
计图开源:动态人体渲染算法库
Part1
问题和背景
基于Jittor深度学习框架的JNeRF,提供了一个统一、高效的模型库,能够有效提升科研效率。然而,面对包含复杂运动的动态人体场景,现有模型库仍面临诸多挑战。为解决以上问题,清华大学和北京交通大学团队基于Jittor深度学习框架开发了动态人体渲染算法库(JDHR),该算法库充分利用了Jittor框架的性能优势,通过实现点云采样、4D特征网格表示及实时渲染技术,有效解决了动态人体渲染中的难题。可以广泛应用于虚拟现实、游戏开发、电影特效和视频会议等领域。
Part2
动态人体渲染算法库(JDHR)
点云采样模块
点云采样模块从多视角视频中获得初始点云。使用分割方法来获取输入图像中的动态人体掩膜[3],得到前景图像和初始几何[4]。基于JNeRF在这些图像上训练,获得视频序列每一帧 t 的三维人体初始点云 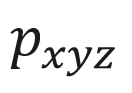 。
。
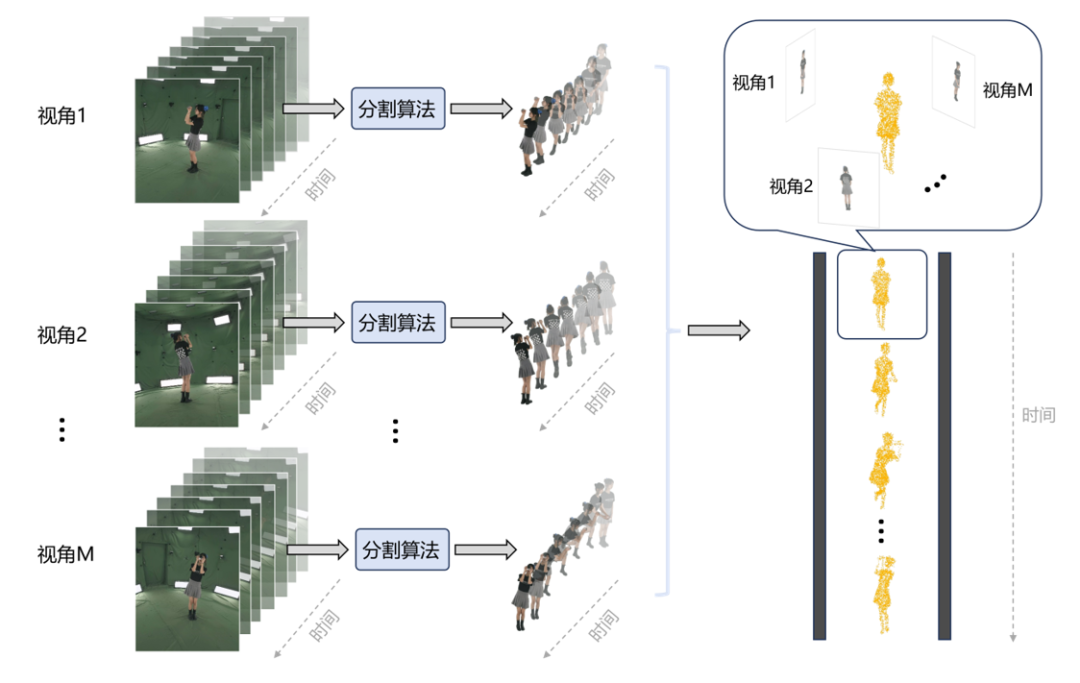
图2 点云采样模块示意图
4D特征网格表示模块
 、半径
、半径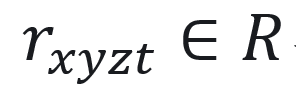 、密度
、密度 、球谐系数
、球谐系数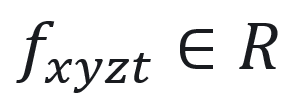 、数外观特征
、数外观特征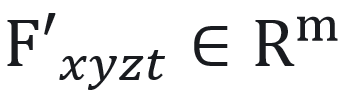 。具体而言,使用4D特征网格
。具体而言,使用4D特征网格 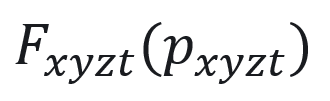 来学习动态人体高斯球表示,并且将4D特征网格分解为4个3D和4个1D特征网格实现时空特征高效表示学习[6]:</img>
来学习动态人体高斯球表示,并且将4D特征网格分解为4个3D和4个1D特征网格实现时空特征高效表示学习[6]:</img>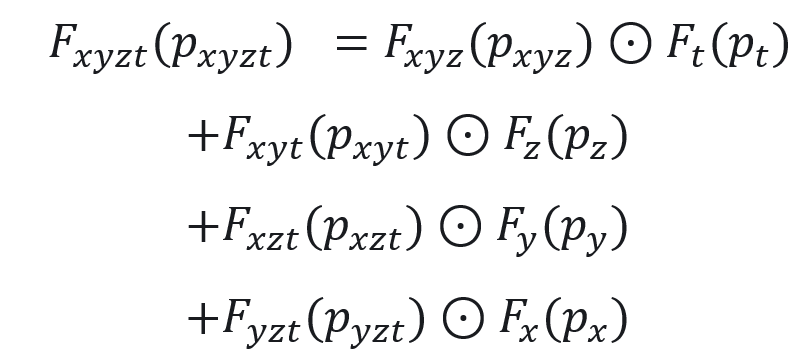
其中, 表示哈达玛乘积。每个3D特征网格
表示哈达玛乘积。每个3D特征网格 </img>
</img>
使用多尺度哈希网格来表示。1D特征网格使用密集向量表示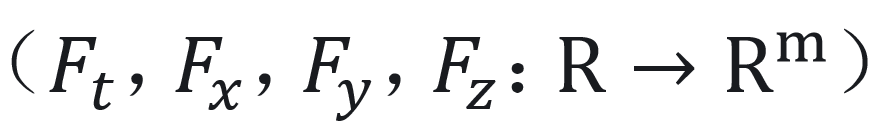 。然后,将特征向量
。然后,将特征向量 输入MLP后,可以预测出高斯球的半径
