
计图开源:利用扩散模型与NeRF从单张图像生成高保真三维物体:Make-It-3D-Jittor
近日,上海交通大学研究团队发布基于Jittor深度学习框架实现的版本,Jittor团队为实现提供了技术支持。Jittor版本取得了与Pytorch版本同样质量的生成结果,但是所需的训练时间较Pytorch版本更短,训练速度是Pytorch版本的1.45倍。
Part1
问题和背景
该任务非常具有挑战性,既要估计潜在的 3D 几何结构,也要同时生成未见过的纹理。针对这一问题,作者提出了Make-It-3D,一个能够通过单张图像创建高保真的3D内容,并且能估计底层3D几何结构和3D物体的纹理的方法。Make-It-3D 通过使用 2D 扩散模型作为 3D-aware 先验,从单个图像中创建高保真度的 3D 物体。该框架不需要多视图图像进行训练,并可应用于任何输入图像。其结果如下图所示:
图1 Make-It-3D的3D生成结果图
Part2
方法概述
该研究利用了文本-图像生成模型和文本-图像对比模型的先验知识,通过两阶段(Coarse Stage和Refine
Stage)的学习来还原高保真度的纹理和几何信息,所提出的两阶段学习框架Make-It-3D如图所示。
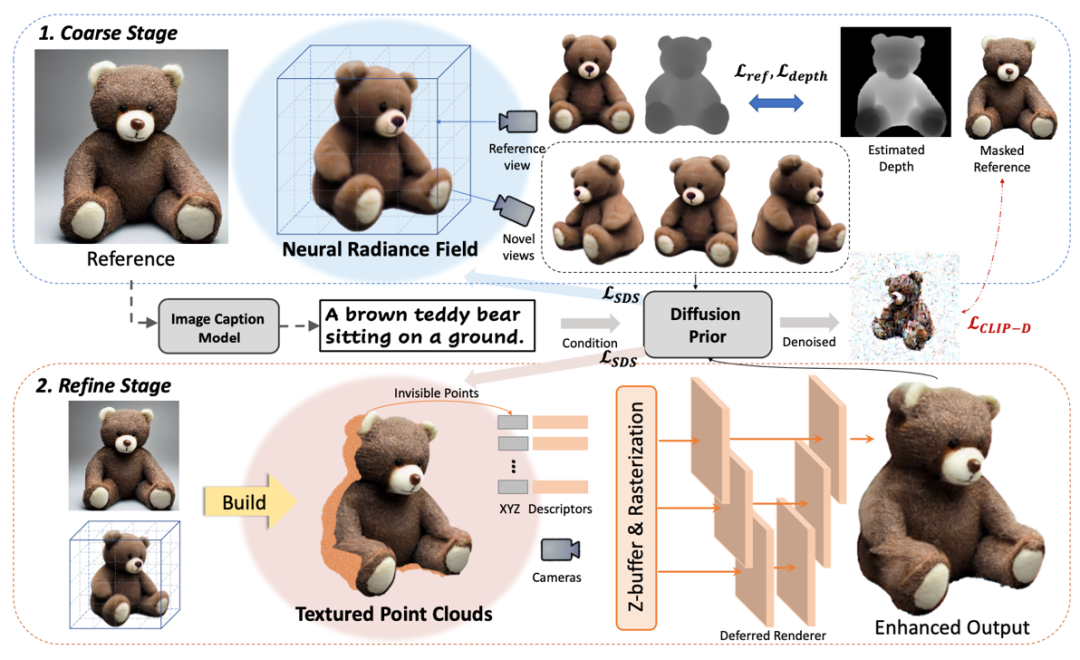
图2 Make-It-3D方法示意图
2.1 Coarse阶段
Coarse阶段的目标是从单张参考图像重建一个粗糙的3D模型。该阶段以NeRF作为3D表征,随机采样参考视角周围的相机姿态,当相机姿态为参考视角时,采用参考视角渲染的图像和参考图像的MSE损失和深度图的皮尔逊相关系数作为约束;当相机姿态为其他视角时,使用CLIP 提取图像特征保证新视角与参考图像的语义一致性。
具体而言,为了使新视角显示出与输入图像一致的语义,采用SDS损失,利用文生图扩散模型作为3D感知的先验引导生成。
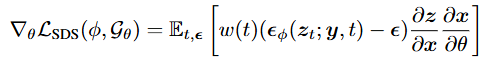
