
ICML 2025: 清华与腾讯、斯坦福等单位合作联合发布大模型复杂推理评测基准RBench
清华大学计图团队和腾讯、斯坦福大学、卡内基梅隆大学、宾夕法尼亚大学、非十科技合作,在ICML 2025发表论文,提出Reasoning Bench(RBench)[1], 一个多学科、多语言的高质量复杂推理评估基准和数据集,兼顾语言模型与多模态模型的评估需求,旨在系统性地衡量大模型的推理能力,并推动其持续演进与优化。
Part 1
研究背景与意义
推理能力是人工智能最核心的基础能力之一,其本质在于智能体能够综合已有知识,在面对复杂或全新的问题时,进行信息整合与逻辑推断,从而做出合理判断并制定有效决策。随着大模型智能水平的持续提升,复杂推理能力开始在模型中逐步涌现,代表性实例包括 OpenAI 的o1和DeepSeek的R1模型。这一趋势标志着大模型在处理高阶认知任务方面迈出了关键一步。
然而,如何科学评估其推理能力,并有效推动推理能力的进一步发展,已成为当前大模型研究领域亟待解决的核心挑战之一。现有的评测数据(Benchmarks)在 OpenAI 推出 o1 之后主要存在以下问题:
OpenAI 发布的 o1 模型在多学科推理任务上表现卓越,在 MMLU [2] 基准上准确率超过 92%,在 MMMU[3] 多模态多学科评测中也已接近甚至达到人类平均水平。这一突破标志着现有主流推理评测基准正逐渐趋于饱和,难以全面揭示大模型在复杂推理中的潜在瓶颈与发展空间。
我们观察到,在 MMLU 与 MMMU 等现有评测基准中,存在大量以知识记忆与识别为主的问题类型,强调对事实性知识的回忆,而对多步推理、逻辑链条构建等高阶推理能力的考查相对不足。这使得它们难以全面反映当前大模型在复杂推理任务中的真实能力。
