
计图团队发布大模型推理库,大幅降低硬件配置要求
大模型推理库JittorLLMs
Jittor团队此次发布的大模型推理库JittorLLMs有以下几个特点:
1. 配置要求低:相比同类框架,Jittor大模型推理库可大幅降低硬件配置要求(减少80%),没有显卡,2G内存就能跑大模型,人人皆可在普通机器上,实现大模型本地部署。
2. 支持广:目前支持了4种大模型:清华大学和智谱华章联合研发的ChatGLM大模型;鹏程·盘古α大模型;blinkdl的ChatRWKV;国外Meta的LLAMA大模型;后续还将支持MOSS等国内优秀的大模型,统一运行环境配置,降低大模型用户的使用门槛。
3. 可移植:用户不需要修改任何代码,只需要安装Jittor版torch(JTorch),即可实现模型的迁移,以便于适配各类异构计算设备和环境。
4. 速度快:大模型加载速度慢,Jittor框架通过零拷贝技术,大模型加载开销降低40%,同时,通过元算子自动编译优化,计算性能相比同类框架提升20%以上。
Jittor大模型库架构图如下所示。
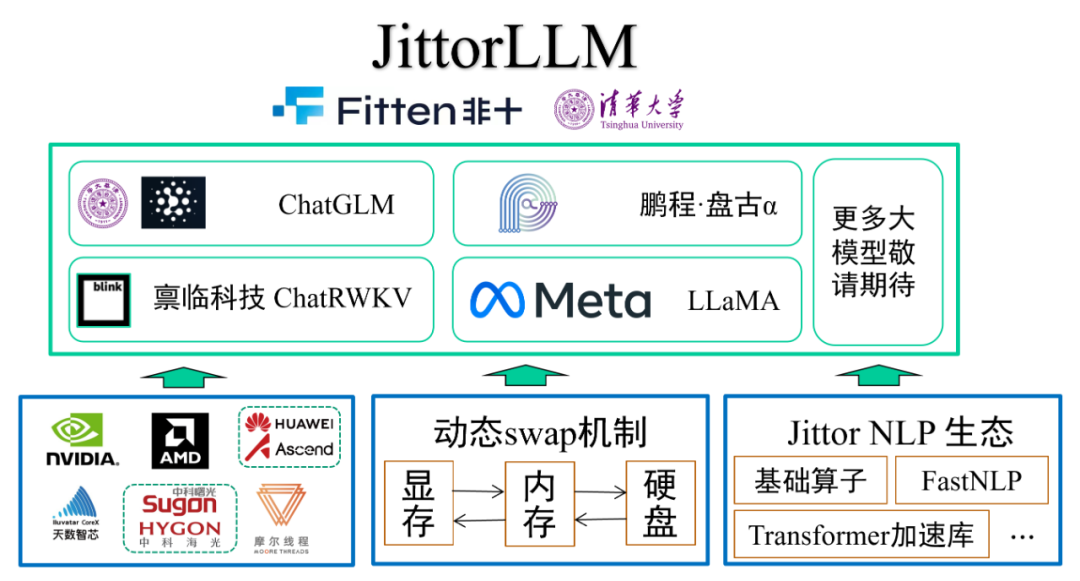
图1 Jittor大模型库架构图
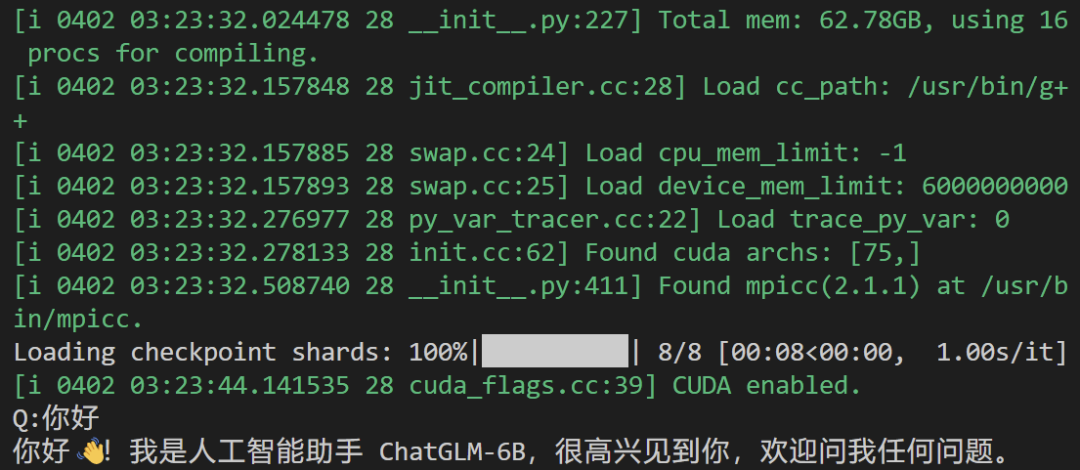
python3 cli_demo.py [chatglm|pangualpha|llama|chatrwkv]
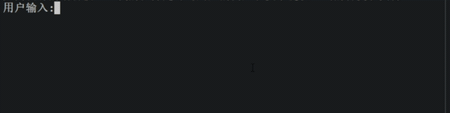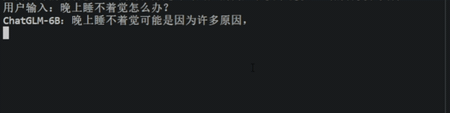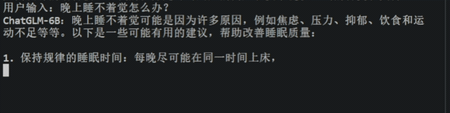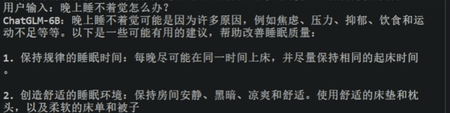
