精心拍摄了自己的短视频,却发现没有做好表情管理,想要修改表情动作?又或者,想要更加个性化的编辑?视频编辑神器DFVE (Deep Face Video Editing) 可以解决你的烦恼,即使没有专业影视软件与技能,也能自由编辑视频!
DFVE由中科院计算所、香港城市大学和英国卡迪夫大学的研究人员联合在计算机图形学重要会议ACM SIGGRAPH 2022上发表,并在计图框架上开源。DFVE将草图交互引入到视频编辑,用户通过简单的线条绘制,便可以实现人脸视频的精细化编辑。基于该方法的智能人脸视频编辑软件,普通用户无需技能训练,就可自由精修视频中的细节,甚至可以编辑人脸的表情动作,例如,生成自然表情到微笑表情的平滑过渡。这大大降低了视频编辑的门槛,并减轻了专业影视后期制作人员的工作压力,简单实用。先来两个短片,感受一下DFVE的惊艳效果!图1 弥补发际线的不足,添加成熟的胡茬,增加俏皮的挑眉的动作
图2 精修眉形,添加自然的微笑动作
Sketch与视频编辑
视频编辑具备很高的实用性和应用价值,但由于视频的动态性和连续性,视频处理有较大的挑战。已有一些工作围绕视频上色或者风格迁移展开研究,但无法实现视频内容的编辑。专业人员即使是使用PR、AE等视频编辑软件,也需要花费大量时间和精力,这使得普通使用者更无法自由便捷地编辑视频。Sketch作为一种图形交互媒介,受到广泛的关注。早在1963年,图灵奖得主Ivan Sutherland的代表作称为“SketchPad”[1]。一般来说,图形学中简单的笔画交互,我们称“Sketch”称为草图,而在动漫领域,对应于复杂的线条表达,也称线稿。 2009年,清华大学胡事民教授团队发表于ACM
SIGGRAPH ASIA的Sketch2Photo[2]开创了基于草图的互联网图像合成新方向。针对人脸图像的编辑和合成,中科院计算所高林团队发表于ACM
SIGGRAPH 2020和2021的DeepFaceDrawing[3]、DeepFaceEditing[4]分别解决了基于线稿的人脸图像的生成和编辑问题。图3 基于Sketch的直接编辑
但是,将草图编辑由图像应用至视频,其实非常困难。虽然在图像上利用Sketch,已经可以生成较好的编辑效果,但是视频中拍摄到的人脸图像往往是动态的,具备不同的表情和动作。针对某一帧图像的编辑操作,难以推测出其他帧的对应操作。
同时,在视频编辑的过程中,用户往往会在不同的关键帧,输入多个的编辑操作,合理地融合这些编辑并不容易。表情动作的编辑则更加困难,如何基于Sketch生成自然的表情过渡,非常有挑战性。并且,视频编辑需要保证时序连续性,不能有抖动和偏移。为了解决上述的问题,DFVE将人脸视频编辑建模为人脸生成问题StyleGAN3[5],并设计了以下解决方法。输入的视频被投影至隐空间,支持后续的编辑。系统包括了基于线稿的优化模块,用抽象向量表示线稿编辑操作。编辑被进一步分成了两类:时序一致性编辑和时序变化性编辑,使用不同的方式传播编辑操作。系统还包括了局域融合模块,融合多个关键帧的线稿编辑操作。DFVE的算法原理
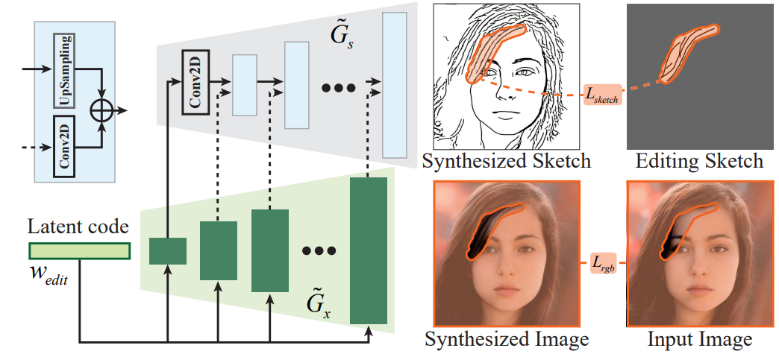