输入MLP后,可以预测出高斯球的半径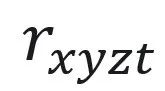 、密度
、密度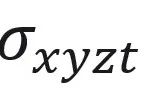 ,外观特征
,外观特征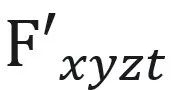 。
。
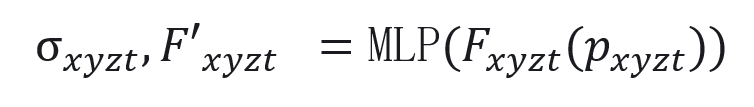
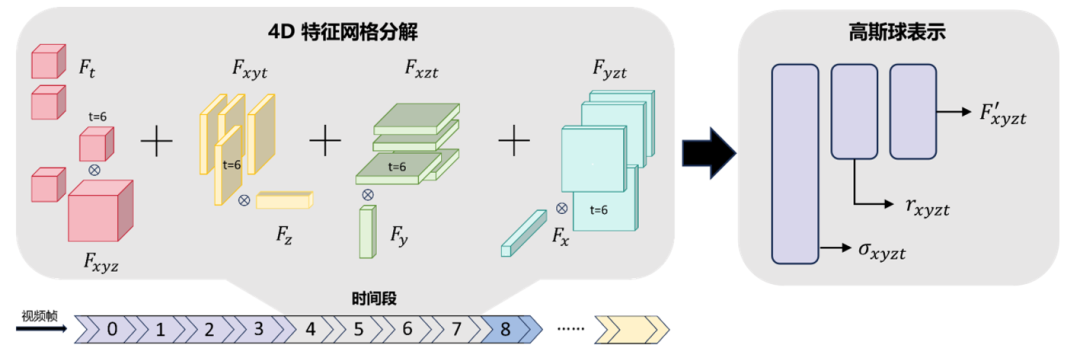
图3 4D网络特征表示模块示意图
实时渲染模块
给定图像像素的位置,可以通过视图变换W计算出它与高斯球的距离,这些距离代表各个高斯的深度,从而形成一个排序后的高斯列表N。然后,利用密度合成来计算该像素的最终颜色。
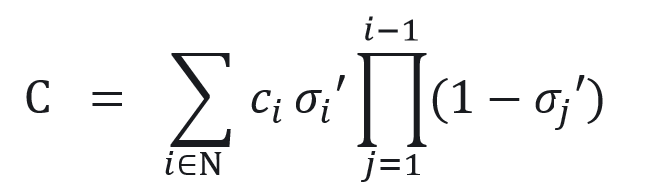
其中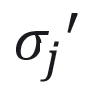 由学习到的密度σ 在像素位置投影的第 i 个二维高斯概率密度的权重加权得到。
由学习到的密度σ 在像素位置投影的第 i 个二维高斯概率密度的权重加权得到。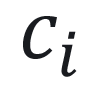 是球谐函数输出的颜色和外观特征的混合。为了降低为每个像素逐一计算有序列表所带来的高昂计算成本,借助3DGS思想,将精度从像素级别转移到块级别。具体而言,将图像分割成多个互不重叠的图像块,并基于这些图像块实现了快速的并行化渲染。基于Jittor深度学习框架实现的动态人体渲染算法,能够达成实时高分辨率图像的渲染效果。在采用单块NVIDIA 3090显卡的情况下,渲染2024*2448分辨率的动态人体,峰值信噪比(Peak
Signal-to-Noise Ratio, PSNR)为32.29,帧率约为30fps。</img>
是球谐函数输出的颜色和外观特征的混合。为了降低为每个像素逐一计算有序列表所带来的高昂计算成本,借助3DGS思想,将精度从像素级别转移到块级别。具体而言,将图像分割成多个互不重叠的图像块,并基于这些图像块实现了快速的并行化渲染。基于Jittor深度学习框架实现的动态人体渲染算法,能够达成实时高分辨率图像的渲染效果。在采用单块NVIDIA 3090显卡的情况下,渲染2024*2448分辨率的动态人体,峰值信噪比(Peak