SDS损失可以引导生成与文本提示语义相符的3D模型,但由于文本提示不能捕获所有的对象细节,SDS损失无法实现与参考图像的完全对齐。因此在时间步数比较小时,额外添加一个扩散CLIP损失,进一步强制生成的模型来匹配参考图像:
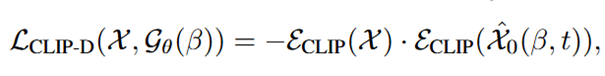
该研究结合SDS损失和扩散CLIP损失,确保了生成的3D模型的视觉质量,同时也符合给定的参考图像。
最终总的损失函数是参考视角MSE损失、深度损失、SDS损失和扩散CLIP损失的组合。为了稳定优化过程,该研究采用了渐进式训练策略,在参考视角附近从一个狭窄的视角范围开始,在训练过程中逐渐扩大范围。通过渐进式的训练,Make-It-3D可以实现360°的物体重建。
2.2 Refine阶段
Coarse阶段获得了一个具有合理几何形状的3D模型,但通常显示出粗糙的纹理,可能会影响整体质量。因此,需要进一步细化以获得高保真度的3D模型。Refine阶段的目标为,在保留粗糙模型几何形状的同时,对纹理进行增强。该阶段主要用于增强新视角中未出现在参考图像中的区域的纹理。
为更好实现上述过程,首先将NeRF转换为显式的3D表示形式--点云。具体地,首先根据由NeRF渲染的深度D(βref)和alpha掩模M(βref)从参考视角βref构建初始点云,随后采用迭代策略从多视图观测进一步构建点云,消除不同视角之间的冲突导致的噪声。
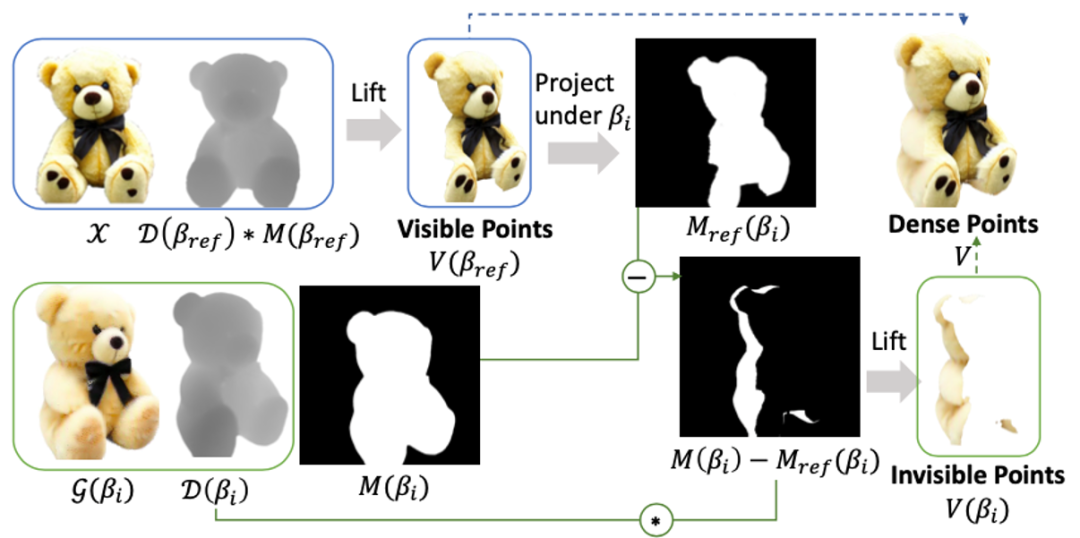
图3 Refine阶段纹理点云构建流程
为了避免噪声颜色和bleeding伪影,采用了多尺度延迟渲染方案:给定一个新的视角β,对点云V进行K次光栅化,得到K个不同的大小为[W/2i,H/2i]
的特征图Ii,其中i∈[0,K)。随后这些特征图被拼接起来,并使用一个联合优化的基于U-Net结构的神经渲染器Rθ渲染成一个图像I。
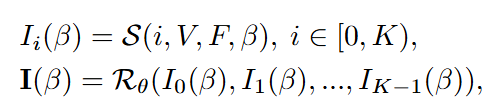
