GE图引擎、昇腾CANN生态等团队在适配过程中提供的宝贵指导与技术支持;此外,感谢清华—华为鲲鹏昇腾卓越中心为本项目提供的算力支持。项目实现过程中参考并借鉴了 GGML、llama.cpp 等优秀开源项目,在此特别向 ggml-org 社区表示感谢。
GGC往期回顾
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
