
计图开源:面向稀疏环视图像的前馈三维高斯泼溅驾驶场景重建方法
上海交通大学与华东师范大学合作,提出一种基于三维高斯泼溅的驾驶场景重建方法DrivingForward [1],从车载相机拍摄的稀疏环视图像中快速重建驾驶场景,所提出的前馈重建方法可跨场景泛化,无需逐场景优化。该项研究工作的论文已被AAAI 2025录用,已提供计图开源代码。论文的作者为田旗舰(上海交大)、谭鑫(华东师大)、谢源(华东师大)和马利庄(上海交大/华东师大)。
Part 1
问题和背景
驾驶场景三维重建对于增强驾驶场景的理解、推动自动驾驶的发展至关重要。近年来3DGS的发展极大推动了三维重建领域的发展[2],一些方法[3-6]进一步将3DGS应用至驾驶场景,尽管这些方法展示了重建的场景具有优秀的新视角合成能力,但这些方法属于逐场景优化,需要数十张图像和数分钟乃至数小时的时间去重建仅仅一个场景,这些离线的重建方法无法适应自动驾驶领域具有实时性要求的下游任务,因此限制了它们的应用范围。
研究团队的目标是实现快速、可泛化的驾驶场景重建。一些前馈重建方法[7-8]已经探索了实时、可泛化的重建,这些方法在训练时从大规模跨场景数据集中学习场景先验,在推理时无需优化即可重建三维场景。然而这些方法难以直接应用于驾驶场景,因为驾驶场景的图像往往是由车载相机拍摄的环视稀疏图像,相邻相机图像之间的重叠范围极小,而现有的前馈重建方法往往需要输入图像具有较大的重叠范围。
为了解决上述问题,研究团队提出了DrivingForward,一种面向稀疏环视图像的前馈三维高斯泼溅驾驶场景重建方法,该方法作为一种前馈重建方法,能够实现快速、可泛化的重建,无需逐场景优化,满足了驾驶场景中下游任务的实时性要求;此外,该方法面向驾驶场景的稀疏环视图像,克服了现有前馈重建方法直接应用在驾驶场景的不足。DrivingForward与其他重建方法的功能对比如图1所示。
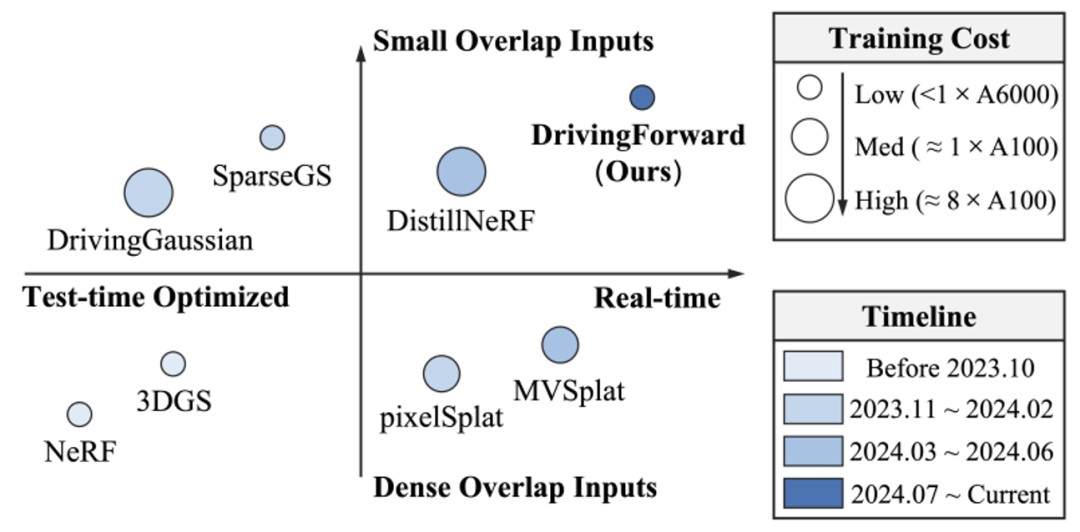
图1 DrivingForward与其他重建方法的功能对比
Part 2
方法概述
DrivingForward在训练时从大规模、跨场景的数据集学习先验知识,推理时以前馈的形式从车载环视相机拍摄的稀疏图像中快速重建驾驶场景,无需逐场景优化。DrivingForward的整体框架如图2所示,以N张稀疏环视图像为输入,其目标是从每张图像预测对应的三维高斯。DrivingForward包含3个子网络:深度网络、姿态网络和高斯网络。