
计图团队完成华为昇腾上 DeepSeek 模型的高效适配
近年来,随着大语言模型在智能问答、代码生成等任务中的广泛应用,如何在国产算力平台上实现对其的高效部署,已成为推动人工智能自主创新生态建设的关键课题。计图团队持续深入探索国产软硬件协同优化的技术路径,在成功适配华为昇腾910系列AI处理器的基础上,取得两点重大进展:
首次实现单台华为8卡服务器上的deepseek R1的推理。
Deepseek V2的推理性能比 vLLM(Ascend 版本)在不同请求下,平均提升53%以上。
此项工作,进一步推进对 DeepSeek 系列大模型在昇腾平台上的高性能适配与加速优化,为国产大模型在国产硬件上的落地应用提供了技术支撑。

由DeepSeek V2、DeepSeek V3、DeepSeek R1 等模型构成的 DeepSeek 大模型家族,自发布以来便受到了学术界与工业界的广泛关注。这一系列模型在日常对话、复杂问题推理、代码生成等多个核心任务上展现出卓越能力。尤其值得一提的是,DeepSeek模型不仅在多个评测基准上实现领先性能,还坚持开源的路线,极大地推动了国内大模型社区的发展与应用生态的繁荣。
在模型能力突飞猛进的同时,围绕其推理效率与部署灵活性的研究也日益成为业界关注焦点,涌现出以vLLM 等为代表的一系列高性能推理框架。vLLM是一个基于 PyTorch 构建的开源推理框架,专为大语言模型的高效推理而设计。凭借卓越的性能与易用性,vLLM 已成为当前最受欢迎的开源大模型推理解决方案,在 GitHub 上收获了超过 4 万颗星标。
然而,其优化主要针对于英伟达的 CUDA 生态,存在对国外硬件平台依赖强、适配国产硬件成本高等问题,制约了大模型在国产算力平台上的规模化部署能力。
与此同时,以华为昇腾为代表的国产AI 芯片在计算性能、系统软件栈和生态建设等方面持续取得突破,构建“全栈国产”的 AI 技术体系已具备可行性。越来越多的高校与研究机构将目光投向了“国产大模型 × 国产软件 × 国产算力”的深度融合实践,探索真正自主可控的智能计算解决方案。
在这一背景下,清华大学计图团队发起本项目,围绕DeepSeek 系列大模型开展全面的国产化适配工作,依托计图框架,致力于打通大模型国产芯片部署的全栈技术;构建安全可控、性能优越的大模型国产部署解决方案。
计图团队在推动 DeepSeek 模型适配华为硬件平台的过程中,面临了一系列复杂而严峻的挑战:
首先,作为最优秀的国产芯片,华为芯片的生态系统仍处于持续完善阶段,与NVIDIA的相比,在生态上还有差距,这增加了适配工作的不确定性和难度。
其次,华为设备上CPU性能是大模型适配的一个技术瓶颈,在英伟达设备上的优化经验难以直接应用于华为设备。
最后,当前主流模型在设计之初,多基于 A100、H20、H200等英伟达设备的强大算力与充足显存进行考量。然而,华为设备的显存相对较小,这导致模型在运行过程中频繁出现显存不足的问题,为优化工作带来了额外的困难。
计图团队经过不懈努力,克服了上述困难,完成了DeepSeek V2 Lite(16B)、DeepSeek V2(236B)以及DeepSeek R1(671B)模型在华为昇腾硬件平台上的适配与性能优化。主要的适配和优化工作包括:
算子实现 :实现华为芯片上的DeepSeekMoE (直接实现版本和fused版本)、具有外扩功能的旋转编码(RoPE: Rotary Position Embedding),并进行算子实现层面的优化与量化。
内存布局:实现基于矩阵吸收的MLA,大幅减少模型显存占用。
并行策略:包括实现华为芯片上的张量并行、专家并行和数据并行等关键环节的并行优化
服务端优化:通过加速 continuous batching 机制,有效提升高并发场景下的推理吞吐与响应效率。
该推理框架的主要亮点在于:
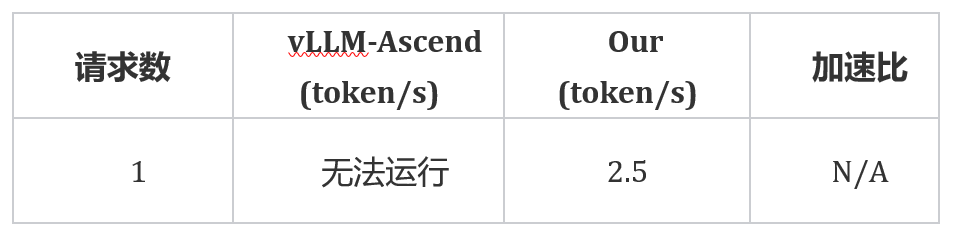
通过对模型算子权重进行 Int4 量化优化,显著降低了显存占用,为资源受限环境下的大模型部署提供了有效解决方案,成功实现了对 DeepSeek R1 模型在单机 8 卡昇腾硬件上的部署。
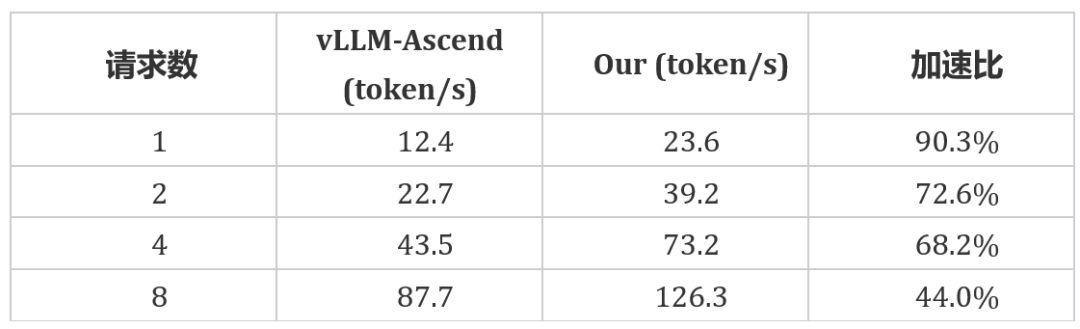
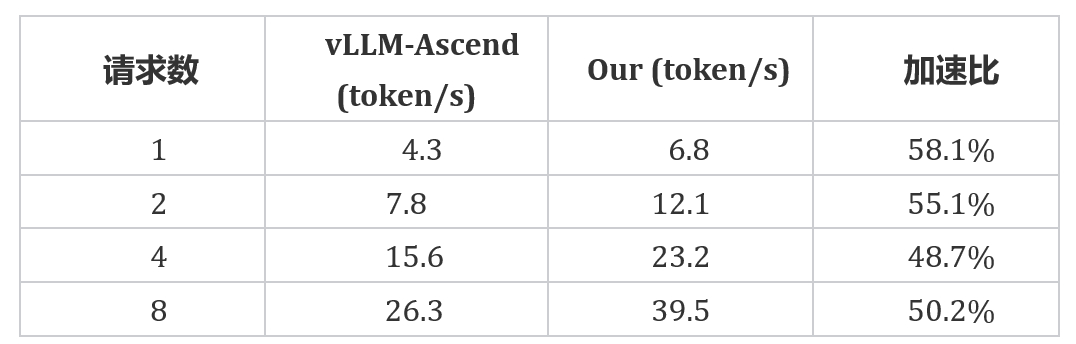
实测数据表明,相比主流开源推理框架 vLLM(Ascend 版本),该框架运行 DeepSeek 系列模型的推理速度提升显著,针对不同的请求数,性能增幅达44.0% - 90.3%, 展现出强大的性能优势。
自主可控,本推理框架不依赖 Pytorch,是一套自主可控的优化方案。
下面展示了计图团队开发的推理框架与 vLLM 在不同模型上的推理速度对比,以及相关的运行效果。
华为 910系列-单卡DeepSeek V2-Lite 模型与vLLM 的速度对比
华为 910系列-单卡运行DeepSeek V2-Lite 模型视频示例
华为910系列-单机(8卡)DeepSeek V2模型与 vLLM 的速度对比
华为910系列-单机(8卡)运行 DeepSeek V2模型视频示例
华为 910系列-单机(8卡)运行 DeepSeek R1 速度
华为 910系列-单机(8卡)运行DeepSeek R1模型视频示例
计图团队希望通过本项目,助力华为昇腾的AI基础软硬件平台。后续,我们将开源相关技术,也期待能和学术届和工业界的同仁一起努力,为国产人工智能生态的发展做出应有的贡献。
感谢南开大学程明明教授机器团队对本项目提供的大力支持,其中,焦鹏屹、陈佳博、向东和朱子轩同学在模型调试与实验验证过程中的做出了重要贡献,他们的贡献为项目的顺利推进发挥了关键作用。
感谢Deepseek开源项目对大模型技术的巨大推动作用。特别感谢华为海思研发团队的领导和技术专家对此次Deepseek系列大模型的昇腾适配提供的指导、技术支持与帮助。感谢清华-华为鲲鹏昇腾卓越中心提供算力的支持。此外,项目实现过程中参考了GGML 和 llama.cpp 的算子实现,感谢ggml-org社区的优秀开源项目。
1. 三维透明物体重建的网格-神经混合表示 | CVMJ Spotlight
2. Computational Visual Media第11卷第1期导读
3. 计图开源:轻量级遥感骨干网络LSKNet和Strip R-CNN
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