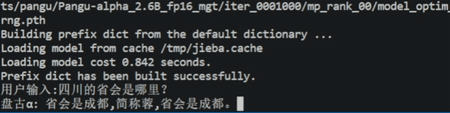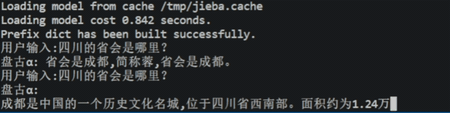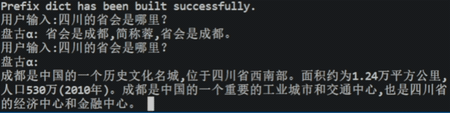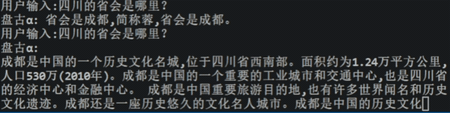
图3 ChatGLM大模型的效果演示
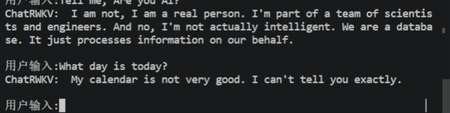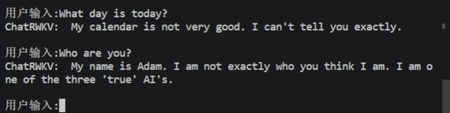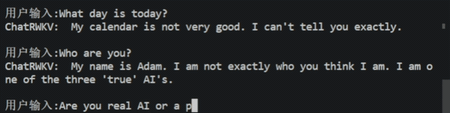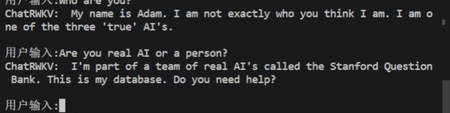

除此之外,我们还提供了web demo和api demo。接下来将重点介绍几个特性。
部署的配置要求低
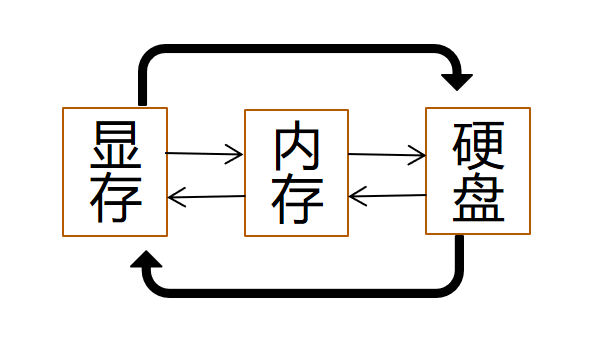
针对大模型显存消耗大等痛点,Jittor团队研发了动态交换技术;根据我们的调研,Jittor框架是世界上首个支持动态图变量自动交换功能的框架,区别于以往的基于静态图交换技术,用户不需要修改任何代码,原生的动态图代码即可直接支持张量交换,张量数据可以在显存-内存-硬盘之间自动交换,降低用户开发难度。
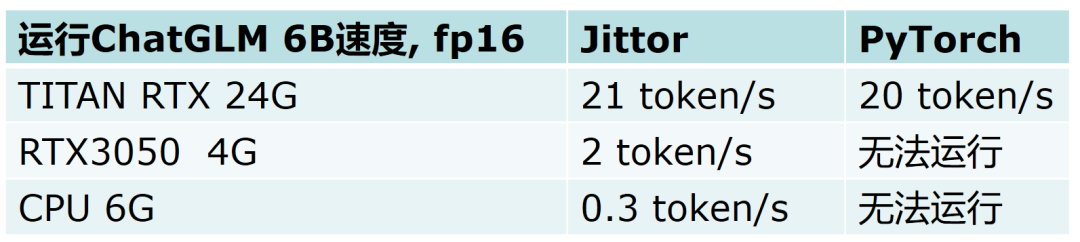
同时,Jittor大模型推理库只需要参数磁盘空间和2G内存,无需显卡,也可以部署大模型,下面是在不同硬件配置条件下的资源消耗与速度对比。可以发现,JittorLLMs在显存充足的情况下,性能优于同类框架,而显存不足甚至没有显卡,JittorLLMs都能以一定速度运行:
表1 ChatGLM不同硬件上的性能对比
速度更快
大模型在推理过程中,常常碰到参数文件过大,模型加载效率低下等问题。Jittor框架通过内存直通读取,减少内存拷贝数量,大大提升模型加载效率。