深度网络预测每张图像的深度,姿态网络预测上下帧之间相机(车辆)姿态的变换矩阵,深度网络和姿态网络通过自监督的方式训练,从环视相机相对车辆的固定相机位姿中学习绝对尺度的深度,随后预测逐像素的三维高斯,三维高斯的位置通过将深度投影到三维空间得到,其他属性则通过高斯网络预测。推理时,深度网络和高斯网络以前馈的形式重建三维驾驶场景。
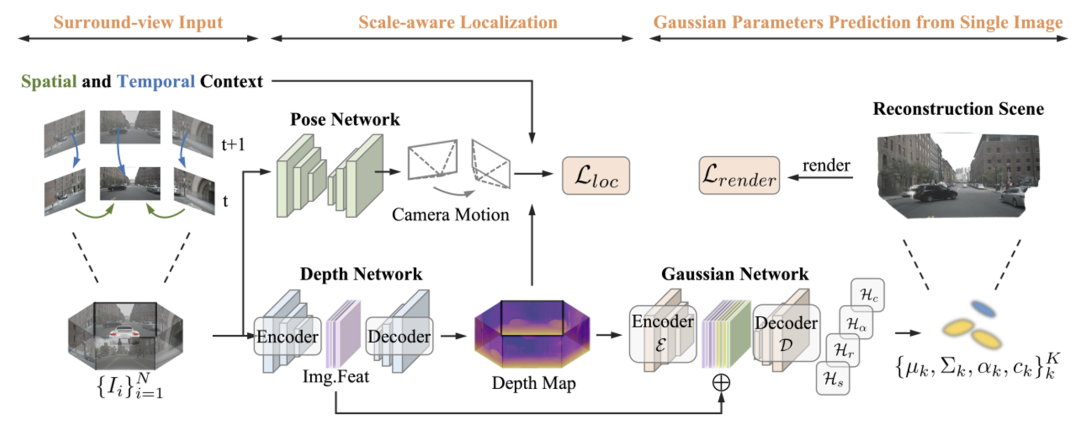
图2 DrivingForward的整体框架
2.1 尺度感知定位
训练时,DrivingForward输入多帧环视图像,通过尺度感知定位模块以自监督的方式学习绝对尺度的深度,绝对尺度的来源是车载相机相对车辆提前校准的位姿,该位姿对应了绝对尺度的深度。尺度感知定位模块包括深度网络D和姿态网络P,其中,深度网络预测图像的深度,姿态网络预测上下帧输入之间车辆的位姿,由于车载环视相机相对车辆固定,因此车辆在上下帧之间的位姿变换即为相机的位姿变换:
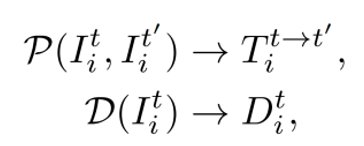
为实现自监督学习绝对尺度的深度,研究团队采用了基于图像warp操作的自监督训练方法。图像warp操作是指给定一个目标图像和参考图像,通过目标图像的深度和两张图像的相机内参以及变换矩阵,利用网格采样的方式将参考图像的像素映射到目标图像,这个过程中,两张图像的变换矩阵T通过姿态网络预测,目标图像的深度D通过深度网络预测,通过计算warp图像与目标图像的重投影损失进行反向传播优化姿态网络和深度网络的参数,重投影损失如下:
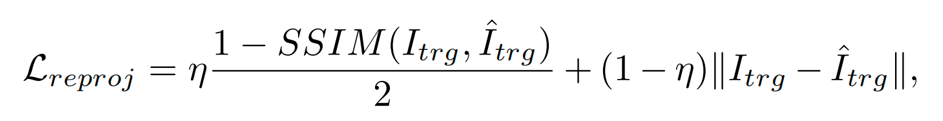
上述过程的形式化表述为:
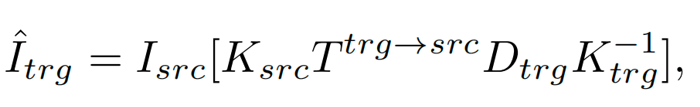
其中,目标图像和参考图像的选择是自监督学习过程中的关键因素,为此,研究团队根据环视驾驶场景的特点,提出了基于空间、时间以及时空的重投影,假设Ci、Cj 为相邻相机,Iit、Ijt 为它们在第t帧时拍摄的图像,对于每个相机i=1..N:
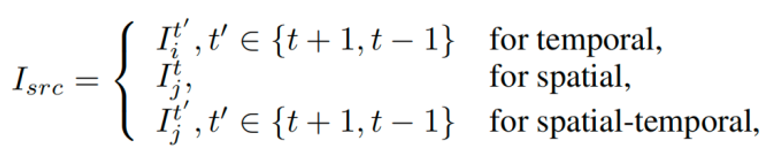
对应的warp过程中的变换矩阵E计算如下:
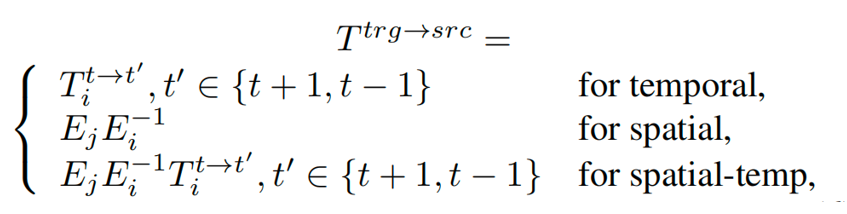
由此,在自监督学习的过程中充分利用了稀疏环视图像在空间、时间和时空上的极小重叠,从车载相机相对车辆的固定位姿中挖掘出绝对尺度的信息。此外,在训练的过程中额外施加了深度平滑损失以使得预测的深度更加平滑,尺度感知定位整体的损失函数如下:
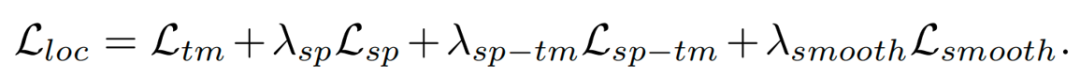
最后,将预测的深度投影到车辆坐标系的三维空间,得到逐像素的三维高斯的位置属性,实现三维高斯的定位:
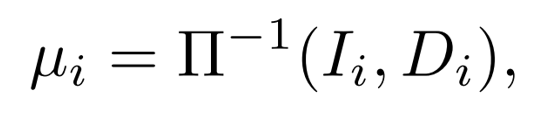
2.2 逐图像预测高斯参数
通过尺度感知定位得到每张图像逐像素三维高斯的位置属性后,还需要预测三维高斯的其他属性,包括尺度属性s,旋转属性r,透明度属性α 和颜色属性c 。研究团队设计了高斯网络预测上述属性,为了更好适应驾驶场景的稀疏环视图像,该高斯网络从每张图像中独立预测高斯属性。
高斯网络由深度编码器E、融合编码器D和对应属性的预测头H组成。其中深度编码器通过深度网络预测的深度提取深度特征:
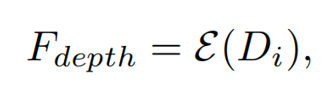
融合编码器将深度特征和深度网络编码的图像特征进行融合,充分利用每张图像的几何和外观信息,得到最终的特征:
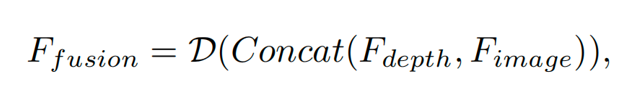
利用融合后的特征,各个属性的预测头分别预测逐像素高斯的对应属性:
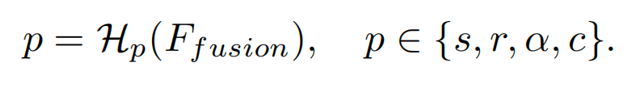
由此,高斯网络预测得到逐像素高斯的其他属性,结合尺度感知定位得到的高斯位置属性,得到完整的逐像素三维高斯。
2.3 联合训练策略
DrivingForward可以端到端训练,包括深度网络、姿态网络和高斯网络,其中高斯网络中融合了深度网络提取的图像特征,有效连接了尺度感知定位和高斯网络的预测。预测的三维高斯通过新视角合成渲染新视角图像,并与真值图像计算损失,损失函数如下:
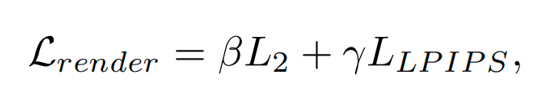
结合尺度感知定位的重投影损失,整个模型的损失函数如下:
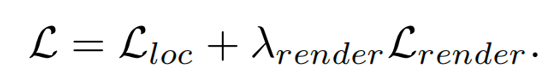
Part 3
结果展示
图3展示了DrivingForward在nuScenes数据集上的新视角合成对比结果,对比方法包括前馈重建方法MVSplat、pixelSplat和逐场景优化的重建3DGS。从图中结果可以看出,DrivingForward减少了新视角的伪影,取得了更好的新视角合成效果。

图3 与其他方法的新视角合成结果对比
