
计图开源:单张图像的三维人体网格重建

图1
MultiROI-HMR与SOTA方法的定性对比

图2 Meta-HMR与SOTA方法的定性对比
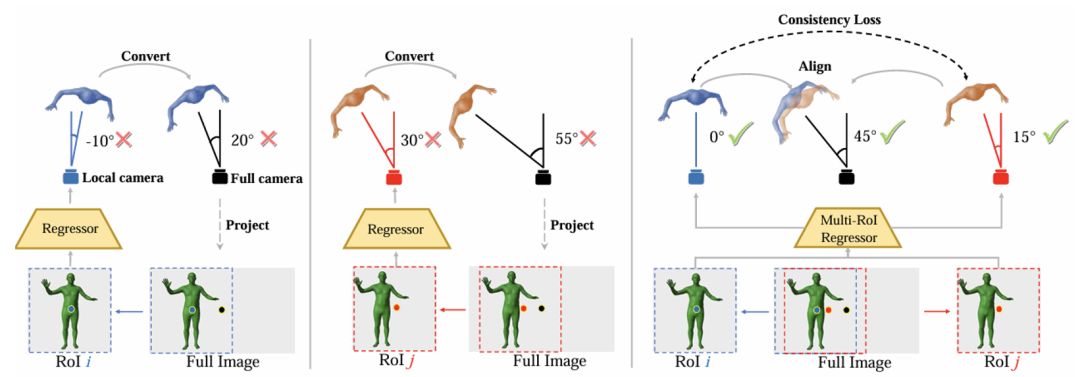
图3 Multi-ROI多ROI示意图
如图3左侧所示,从局部 Rol i 来看,正确的局部相机是0°,然而回归器可能错误地将其预测为-10°,进而在局部相机转化为全局相机时,得到错误的20°全局相机,而不是真值45°。 图3中间展示了另一个局部Rol j。此时回归器估计得到30°的局部相机,并转化为55°的全局相机,同样不是真值45°。图3右侧,本文提出的MultiROI-HMR通过维持全局相机的一致性对模型进行约束,即RoI i 和 RoI j 应该估计出同样的全局相机, 来达到更好的效果, 更多详细信息请参考论文。
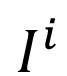 ,MultiROI-HMR首先提取出M个边界框
,MultiROI-HMR首先提取出M个边界框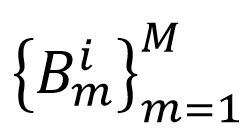 获取ROI(Region Of Interest)
