
计图开源:首个国产情感计算代码库NK-AffectiveComputing
由南开大学、清华大学等单位的10位专家联合提出的“情智兼备数字人与机器人的研究”入选2024年中国科协十大前沿科学问题第1位。其中,情智兼备是新一代人工智能研究和发展的重要方向,是实现通用人工智能的关键一步。
立足于我国人工智能高水平自立自强的重大需求,南开大学计算机视觉实验室积极推进情感认知计算领域的上下游创新成果国产化。基于计图深度学习框架(Jittor)[1],团队维护的NK-JittorCV最新开源了NK-AffectiveComputing仓库,推动计图框架从内容感知领域向更高层次的认知计算领域拓展。该平台已集成了4项国际前沿的视频情感理解方法,并实现与7个主流视频情感数据集的无缝对齐。
实验结果表明,Jittor框架在计算效率方面相较于当前主流的PyTorch框架具有显著优势,降低了模型训练与部署开销,有力支撑了创新算法从模型开发、训练、测试到实际部署的全流程国产化落地,为我国人工智能技术生态体系的自主可控和可持续发展提供了坚实支撑。
代码地址:
https://github.com/NK-JittorCV/nk-affectivecomputing
中英文档:
https://github.com/NK-JittorCV/nk-affectivecomputing/tree/master/docs
相关工作:
https://github.com/NK-JittorCV/nk-affectivecomputing/blob/master/docs/en/papers.md
Part 1
研究背景
计图(Jittor)是清华大学计算机系图形学实验室于2020年3月20日发布并开源的深度学习框架,并于2025年5月成立“计图”产学研联盟,旨在紧扣人工智能技术和产业的重大共性问题,立足我国人工智能发展需求,汇聚各方优势资源,打造计图深度学习框架技术创新和合作发展的共同体,推动人工智能上下游的创新成果快速产品化,加快实现我国人工智能领域的高水平自立自强,促进人工智能相关行业高质量发展和产业升级。
