
计图开源:人体视频姿态迁移之动态纹理合成
Part 1
从人体姿态序列渲染出高真实感人体运动视频一直在计算机视觉和图形学领域受到广泛的关注。现有的工作大体可以分为两类,有的采用图像翻译技术,借助条件生成式对抗网络实现人体姿态标签到视频帧的转换,然而这些方法却受限于神经网络的泛化能力,对于训练集之外的新姿态合成结果往往较差;有的方法引入了描述人体的三维表征,通过渲染的思路合成人体以增强生成模型的鲁棒性。然而传统渲染管线中的静态纹理往往无法很好地合成运动人体表面动态变化的细节信号;同时这些方法依赖于多视角视频重建得到的人体模型,而这种专业的多目相机采集设备也限制了这类方法的应用。
为了解决静态纹理无法合成动态细节的问题,该研究工作提出了一种基于动态纹理合成的人体视频渲染工作,效果如图1所示。通过将神经网络提取出的具有强大表征能力的图像特征嵌入可微分渲染管线中,该工作能够以单目视频作为训练数据,合成出不同姿态下的人体表面高频纹理信号。
图1 基于动态纹理合成的人体视频渲染效果
Part 2
首先,为了合成出不同姿态下的人体动态纹理,研究者们提出一种全新的混合纹理表征以及相应的动态纹理细节生成网络。混合纹理表征能够同时刻画显式的人体静态外观细节和隐式的动态细节特征。该特征在从纹理空间映射到图像空间后再通过动态纹理细节生成网络转化为具有高频细节信号的人体前景图像。同时研究者们还提出一种背景优化策略,从视频帧中提取出清晰完整的背景图以拼接成完整的视频帧。算法框架如图2所示。
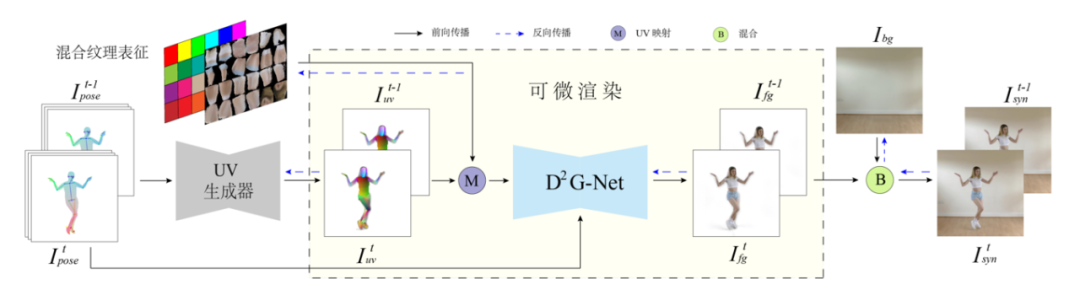
图2 动态纹理合成算法示意图
该方法中的人体姿态同时包含2D和3D表征。其中,2D表征是通过连接Openpose提取的关键点组成的骨架图像;3D表征是基于视频重建的人体网格投影图像。该表征既保留了2D关键点相对准确且易于检测的优势,又通过3D信息弥补了2D姿态歧义和自遮挡的问题。该姿态图送入UV生成器,预测得到图像空间中每一点所对应三维模型表面的UV坐标值。同时,为了更好地合成动态纹理该方法引入了一种混合纹理表征,它由显式的RGB颜色值和隐式的细节特征拼接组成。纹理的参数化方式遵循Densepose系统,将人体分为24个部分以分块展开。其中,纹理特征的前三个显式通道通过将视频帧按照Densepose的预测结果展开以进行初始化,余下的高维隐式通道采用随机初始化的方式,并在训练过程中迭代更新。
UV生成器的输出采用相同的参数化方式。记图像上每个像素属于人体第i个部分的概率为Pi, (i = 0,1,2,…,24 ),其大小为H x W。这里的H和W分别是视频帧的高度和宽度, P0代表像素属于背景的概率。记图像上每个像素在人体第i个部分中的UV坐标为Ci, (i = 1,2,…,24 ),其形状为Hx W x 2。根据UV生成器的预测结果,混合纹理特征可以从纹理空间被映射到图像空间,得到纹理特征构成的人物前景图。这一过程可以形式化为
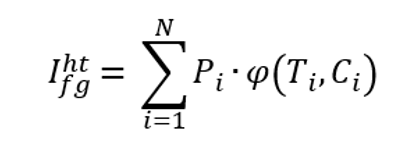
其中,φ是根据UV坐标Ci将混合纹理Ti映射到图像空间的映射函数。
在得到图像空间的混合纹理特征后,研究者们设计了一个相应的动态细节生成网络以从纹理特征合成人体表面高频细节信号。动态细节生成网络的结构如下所示:
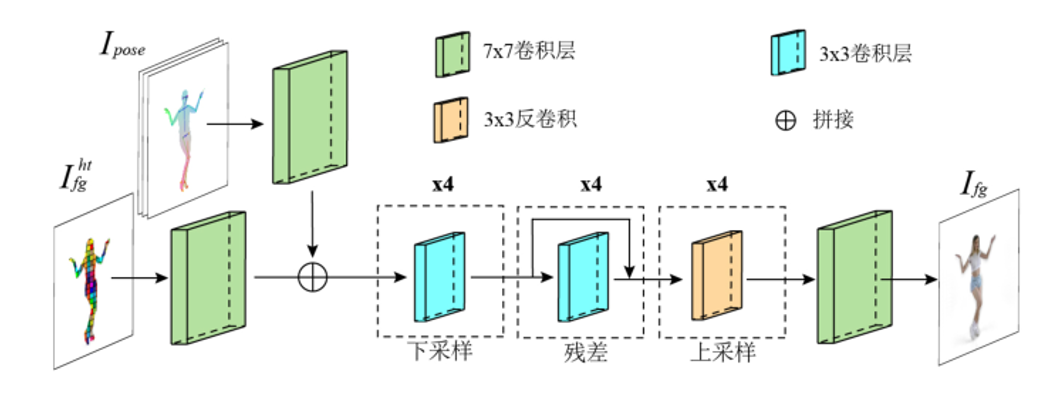
该网络采用图像翻译技术Pix2pixHD的网络架构,由下采样-残差-上采样三个模块组成,以将隐式的纹理特征转为显式的像素颜色值。同时动态纹理细节依赖于当前姿态,该网络接收姿态信息作为额外输入并在特征层与纹理信号进行拼接。
为了将细节丰富的人体前景图像补全为最终视频帧,该方法还提出一种背景优化机制。由于不同视频帧中人物对背景会有不同的遮挡,不同视频帧的背景信息可以整合复用。因此,通过将初始背景作为可学习的参数,该方法在训练过程中根据反向传递的梯度优化更新来整合利用来自所有视频帧的信息。最终合成的视频帧为前景图像与背景图的混合。
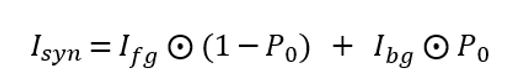