Part3
结果展示与Jittor实现
研究团队利用深度学习框架Jittor 实现了Make-It-3D,Jittor版本的Make-It-3D能够以更快的训练速度达到和Pytorch版本的Make-It-3D同样的效果。Jittor 版本的Make-It-3D已经在github开源。
以下实验结果均在24G RTX 4090上实现。
3.1 Coarse 阶段
在Coarse阶段的Jittor实现中,在将Pytorch的python代码转为Jittor代码之外,本项目中还采用了Tiny CUDA Neural
Networks (TCNN) 的Hash
Encoder与CUDA实现的Ray Marching体渲染算法。TCNN的Hash Encoder利用哈希编码,使得采用一个小规模的网络实现NeRF的同时不会导致精度的损失。体渲染Ray Marching算法,将NeRF表征的3D模型渲染到2D平面上。两种方法都基于CUDA实现,本项目基于Jittor Code算子转化实现了这部分高性能代码。
Coarse阶段根据单张输入图像重建整个3D内容,并且利用渐进式训练,逐渐获得360°的重建效果。实际训练中,在Coarse阶段,Jittor版本的运行速度是PyTorch版本的1.45 倍。
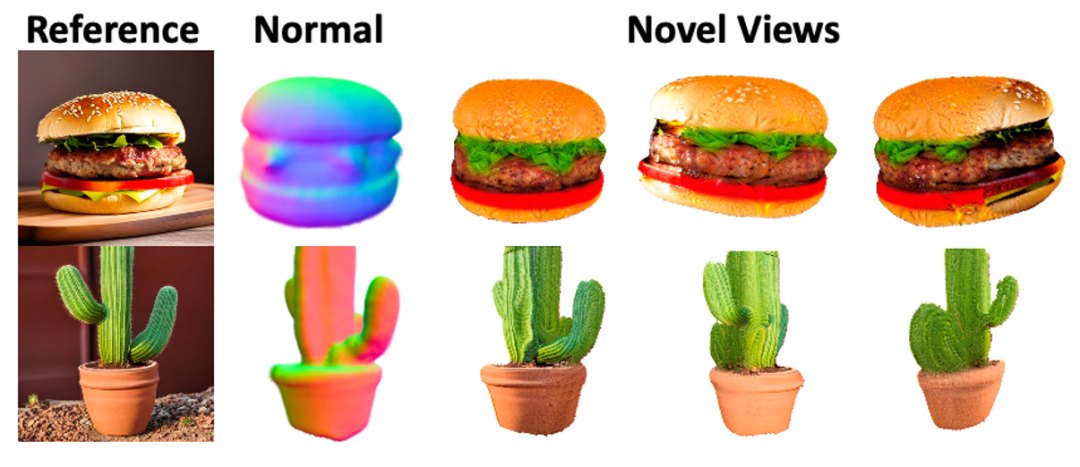
图4 基于单张图像的360°重建效果
3.2 Refine 阶段
在Refine阶段的Jittor实现中,在将PyTorch代码转为Jittor代码之外,本项目还将所依赖的PyTorch3D相关模块进行转化:Rasterize_point模块实现点云的渲染,Alpha_composite模块实现有透明通道的图像生成,两部分都基于CUDA代码,本项目基于Jittor Code算子转化实现了这部分高性能代码。
Refine阶段在保留了Coarse阶段的几何信息的同时,增强了生成的纹理细节,得到了高质量的生成结果。Jittor版本相比Pytorch版本,取得同等质量的生成效果,运行速度是Pytorch版本的1.46倍。