计图框架已在图像分类、目标检测、遥感分析等多个内容感知领域发布了代码库,展现出良好的应用前景。近期,南开大学计算机视觉实验室杨巨峰、张知诚等人围绕中国科协十大前沿科学问题之一“情智兼备数字人与机器人的研究”,率先开发了基于计图框架的情感计算领域代码库NK-AffectiveComputing,实现了计图框架从感知领域向认知领域的拓展,为我国人工智能基础软件生态建设和前沿交叉领域研究提供了有力支撑。
在人机交互场景中,情智兼备的数字人与机器人需要精准解译多模态交互信息,深度挖掘人类内在情感状态,从而实现更具真实感与自然性的人机对话[2,3]。然而,面对多模态情感数据语义的高度复杂性,如何有效建模跨模态关联关系仍是领域内亟待突破的核心挑战。
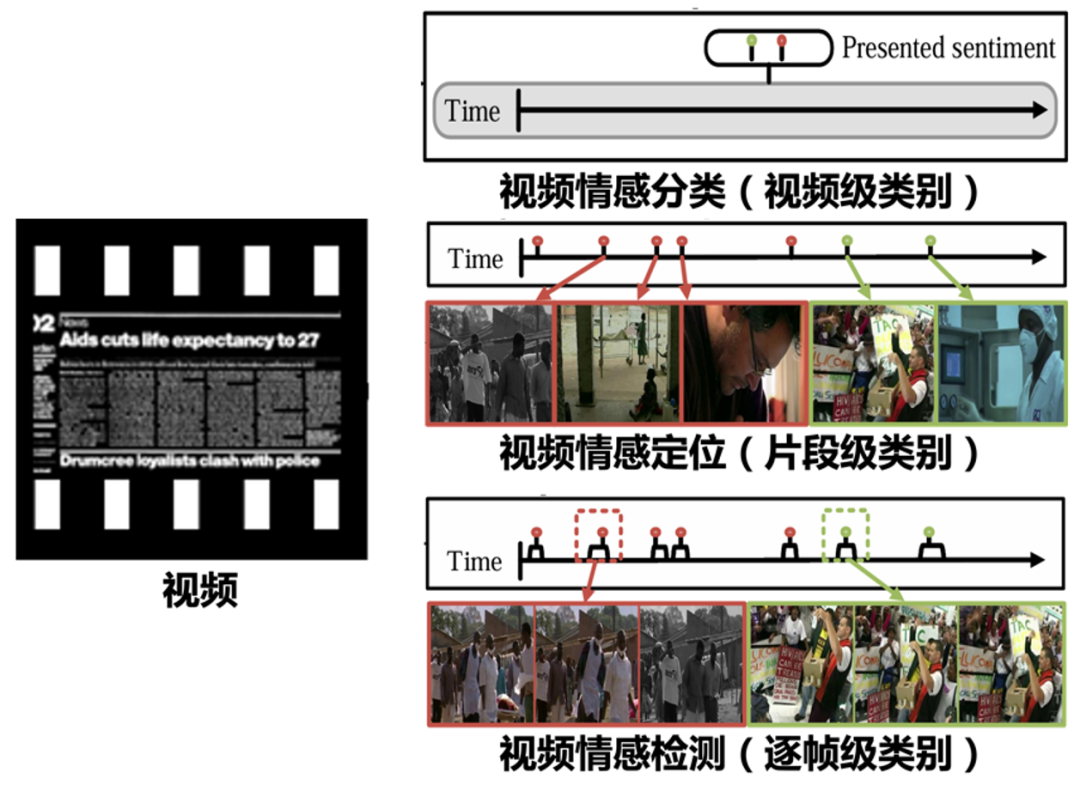
图1 视频情感理解覆盖分类、定位、检测等任务
针对上述挑战,NK-AffectiveComputing代码库已集成并支持多种先进的视频情感理解方法,如图1所示,涵盖视频情感分类、定位、检测等多项任务,并进一步拓展至步态视频情感分析。具体包括:
CTEN [CVPR' 23]:支持视频情感检测任务 [4]
TSL-Net [MM' 22]:支持视频情感定位任务[5]
VAANet [AAAI' 20]:支持视频情感分类任务[6]
Gait [TAC' 24]:支持步态视频情感分类任务[7]
Part 2
计图拓展模块:视频情感分类/定位/检测
视频情感检测CTEN
为建模逐帧情感,团队提出了一种全新的跨模态时间擦除网络。与现有方法主要依赖某些“情感显著帧”不同,该方法引入了跨模态建模(视觉+ 音频)与上下文感知机制,让模型学会在视频的连续片段中理解情感的发展轨迹。如图2,该方法的核心设计包括两个模块:一是时序关联学习模块,用于发现不同视频片段在视觉与音频模态之间的潜在联系;二是时序擦除模块,它会在训练中动态“抹去”最容易引起模型注意的显著特征,引导模型去关注那些容易被忽略、但对情感判断至关重要的上下文线索。这种“抹去显著、强化补充”的机制,极大提升了模型的鲁棒性和情感理解能力。
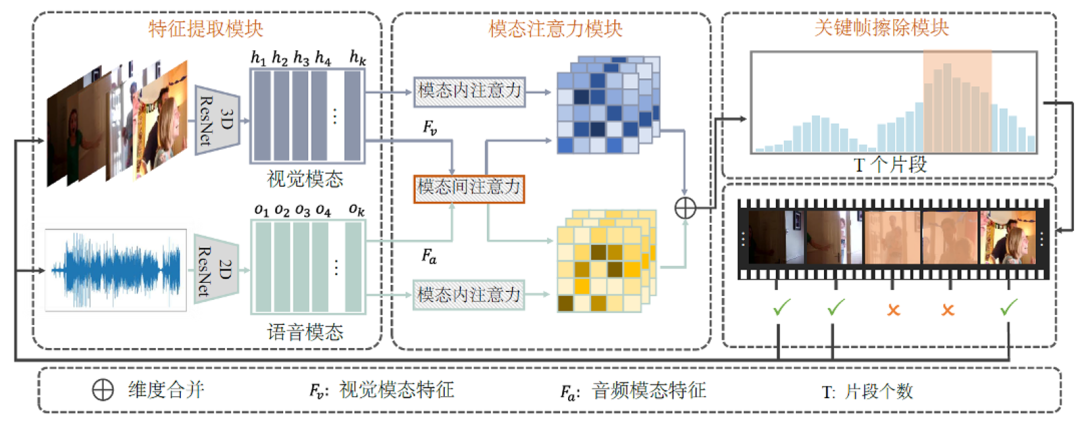
图2 视频情感检测模块CTEN框架图
视频情感定位TSL-Net
为进行精准视频情感定位,团队提出了一种弱监督框架TSL-Net,如图3所示,使用单帧监督即可训练多模态融合网络来定位视频中的情感,显著降低了密集标注成本。具体而言,该方法通过贪婪搜索策略为未标注帧生成伪标签,并融合视觉与音频模态的情感特征以预测时间情感分布。在特征融合过程中,设计了反向映射策略,并引入对比损失以保持原始特征与反向预测之间的一致性。