获取ROI(Region Of Interest) 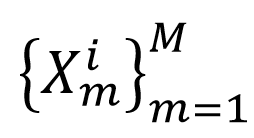 ,然后使用一个视觉骨干网络分别提取特征
,然后使用一个视觉骨干网络分别提取特征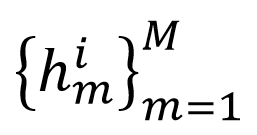 ,这些特征再通过一个 ROI融合模块,得到融合后的特征
,这些特征再通过一个 ROI融合模块,得到融合后的特征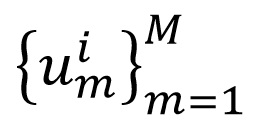 和全局特征
和全局特征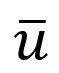 (见图4)。每个融合后的特征都会经过共享的解码器(称之为"相机"解码器)预测出不同的相机参数,全局特征则经过mesh解码器预测出人体的姿势和形状。整个回归任务可以被公式化为
(见图4)。每个融合后的特征都会经过共享的解码器(称之为"相机"解码器)预测出不同的相机参数,全局特征则经过mesh解码器预测出人体的姿势和形状。整个回归任务可以被公式化为
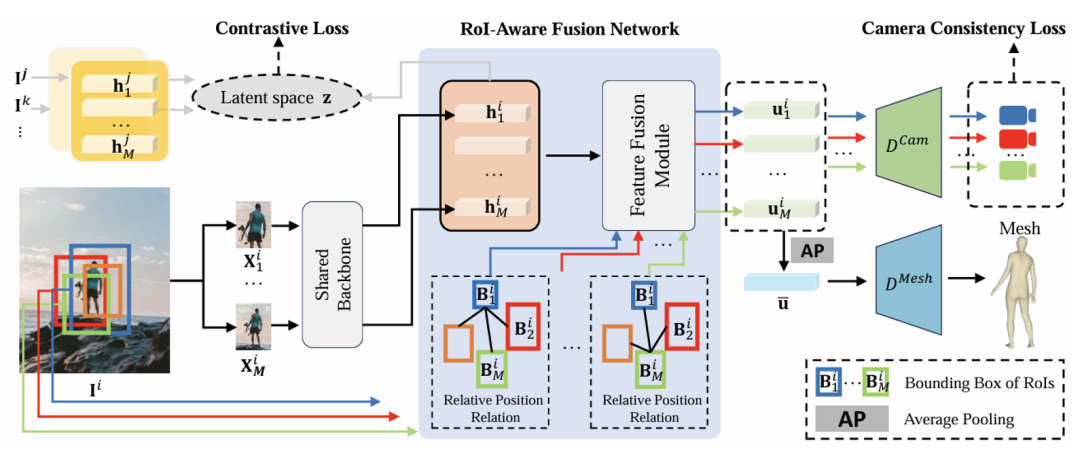
图4 MultiROI-HMR模型架构