已有研究尝试借助数学竞赛题来评估大模型的推理能力,但此类题目通常集中于数学单一学科,难以覆盖更广泛的推理场景与知识结构,因此并不能作为全面评测通用推理能力的理想方案。
因此,构建一个全面且具有挑战性的复杂推理评测基准,对于准确评估当前模型的推理能力、识别其潜在不足,并进一步引导推理模型发展,具有重要意义。
RBench的构建
为应对当前缺乏全面且具挑战性的复杂推理评测基准的现状,清华大学计算机系计图团队联合腾讯混元X 团队、斯坦福大学、CMU、宾夕法尼亚大学和非十科技等机构,提出了Reasoning Bench(RBench)[3],一个多学科、多语言的高质量复杂推理评估数据集,兼容语言模型与多模态模型的评估需求,旨在系统性地衡量大模型的推理能力,并推动其持续演进与优化。

图1 RBench 的 logo 示意图
为了构建 RBench,我们系统调研了清华大学数学系、物理系、化学系、计算机系、电子工程系等19个院系的本硕课程体系,深入分析各专业的教学内容与能力要求。同时,我们招募超过50名志愿者,协助收集各专业中具有代表性的“复杂推理”类题目,例如考试中的压轴题、课后作业中的高难度问题,排除了以知识记忆或概念识别为主的题目,确保所选题目更侧重推理链条的构建与问题解决能力的考查。除了人工筛选,我们还进行了题目数字化、模型筛选、选项构造等过程,题目的收集、筛选和构造的详细过程如图2 所示。
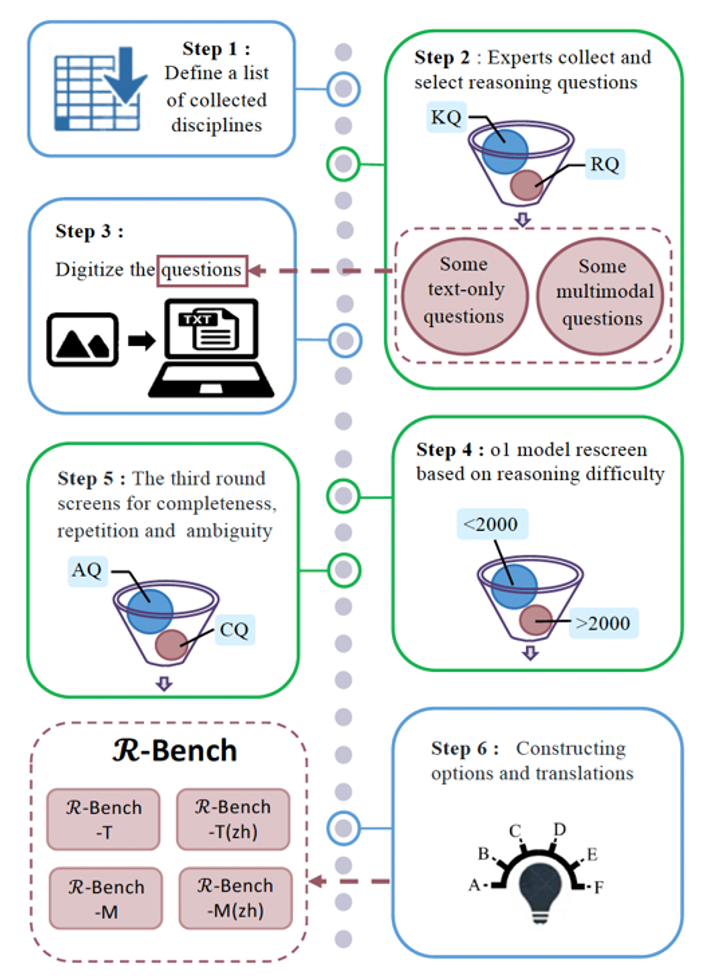
图2 RBench 中题目的收集、筛选和构造过程
