
计图开源:感知、预测、端到端自动驾驶算法库(JAD)
Part1
自动驾驶的背景和意义
此外,自动驾驶还可以为老年人、残疾人等特殊群体提供更加便捷的出行方式。经济发展方面,自动驾驶技术的应用不仅能够提升交通安全和效率,还能带动相关产业链的发展,创造新的商业机会。根据麦肯锡的预测,到2025年,智能汽车的市场规模将达到1.9万亿美元。自动驾驶汽车的普及将促进汽车产业的转型升级,并创造新的商业机会。

图1 杭州亚运会无人驾驶巴士
Part2
自动驾驶算法库JAD
图2 适配流行mm系列接口的Jittor实现
BEVFormer是目前最前沿的基于Transformer的多视角图片融合3D感知方案。BEVFormer是ECCV 2022最具影响力的论文之一,是2022年被引前100的AI论文。图3给出其框架图,其特点是使用BEV网格作为Query在空间与时间上使用注意力机制。
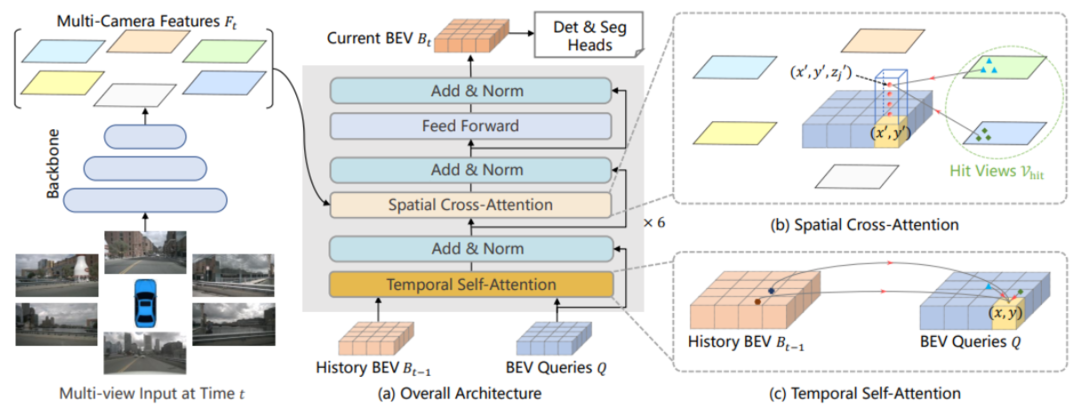
图3 BEVFormer框架图
下面的视频给出BEVFormer进行3D目标检测与BEV语义分割的演示视频。
视频1 3D目标检测与BEV语义分割
MTR是前沿的基于Transformer的预测算法,获NeurIPS 2022上口头汇报的荣誉。
MTR及其变体是Waymo Motion, Waymo Interactive, and Waymo Sim Agent等系列榜单上性能最好的算法。MTR也广泛被工业界采用。
图4给出了其框架图,其特点是将车辆与地图元素均视为Query,执行注意力机制。
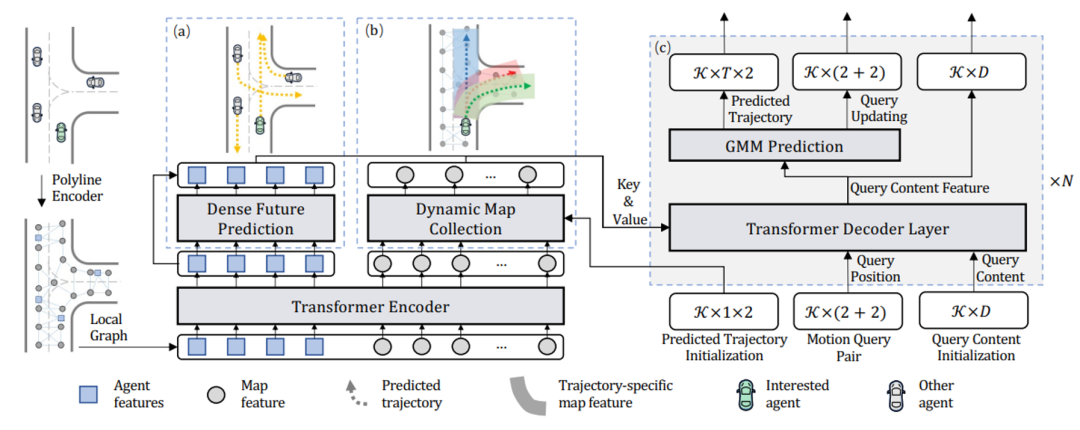
图4 MTR框架图
图5给出了使用MTR对多车的多种可能进行交互预测的示意图。
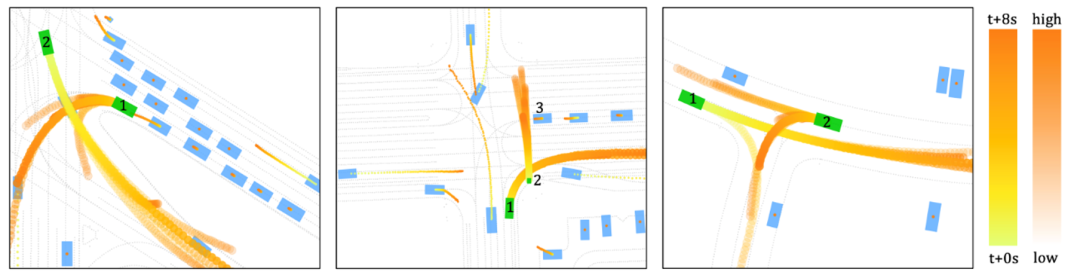
图5 使用MTR对多车的多种可能交互进行预测
UniAD是前沿的基于Transformer的端到端自动驾驶算法,获得了CVPR 2023最佳论文。UniAD在学术界与工业界都有着巨大的影响力,包括特斯拉最新的FSD V12采用了端到端自动驾驶方案。
图6给出其框架图,其特点是使用Query串联目标检测、跟踪、在线建图、轨迹预测、栅格占据、规控等自动驾驶上下游任务。