此外,直接将单独生成的每一帧拼接为视频往往会不可避免地引入闪烁和抖动的问题,进而导致看起来的结果不够逼真和自然,尤其是对于包含清晰动态细节的视频帧。因此研究者们将temporal loss引入到人体视频生成任务中。该损失函数定义为当前时刻生成帧与前一时刻生成帧根据光流扭曲结果的L1 loss,形式化为
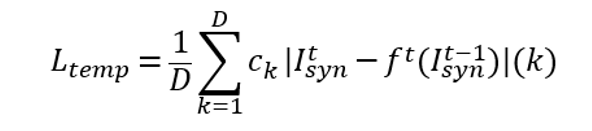
其中, D = H x W表示像素数目, ck表示光流置信度, f表示前一时刻视频帧到当前时刻t的光流扭曲函数, I(k)表示从图像中选取第k个像素。
Part 3



该工作由中科院计算所高林副研究员和硕士毕业生孙阳天、英国卡迪夫大学的来煜坤教授以及腾讯的刘威、黄浩智和王璇合作完成,目前Jittor代码已在GitLink和Github上开源:
https://www.gitlink.org.cn/IGLICT/DynamicHumanGeneration_Jittor
https://github.com/IGLICT/DynamicHumanGeneration_Jittor
Jittor是清华大学开源的自主深度学习框架[6],采用元算子融合和统一计算图的新技术,并支持国产硬件。在Jittor框架的加持下,对比pytorch实现,训练速度提升为之前的1.17倍,推理速度提升为之前的1.22倍。
Yang-Tian Sun, Hao-Zhi Huang, Xuan Wang, Yu-Kun Lai, Wei Liu, Lin Gao, Robust Pose Transfer with Dynamic Details using Neural Video Rendering, IEEE TPAMI, 2022, 1-8.
Caroline Chan, Shiry Ginosar, Tinghui Zhou and Alexei A. Efros, Everybody Dance Now, IEEE ICCV, 2019, 5932-5941.
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz and Bryan Catanzaro, Video-to-Video Synthesis, NeurIPS, 2018, 1152–1164.
Aliaksandra Shysheya, Egor Zakharov, Kara-Ali Aliev, Renat Bashirov, Egor Burkov, Karim Iskakov, Aleksei Ivakhnenko, Yury Malkov, I. Pasechnik, Dmitry Ulyanov, Alexander Vakhitov and Victor S. Lempitsky, Textured Neural Avatars, IEEE CVPR, 2019, 2382-2392.
Lingjie Liu, Weipeng Xu, Marc Habermann, Michael Zollhöfer, Florian Bernard, Hyeongwoo Kim, Wenping Wang and Christian Theobalt, Learning Dynamic Textures for Neural Rendering of Human Actors, IEEE TVCG, Vol. 27, No.10, 2021, 4009-4022.
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang and Wen-Yang Zhou, Jittor: a novel deep learning framework with meta-operators and unified graph execution, Science China Information Science, 2020, Vol. 63, No. 12, 222103.
GGC往期回顾
计图可微渲染库再更新!渲染效果、速度新突破! 计图开源:拉格朗日视角的可微渲染方法 计图开源:人体视频姿态迁移之细节增强 (T-PAMI发表,内附精彩视频) 计图原生支持Einops和多种主流MLP网络啦 城市可视分析 | CVMJ Spotlight