图4展示了DrivingForward与其他前馈重建方法在新视角合成上的定量比较结果,可以看出,DrivingForward在多种输入模式(SF单帧,MF多帧)以及多种分辨率下都取得了更好的效果。图5展示了DrivingForward与逐场景优化的方法代表3DGS的定量比较结果,结果显示,在稀疏环视图像的输入下,DrivingForward仅需不到1s的时间即可重建出质量超过3DGS数分钟优化的三维驾驶场景。
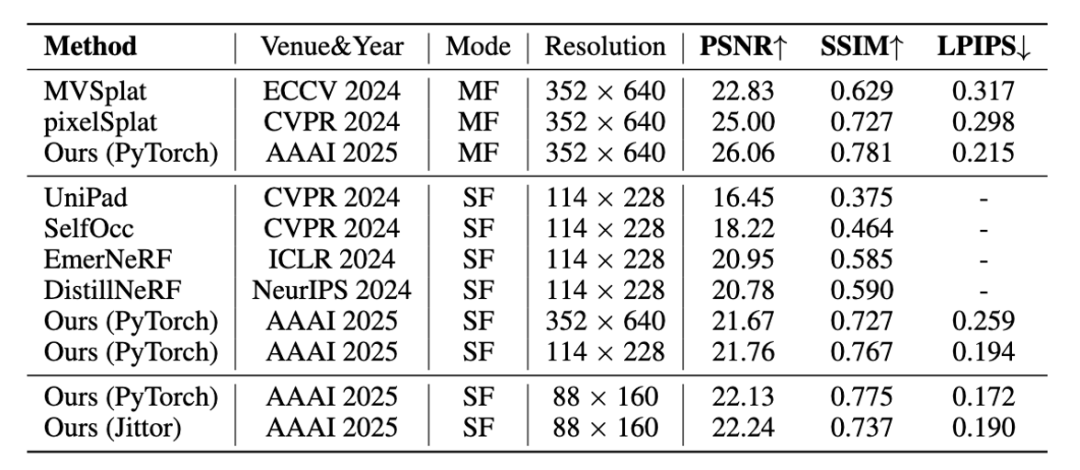
图4 与其他前馈重建方法在新视角合成上的定量比较
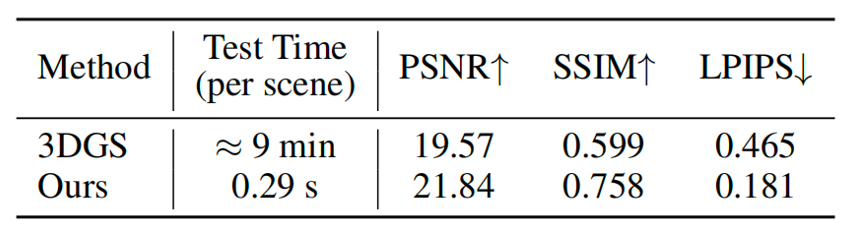
图5 与逐场景优化的3DGS在新视角合成上的定量比较
此外,图6展示了DrivingForward与其他前馈重建方法运行时间与显存的比较,相比于其他方法,DrivingForward实现了较优的训练推理时间与显存占用。DrivingForward训练时仅使用1张48GB的GPU,推理时可在1张24GB的GPU上进行推理。
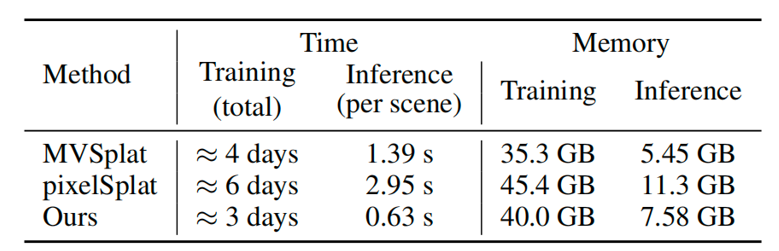
图6 DrivingForward与其他前馈重建方法的运行时间与显存比较
Part 4
计图开源
该项目的计图代码已在Github上开源:
https://github.com/gotyao/DrivingForward_jittor/
项目的主页为:
https://fangzhou2000.github.io/projects/drivingforward/
计图(Jittor) 是清华大学开源的自主深度学习框架,计图完全基于动态编译(Just-in-time),内部使用创新的元算子和统一计算图的深度学习框架,元算子和Numpy一样易于使用,并且超越Numpy能够实现更复杂更高效的操作。而统一计算图则是融合了静态计算图和动态计算图的诸多优点,在易于使用的同时,提供高性能的优化。计图官网为:
https://cg.cs.tsinghua.edu.cn/jittor/
参考文献
Tian Q, Tan X, Xie Y, et al.,Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input, Proceedings of the AAAI Conference on Artificial Intelligence, 2025, 39(7): 7374-7382.
Kerbl B, Kopanas G, Leimkühler T, et al., 3D Gaussian splatting for real-time radiance field rendering, ACM Transactions on Graphics, 2023, 42(4): 139:1-139:14.
Zhou X, Lin Z, Shan X, et al., Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024: 21634-21643.
Yan Y, Lin H, Zhou C, et al., Street gaussians: Modeling dynamic urban scenes with gaussian splatting, European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024: 156-173.
Huang N, Wei X, Zheng W, et al., S3 Gaussian: Self-Supervised Street Gaussians for Autonomous Driving, arXiv preprint arXiv:2405.20323, 2024.
Khan M, Fazlali H, Sharma D, et al., Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction, arXiv preprint arXiv:2407.02598, 2024.
Chen Y, Xu H, Zheng C, et al., Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images, European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024: 370-386.
Charatan D, Li S L, Tagliasacchi A, et al., pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024: 19457-19467.
GGC往期回顾
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