Signal-to-Noise Ratio, PSNR)为32.29,帧率约为30fps。</img>
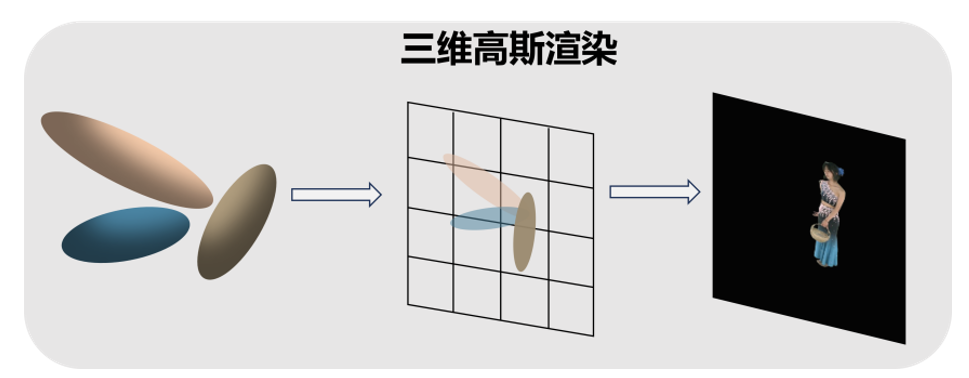
图4 实时渲染模块示意图
Part3
计图开源与后续计划
JDHR代码已开源在:
https://github.com/3DHCG/JDHR
Sun Z, Lv T, Ye S, et al., Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models, ACM Transactions on Graphics, 2024, Vol. 43, No. 4, article no. 46.
Ye S, He Y, Lin M, et al., PVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction, ACM SIGGRAPH ASIA, 2024.
Ravi, Nikhila, et al., Sam 2: Segment anything in images and videos, arXiv preprint arXiv:2408.00714, 2024. Kutulakos, Kiriakos N., and Steven M. Seitz, A theory of shape by space carving, International journal of computer vision, 2000, Vol. 38, 199-218.
Kerbl, Bernhard, et al., 3D Gaussian Splatting for Real-Time Radiance Field Rendering, ACM Transactions on Graphics, 2023, Vol. 42, No. 4, article no.139.
Işık, Mustafa, et al., Humanrf: High-fidelity neural radiance fields for humans in motion, ACM Transactions on Graphics, 2023, Vol. 42, No. 4, article no.160.
3. 计图开源:高斯网—可建模大尺度几何变形的新型高斯泼溅表示方法
4. 童欣、Minhyuk Sung分获亚洲图形学学会2024年度两项大奖