总体上,不同于CLIFF[4]只使用了一个边界框,MultiROI-HMR使用多个边界框作为输入。由于每个边界框对应的局部相机应该转换为相同的全局相机,因此可以使用相机间的两两相互关系,构建一致性相机参数损失,来引导模型学习正确的网络参数。为保持相机之间的全局一致性, MultiROI-HMR提出相应的损失函数:
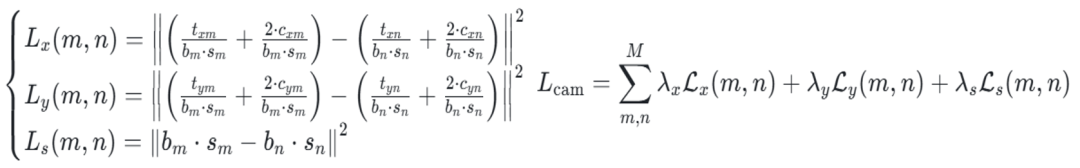
图5展示了局部相机到全局相机的转换过程。
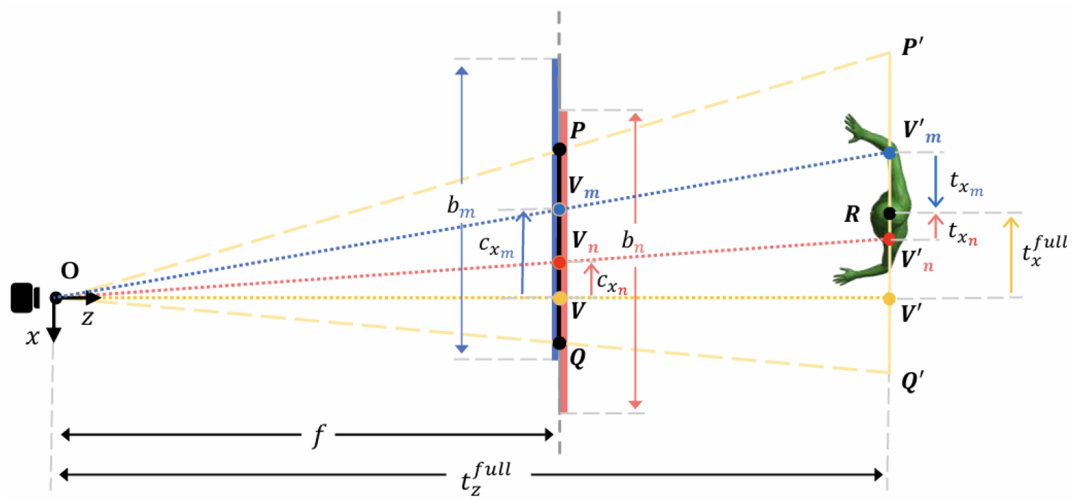
表1
MultiROI-HMR与SOTA方法的定量比较
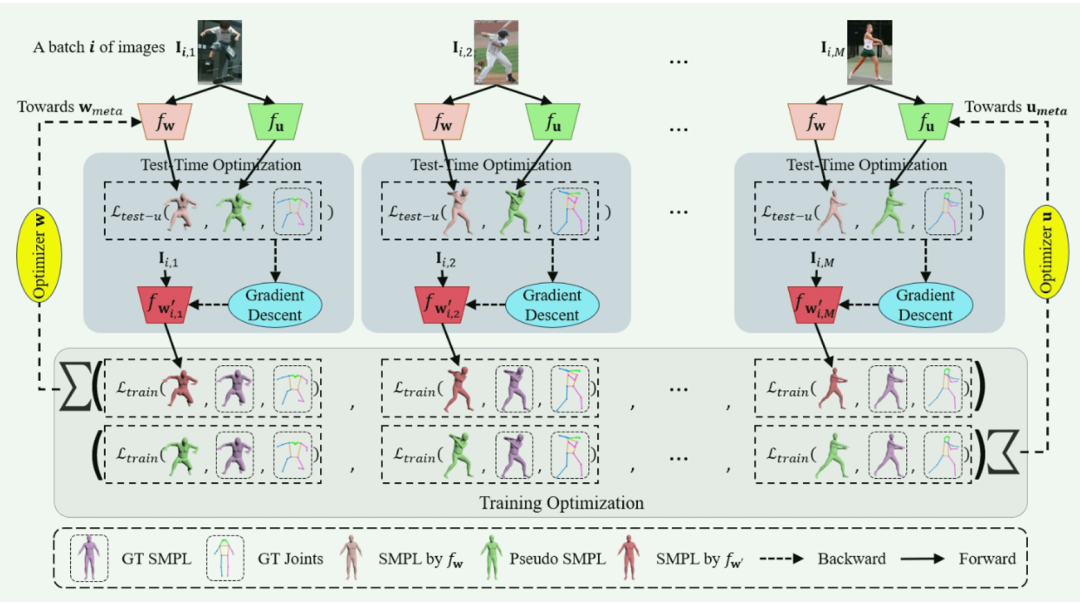
图6
Meta-HMR模型架构
令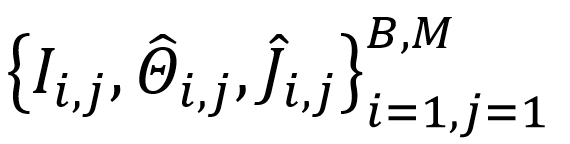 为训练数据集,
为训练数据集,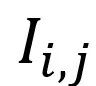 为训练图片,
为训练图片, 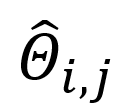 为真值mesh,
为真值mesh, 
为2D真值骨骼或者由SOTA人体姿态算法检测到2D关键点,B是batch的数量,M是batch的大小。端到端的回归方法通常是训练一个神经网络
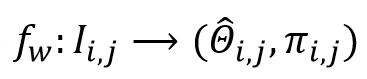 .
.