据 RBench 的统计,该基准测试涵盖数学、物理学、化学、生物学、计算机科学和材料等19 个院系,涉及无机化学、化学反应动力学和电磁学等 100 多个学科。它有 1,094 个问题用于测试语言模型,665 个问题专门用于评估多模态推理能力。同时,这些题目均有中英文两个版本,以测试模型的跨语言能力。
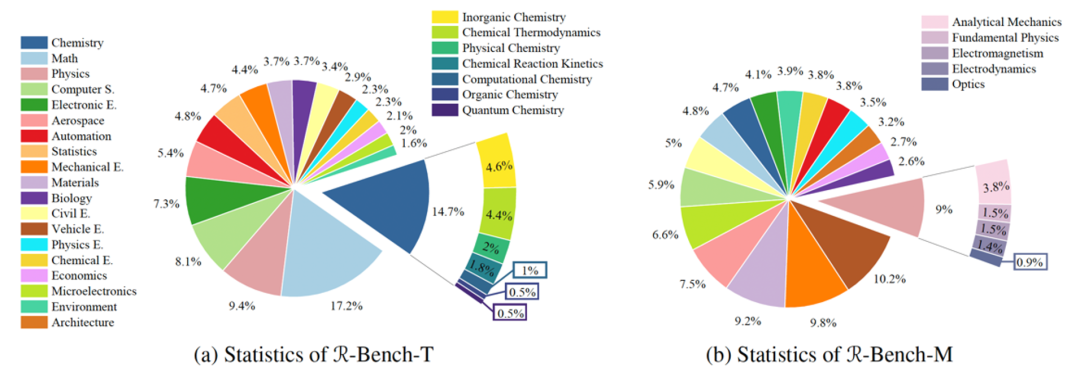
图3 RBench 中题目分布统计示意图
下图给出了 RBench 中的题目示例:
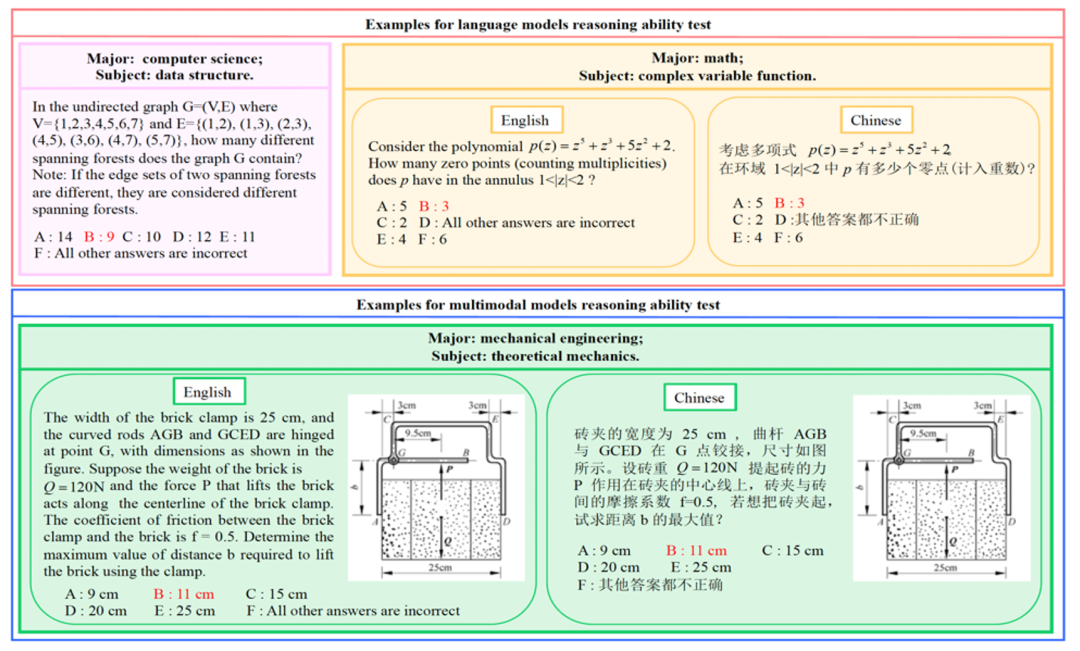
图4 RBench 中的题目示例
实验与结果
首先,为了证明 RBench是一个针对复杂推理评测的数据集,我们做了用户实验,让领域专家去判断MMLU / MMMU / RBench 中题目对复杂推理题目的要求,实验结果在表1 中展示。
表1 RBench / MMLU / MMMU 上的用户实验
用于比较不同Benchmark 对复杂推理的要求
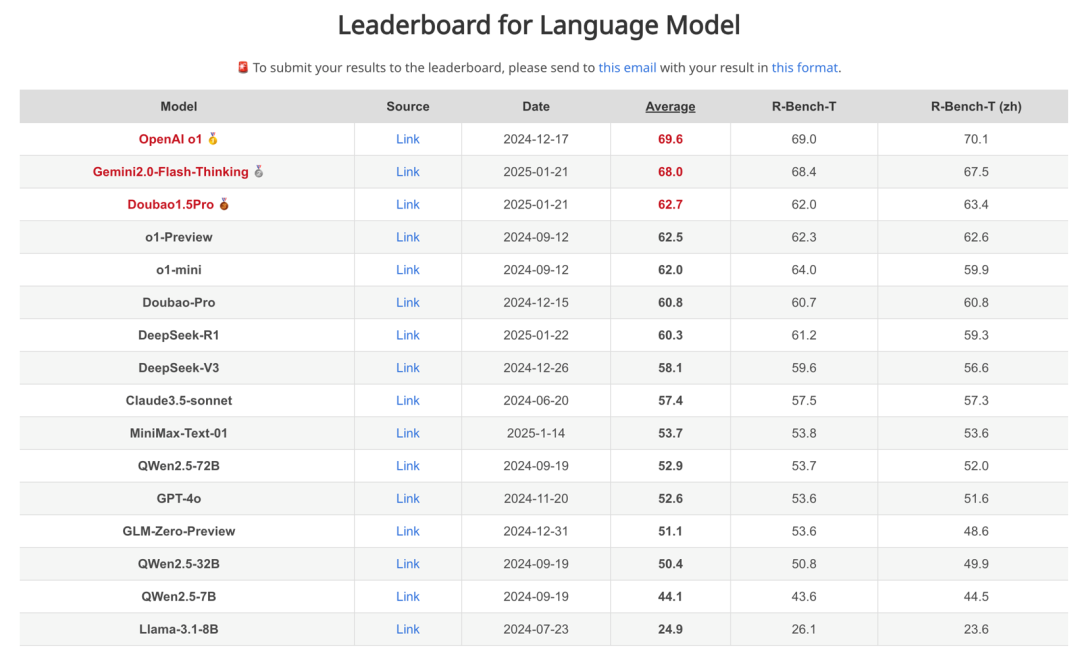
图5: RBench 上不同语言模型分数与排名,zh 表示中文
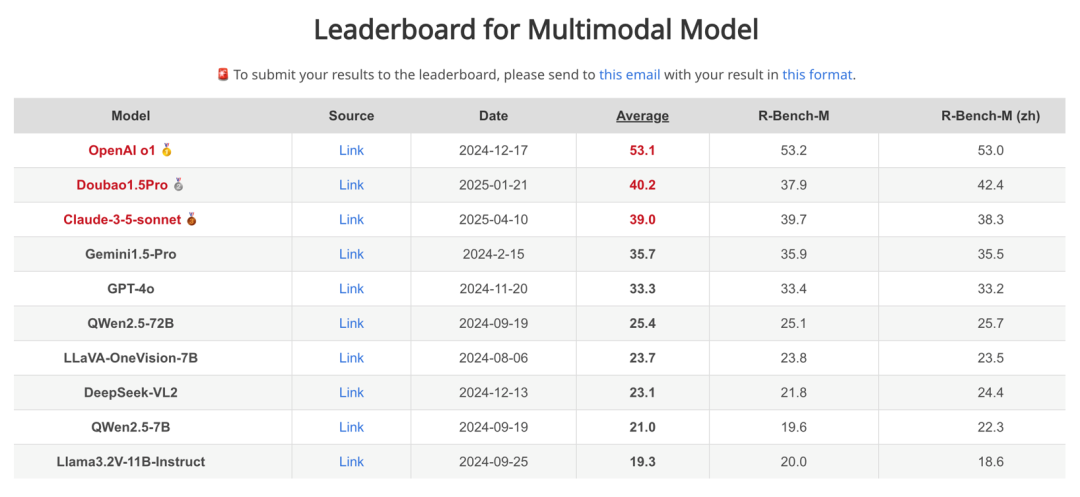
图6: RBench 上多模态模型的分数与排名,zh 表示中文
项目与开源
目前,该项目中所有使用的数据已经在huggingface 上开源,地址为:
https://huggingface.co/datasets/R-Bench/R-Bench
关于项目的更多信息,请访问项目官网:
https://evalmodels.github.io/rbench/
论文链接:
https://arxiv.org/pdf/2505.02018
参考文献
Meng-Hao Guo, Jiajun Xu, Yi Zhang, Jiaxi Song, Haoyang Peng, Yi-Xuan Deng, Xinzhi Dong, Kiyohiro Nakayama, Zhengyang Geng, Chen Wang, Bolin Ni, Guo-Wei Yang, Yongming Rao, Houwen Peng, Han Hu, Gordon Wetzstein, Shi-min Hu. RBench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation. preprint arXiv 2505.02018
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt, Measuring Massive Multitask Language Understanding, ICLR 2021, https://openreview.net/forum?id=d7KBjmI3GmQ
Yue X, Ni Y, Zhang K, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 9556-9567.
2. 计图团队完成华为昇腾上 DeepSeek 模型的高效适配
3. 三维透明物体重建的网格-神经混合表示 | CVMJ Spotlight
4. Computational Visual Media第11卷第1期导读
5. 计图开源:轻量级遥感骨干网络LSKNet和Strip R-CNN
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
