
计图开源:基于扩散模型的语音驱动风格化人脸动画生成
近日,北京交通大学CLIA实验室温玉辉副教授等与清华大学刘永进教授、天津大学余旻婧副教授合作,开源了基于计图(Jittor)深度学习框架实现的DiffPoseTalk版本。Jittor版本取得了与PyTorch版本同等质量的生成结果,但是所需的扩散模型去噪生成过程时间较PyTorch版本更短,推理速度是PyTorch版本的1.69倍。
Part1
问题和背景
语音驱动的 3D 人脸动画生成在教育、客服、娱乐等领域有丰富的应用场景,近年来受到来自学术界和工业界的关注。这是一个具有高度挑战性的研究问题,因为其涉及语音和3D人脸动画之间的跨模态多对多映射关系。现有方法大多采用确定性的回归模型学习这一关系,生成的嘴唇动画幅度偏小且过于平滑,同时还缺乏伴随讲话的其他面部动作。此外,大部分方法采用训练集人物的one-hot 编码来表示风格,限制了它们基于新的风格进行生成的能力。
为了解决上述局限性和挑战,作者提出了DiffPoseTalk方法,充分利用了扩散模型这一概率模型对各种形式数据分布的模拟能力,并进行了针对性的设计,用于生成与语音匹配的多样且高质量的风格化人脸动画。具体来说,DiffPoseTalk利用预训练的 HuBERT [2]模型提取鲁棒且上下文丰富的语音特征,并基于注意力架构对齐语音和运动模态。此外,采用对比学习训练风格编码器,从任意参考动画提取讲话风格,并在推理时通过classifier-free guidance 进行风格引导。此外,设计了窗口机制和相应的训练策略以支持任意长度的音频输入。除面部表情外,DiffPoseTalk额外预测了头动并设计了相应的损失函数以获得自然的结果。为克服语音-人脸动画的3D 扫描数据的稀缺,作者收集并构建了一个包含不同说话风格和头部动作的语音-人脸动画数据集。DiffPoseTalk基于扩散模型的语音驱动动画生成系统示意图如图1所示。
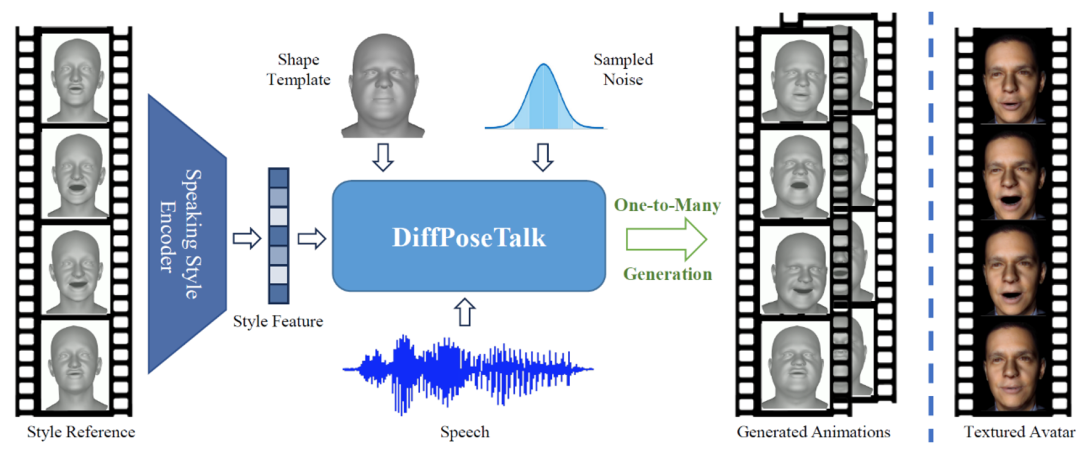
图 1 DiffPoseTalk的示意图
Part2
方法概述
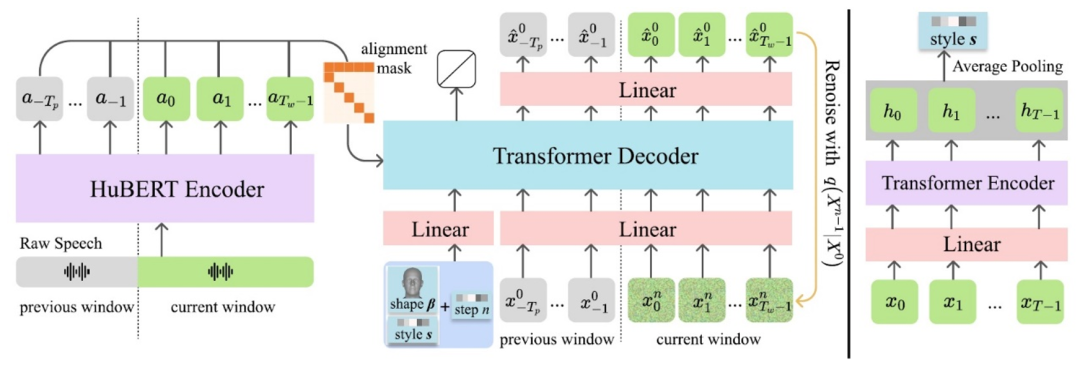
图 2 DiffPoseTalk模型框架图
DiffPoseTalk 是基于条件扩散模型的方法。在去噪网络中,采用了预训练的HuBERT 模型提取语音特征,并使用一个 Transformer 解码器迭代地进行去噪。此外,使用了对齐掩码来对齐语音与运动模态,使得某一时刻的运动特征仅与该时刻的语音特征关联。为了支持任意长音频的输入,对输入进行了分窗处理,并将上一个窗口的结尾部分作为去噪网络的输入,以保持帧间连续性。为了能够施加传统的几何约束,在去噪过程中预测干净样本而非添加的噪声。
为了实现基于样例的风格控制,引入了一个从讲话的动作序列提取讲话风格的编码器。讲话风格是一个多方面的属性,表现在诸如嘴巴张开的大小、面部表情的动态变化和头动习惯等,难以被定量描述。因此,作者采用对比学习的方法,隐式地学习讲话风格的特征表示。基于同一个人在两个相近时间点的短时演讲风格相似的假设,采用NT-Xent损失训练编码器。
Part3
结果展示