并最小化训练时损失函数(training-time
loss function)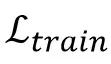 :
:
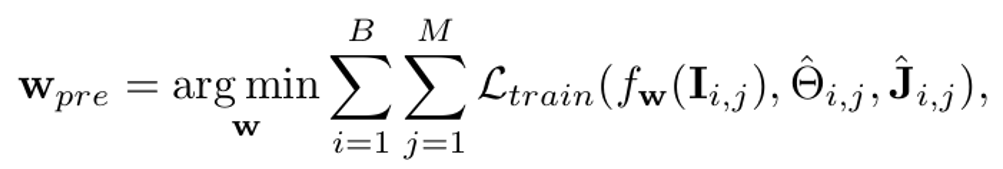
测试时,在每一个测试样例上使用测试时损失函数(test-time loss function)进一步微调预训练网络
其中
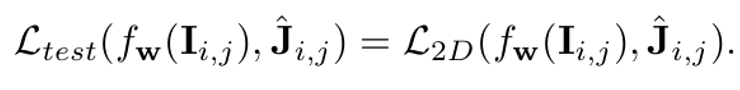
为了将测试时优化插入到训练过程中,Meta-HMR首先对于一个批次中的每一个样本(共M个)执行测试时优化去更新和这个样本相关的回归模型的参数,然后在M个样本上训练得到优化后的参数。这个过程可以公式化为:

其中,
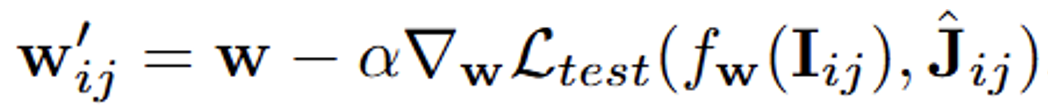
此外,训练时有真实的人体mesh作为监督,而测试时没有人体mesh真值可以使用,导致 中可以计算3D损失函数
中可以计算3D损失函数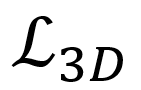 ,而
,而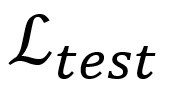 不能,造成某种程度的不一致。为弥补这一点, Meta-HMR通过引入一个辅助回归网络
不能,造成某种程度的不一致。为弥补这一点, Meta-HMR通过引入一个辅助回归网络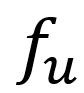 估计一个伪真值人体mesh,从而统一训练时和测试时优化目标:
估计一个伪真值人体mesh,从而统一训练时和测试时优化目标:
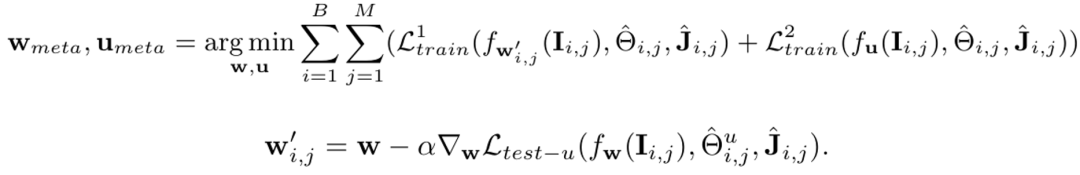
表2
Meta-HMR与SOTA方法的定量比较

对于MutilROI-HMR,在推理阶段,固定批次大小(batch size)为100,评估数据集为3DPW, Jittor版本推理用时约78s, PyTorch版本用时约105s. 推理速度提升25.7%.
Nie, Y., Liu, C., Long, C., Zhang, Q., Li, G., & Cai, H, Multi-RoI Human Mesh Recovery with Camera Consistency and Contrastive Losses. European Conference on Computer Vision,2024,439-458.
Nie, Y., Fan, M., Long, C., Zhang, Q., Zhu, J., & Xu, X., Incorporating Test-Time Optimization into Training with Dual Networks for Human Mesh Recovery. The Thirty-eighth Annual Conference on Neural Information Processing Systems,2024.
Kanazawa, A., Black, M. J., Jacobs, D. W., & Malik, J., End-to-end recovery of human shape and pose. IEEE/CVF conference on computer vision and pattern recognition, 2018, 7122-7131.
Li, Z., Liu, J., Zhang, Z., Xu, S., & Yan, Y., Cliff: Carrying location information in full frames into human pose and shape estimation. European Conference on Computer Vision, 2022, 590-606.
Joo, H., Neverova, N., & Vedaldi, A., Exemplar fine-tuning for 3d human model fitting towards in-the-wild 3d human pose estimation. International Conference on 3D Vision (3DV), 2021, 42-52.
Kolotouros, N., Pavlakos, G., Black, M. J., & Daniilidis, K., Learning to reconstruct 3D human pose and shape via model-fitting in the loop, IEEE/CVF international conference on computer vision, 2019, 2252-2261.
GGC往期回顾
1. 计图开源:图机器学习库
3. 张量场引导的机器人分层路径规划与自主探索 | CVMJ Spotlight
4. 跨模态增强的长尾图像分类 | CVMJ Spotlight
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