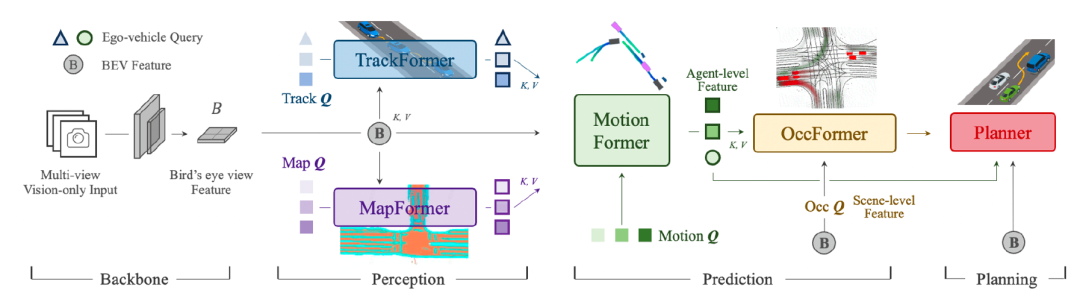
图6 UniAD框架图
下面的视频给出UniAD进行端到端多任务自动驾驶的演示。
视频2 UniAD进行端到端多任务自动驾驶演示视频
Part3
计图开源与后续计划
JAD全部代码已开源在:
https://github.com/Jittor/JAD
如果大家在使用过程中发现有什么问题,请大家在github提交issue或者PR。也可以加入Jittor开发者的QQ交流群,期待您提出宝贵的意见。
欢迎大家提出希望得到支持的模型以及贡献自己的模型。我们很高兴能与社区一起共建国产深度学习框架Jittor
+ 自动驾驶的生态,共同成长,为自动驾驶硬件-框架-算法的全面国产化生态的构建做贡献。
Li, Zhiqi, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai, Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers, European conference on computer vision,Lecture Notes in Computer Science, Vol. 13669, 1-18.
Shi, Shaoshuai, Li Jiang, Dengxin Dai, and Bernt Schiele, Motion transformer with global intention localization and local movement refinement, Advances in Neural Information Processing Systems, 2022, Vol. 35, 6531-6543.
Hu, Yihan, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai et al., Planning-oriented autonomous driving, IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, 17853-17862.