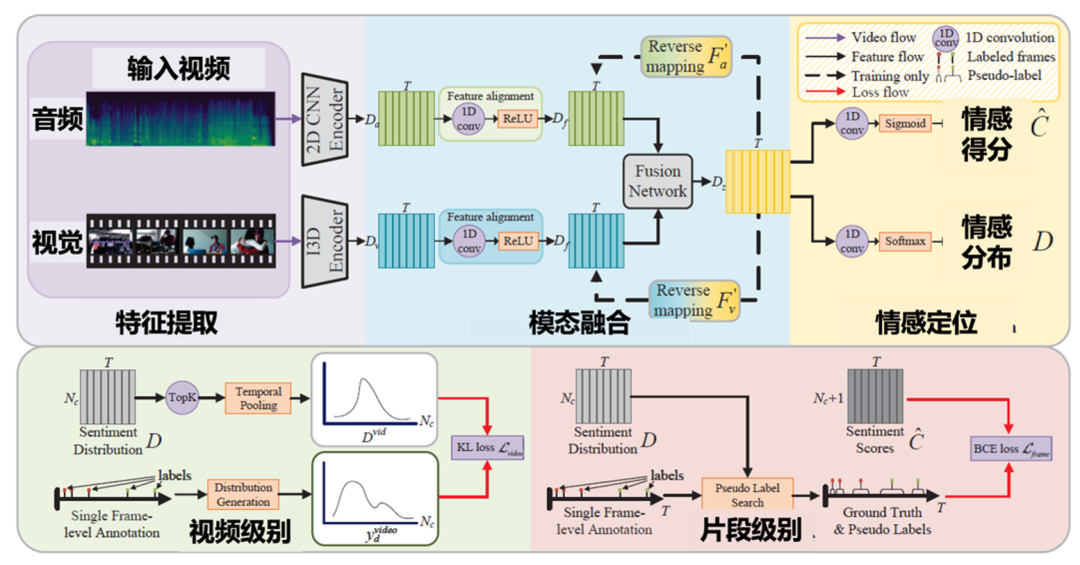
图3 视频情感定位模块TSL-Net框架图
视频情感分类VAANet
针对情感抽象难理解,团队提出了首个端到端用户生成视频情感分类的方法VAANet,无需辅助数据,仅靠视觉与音频输入即可完成训练。如图4所示,通过3D CNN提取视频帧特征、2D CNN解析音频频谱,再结合空间、通道与时间注意力机制,VAANet精准捕捉情感线索。同时,创新引入极性一致交叉熵(PCCE)损失函数,让模型感知情感方向。
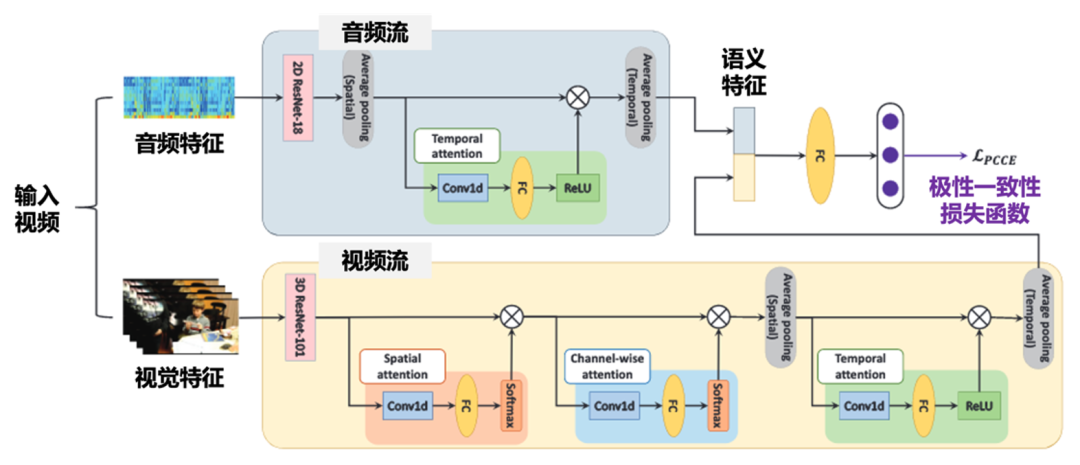
图4 视频情感分类模块VAANet框架图
步态视频情感分类Gait
针对清晰视频难获取的场景,例如夜晚缺乏足够光线,团队提出了一种步态情感视频理解方法,构建了一种双向姿态与运动图卷积网络,如图5所示,该网络由两条并行流组成,分别为姿态流和运动流,从两个视角进行情感识别。姿态流旨在显式分析个体的情感状态。该方法通过基于人工特征的新型回归约束,将先验情感知识蒸馏到网络中,从而增强情感表示的学习。运动流旨在描述情感的强度,这是一种隐含线索,可辅助情感识别。为实现这一目标,该方法使用高阶速度-加速度对构建图,从而利用富含信息的运动特征。
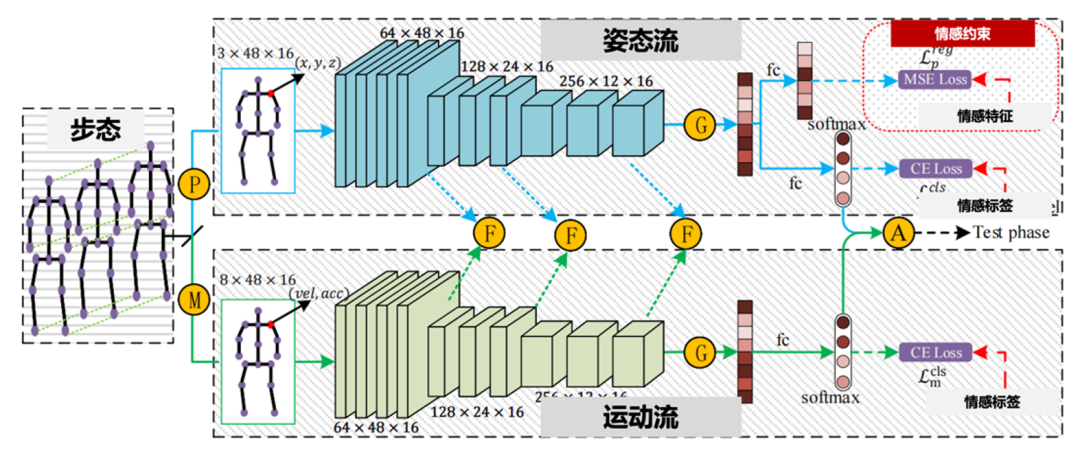
图5:步态视频情感分类模块Gait框架图
Part 3
计图补充模块:视频情感理解支持
为支持视频情感理解任务,团队构建了Jittor补充模块来提供全流程的支持,包括训练组件、测试组件和部署组件。训练组件能够兼容多种主流情感分析模型,支持多模态输入,并允许用户灵活配置参数,极大地方便了模型的迁移和优化。

图6:训练组件示例
测试组件提供了标准化的测试脚本,可以对整个数据集进行批量评估,帮助用户高效获取模型性能和实际应用效果。测试过程支持数据增强等常用设置,保证结果的可复现性和可靠性。

图7 测试组件示例
部署组件则使得训练好的情感计算模型能够高效地应用到实际场景中。依托计图高性能框架实现游客情感检测、对话分析等多种下游应用。