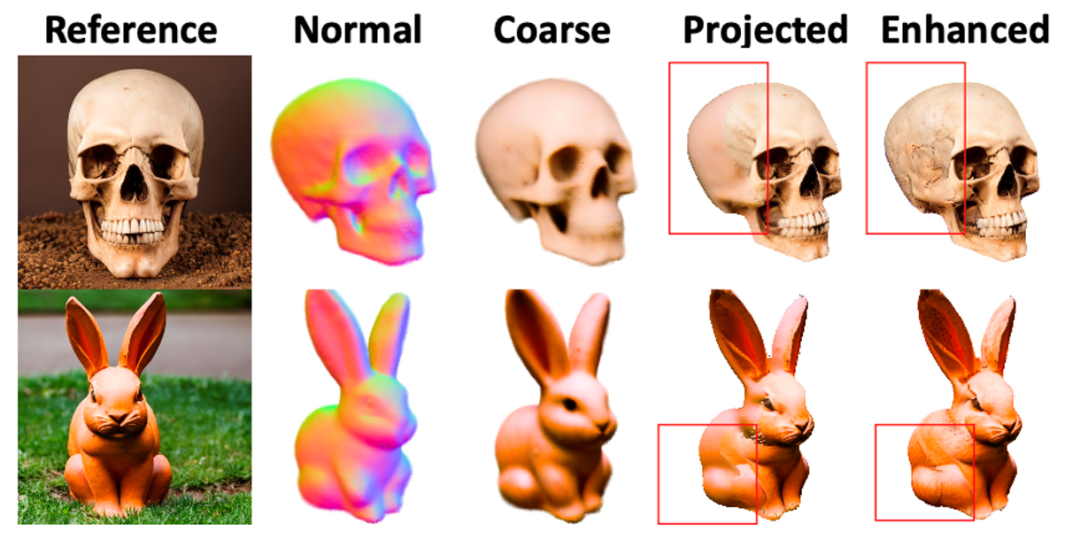
图5 Refine阶段纹理增强结果
3.3 对比实验
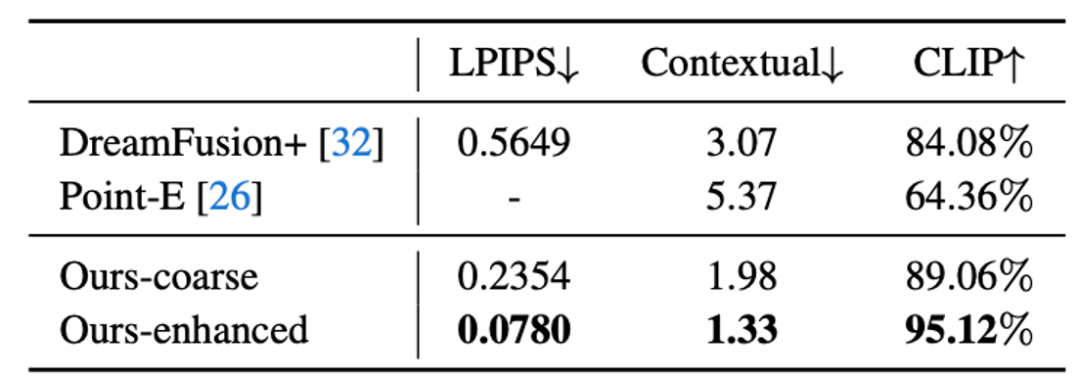
Make-It-3D 生成结果相较于以往的Baseline方法,在几何和纹理上都取得了更高的质量,并且在量化指标上也较以往的方法更为优异。

图6 与baseline方法的可视化结果对比
Part4
计图开源
该项目的Jittor代码已在github上开源:
https://github.com/DMCV-SJTU/Make-it-3D-Jittor
基于Jittor实现的代码,Coarse阶段速度是PyTorch版本的1.45倍,Refine阶段速度是PyTorch版本的1.46倍。
论文原文可在thecvf的ICCV主页上下载。
项目的主页为:
https://make-it-3d.github.io/
该项研究由上海交通大学、香港科技大学和微软研究院合作完成。Jittor版本代码实现由上海交通大学数字媒体与计算机视觉实验室(DMCV)马利庄教授、易冉助理教授团队完成,由计图团队提供技术支持。
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, Dong Chen, Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior, Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, 22819-22829.
3. 三维高斯泼溅进展综述 | CVMJ Spotlight
4. CVMJ获最新期刊影响因子17.3,计算机学科软件工程类别排名第一
5. 计图助力非十科技发布AI代码助手,代码大模型速度精度超越Copilot