图 3 DiffPoseTalk与不支持头动生成的SOTA 方法定性比较结果

图 4 DiffPoseTalk与支持头动生成的SOTA 方法定性比较结果
DiffPoseTalk与其他 SOTA 方法定量比较的结果如表1所示。采用唇顶点最大误差 (LVE)、上半脸动态偏差 (FDD)、嘴巴开口差异 (MOD) 与头动节拍对齐 (BA) 来评价方法的唇形同步性和表情、运动风格与真值的差异。此外,该研究测试了在相同输入下生成结果的多样性。DiffPoseTalk在所有指标上都优于其他SOTA方法,取得了最佳的唇形同步和头动节拍对齐结果。FDD、MOD和BA指标表明DiffPoseTalk有效地捕捉了说话风格。同时,DiffPoseTalk也具备最高的生成多样性。其他方法除了SadTalker[3](从VAE中采样头部运动)和FaceDiffuser[4]之外,都采用了确定性方法进行运动生成,因此无法在相同输入下生成不同的运动。因此,DiffPoseTalk最有效地建模了语音和人脸动画之间的多对多映射。消融实验也证明了DiffPoseTalk各个模块设计的有效性。
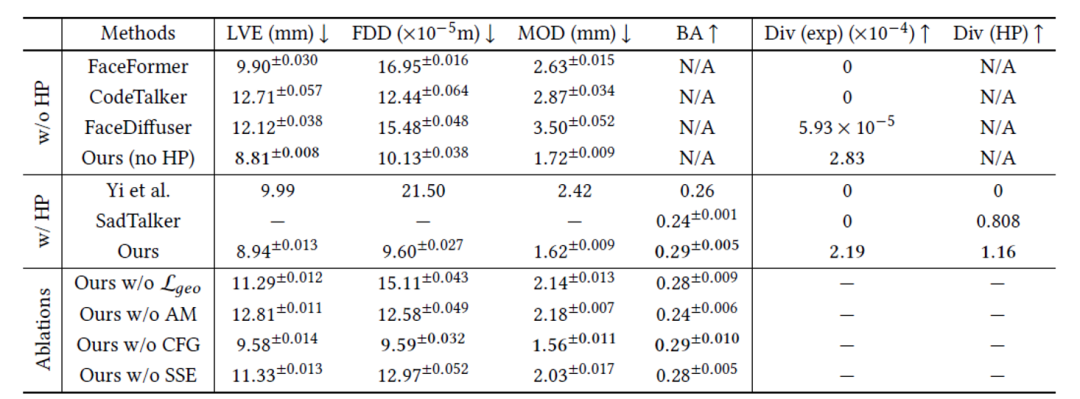

图 5 DiffPoseTalk可以驱动参数化人脸形象,生成逼真的视频
Part4
计图开源
https://github.com/3DHCG/Jittor_DiffPoseTalk
基于Jittor实现的代码,语音驱动人脸动画得到3DMM人脸模型参数可以达到30fps,推理速度是PyTorch版本的1.69倍。项目的主页为:
https://diffposetalk.github.io/
Jittor版本代码实现由北京交通大学CLIA实验室和清华大学刘永进教授团队联合发布,由计图团队提供技术支持。
Sun, Zhiyao, et al., Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models, ACM Transactions on Graphics, 2024, Vol. 43, No. 4, Article no. 46,1-9.
Van Niekerk, Benjamin, et al., A comparison of discrete and soft speech units for improved voice conversion, IEEE International Conference on Acoustics, Speech and Signal Processing, 2022, 6562-6566.
Zhang, Wenxuan, et al., Sadtalker, Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, 8652-8661.
Stan, Stefan, Kazi Injamamul Haque, and Zerrin Yumak, Facediffuser: Speech-driven 3d facial animation synthesis using diffusion, Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games, 2023, Article no. 13, 1-11.
Qian, Shenhan, et al., Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, 20299-20309.
1. Computational Visual Media第10卷第4期导读
可通过下方二维码,关注清华大学图形学实验室,了解图形学、深度学习、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