图8 部署组件示例
Part 4
实验结果与性能对比
基于计图国产框架,情感计算方法的部署速度相比PyTorch可提升1.1至1.6倍,从而更好地支持下游应用如游客情感检测、对话分析、舆情监控等。
我们在TSL-300数据集上进行全面对比实验,所有实验都在单张3090显卡上测试。如图9所示,基于计图框架的代码在forward时间上减少了接近80%,在单个lteration上取得了181ms的提升,性能指标F2分数取得了2.08%的提升。
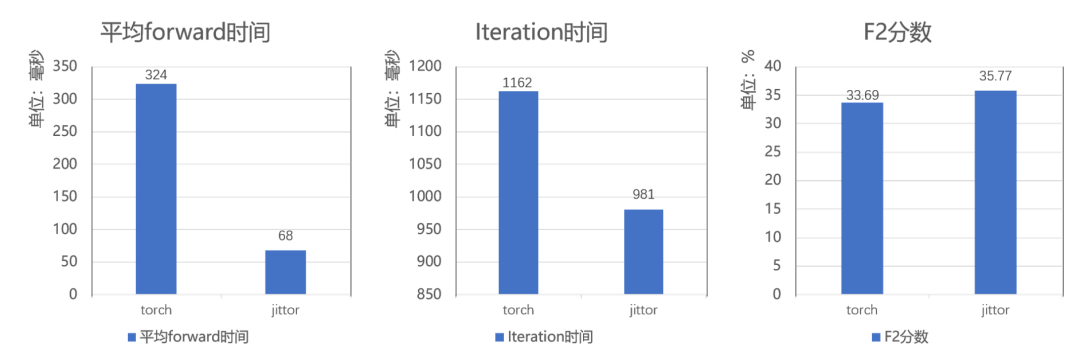
图9 视频情感理解方法TSL-Net在Jittor与Torch框架的性能对比
我们还在Emotion-Gait数据集上进行全面对比实验,所有实验都在单张3090显卡上测试。如图10所示,基于计图框架的代码在forward时间上减少了75%,在单轮epoch上取得了1528ms的提升,性能指标平均准确率取得了2.16%的提升。
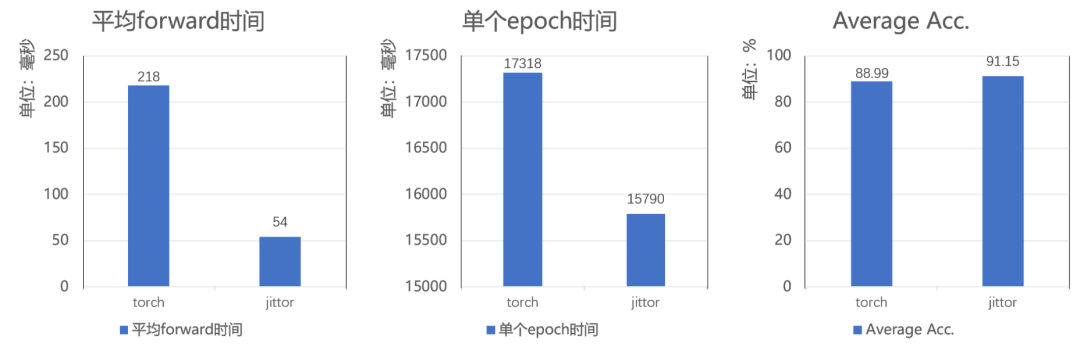
图10 步态视频情感理解方法Gait在Jittor与Torch框架的性能对比
参考文献
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, and Wen-Yang Zhou. Jittor: a novel deep learning framework with meta-operators and unified graph execution. Science China Information Sciences, 2020, 63(12): 222103.
Zhicheng Zhang, Wuyou Xia, Chenxi Zhao, Zhou Yan, Xiaoqiang Liu, Yongjie Zhu, Wenyu Qin, Pengfei Wan, Di Zhang, and Jufeng Yang. MODA: MOdular Duplex Attention for multimodal perception, cognition, and emotion understanding. ICML, 2025.
Zhicheng Zhang, Pancheng Zhao, Eunil Park, and Jufeng Yang. MART: Masked Affective RepresenTation learning via masked temporal distribution distillation. CVPR, 2024: 12830-12840.
Zhicheng Zhang, Lijuan Wang, and Jufeng Yang. Weakly supervised video emotion detection and prediction via cross-modal temporal erasing network. CVPR, 2023: 18888-18897.
Zhicheng Zhang and Jufeng Yang. Temporal sentiment localization: Listen and look in untrimmed videos. ACM MM, 2022: 199-208.
Sicheng Zhao, Yunsheng Ma, Yang Gu, Jufeng Yang, Tengfei Xing, Pengfei Xu, Runbo Hu, Hua Chai and Kurt Keutzer. An end-to-end visual-audio attention network for emotion recognition in user-generated videos. AAAI, 2020, 34(01): 303-311.
Yingjie Zhai, Guoli Jia, Yu-Kun Lai, Jing Zhang, Jufeng Yang and Dacheng Tao. Looking into gait for perceiving emotions via bilateral posture and movement graph convolutional networks. IEEE Transactions on Affective Computing, 2024, 15(3): 1634-1648.
GGC往期回顾
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