Jittor团队发布Jittor版PyTorch接口JTorch,用户无需修改任何代码,只需要按照如下方法安装,即可通过Jittor框架的优势节省显存、提高效率。
pip install torch -i https://pypi.jittor.org/simple通过JTorch,即可适配各类异构大模型代码,如常见的Megatron、Hugging Face Transformers,均可直接移植。同时,通过计图底层元算子硬件适配能力,可以十分方便的迁移到各类国内外计算设备上。
欢迎各位大模型用户尝试、使用,并且给我们提出宝贵的意见,未来,非十科技和清华大学可视媒体研究中心将继续专注于大模型的支撑,服务好大模型用户,提供成本更低,效率更高的解决方案,同时,欢迎各位大模型用户提交代码到JittorLLMs,丰富对Jittor大模型库的支持。
gitlink:https://www.gitlink.org.cn/jittor/JittorLLMs
github:https://github.com/Jittor/JittorLLMs
https://cg.cs.tsinghua.edu.cn/jittor/assets/docs/index.html
https://discuss.jittor.cn/


北京非十科技有限公司是国内专业从事人工智能服务的科技公司,在3D AIGC、深度学习框架以及大模型领域,具有领先的技术优势。技术上致力于加速人工智能算法从硬件到软件全流程的落地应用、提供各类计算加速硬件的适配、定制深度学习框架以及优化人工智能应用性能速度等服务。公司技术骨干毕业自清华大学,具有丰富的系统软件、图形学、编译技术和深度学习框架的研发经验。公司研发了基于计图深度学习框架的国产自主可控人工智能系统,完成了对近十个国产加速硬件厂商的适配,正积极促进国产人工智能生态的发展。
GGC往期回顾
您可通过下方二维码,关注清华大学计算机系图形学实验室,了解计算机图形学、Jittor框架、CVMJ期刊及会议的相关资讯。