输入视频片段后,DFVE先对每一帧的人脸进行裁剪对齐,提取出人脸的区域。对齐过程中,平滑检测出的关键点,保证时序稳定。所有帧使用E4E[6]投影至StyleGAN3隐空间,并进一步使用PTI[7]微调生成网络,保证精确重建。如上图所示,该系统设计了一个线稿优化模块。绿色的是原StyleGAN3生成网络,用来合成高真实感的人脸图像。在此基础上,添加了一个线稿分支,基于生成网络的中间特征图,来生成对应人脸的线稿。因此,当用户完成线稿绘制进行优化时,约束在编辑的区域与绘制线稿对应,非编辑区域与生成图像对应,以此作为优化条件来反向优化输入的隐码。优化后的隐码与原始隐码做差,得到编辑向量,抽象表示编辑操作。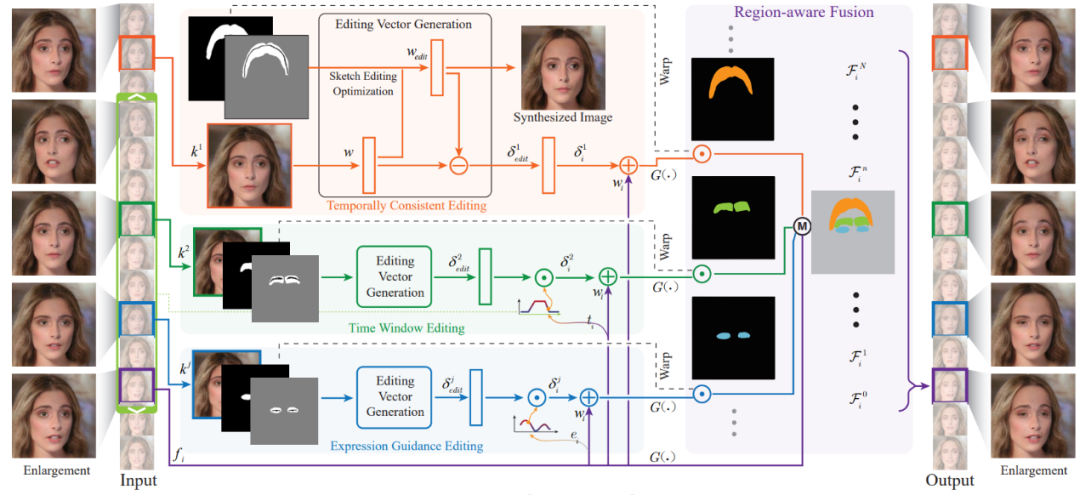
图5
DFVE 网络架构
为了合理地传播编辑,用户的编辑操作被分成了2类:时序一致性编辑和时序变化性编辑。时序一致性编辑,顾名思义,是一类编辑效果不随时间变化的编辑操作,主要包括对五官形状、头发区域等的编辑。针对此类编辑,上一步生成的编辑向量,可直接均匀地叠加至所有帧的隐码,完成编辑的传播。时序变化性编辑又被细分成了2类:时间窗口编辑和表情驱动编辑。时间窗口编辑可以实现从自然表情到编辑表情,又恢复至自然表情的全过程。此类编辑使用分段线性函数作为权重,叠加编辑向量,完成编辑传播。表情驱动编辑则是人脸表情变化相关的编辑,通过计算预测帧与编辑帧表情参数的相似度,从而得到权重叠加编辑向量。该类编辑将线稿编辑操作与特定表情相关联,完成编辑传播。当得到多个关键帧的不同编辑操作后,需要将编辑操作进行融合传播至整段视频上。因此,设计了区域融合模块。针对用户绘制的编辑区域,根据帧间的变化生成变形场,变形生成不同表情和姿态下的待编辑的区域位置。进一步,在图像生成过程中,根据变形后的编辑区域替换局部区域的中间特征图,从而融合不同编辑生成图像结果。最后,生成的人脸区域又融合至原始视频,得到编辑后的视频结果。更多的结果展示
使用DFVE,可以生成不同种类的有趣的编辑效果。图6展示了时序一致性编辑的结果,放大了男孩的脸型,更具有了男子气概。
图7展示了时间窗口编辑的结果,为女孩添加了甜甜的微笑,生成了不同表情间的自然过渡。
图7 时间窗口编辑
图8展示了表情驱动编辑的结果,当女孩张开嘴巴时,变小了她的眼睛。
图8 表情驱动编辑
Part4
实验对比
DFVE相比于现有的视频编辑方法,能生成更好的结果。针对时序一致性编辑这一类线稿编辑,该系统生成了更稳定、更高质量的结果,在牙齿等局部区域,也具备了更加丰富的细节。
针对时序变化性这一类线稿编辑,已有方法难以处理。如下图所示,DFVE系统生成的结果不仅质量更高,而且具备了不同表情间的动态变化。这种不同表情的平滑过渡,已有的方法完全无法实现。图10 时序变化性编辑
Part5
结语和Jittor开源
人脸视频编辑有重要的应用价值,不论是在朋友圈中精致的自拍短视频,还是文艺宣传片等影视传媒作品,我们都想展示更加精彩的一面,留下更美好的记忆。使用智能视频编辑系统,我们不再需要繁杂的专业软件与技能,也不再需要花费数个小时的时间精力,便可以个性化地精修人脸视频。DFVE系统,将用户绘制的线稿编辑操作,表示成了抽象的编辑向量,并设计了多种传播方式,生成不同的编辑效果。多个关键帧的编辑操作,基于局部区域融合的方式,合成最终的视频序列。DFVE的论文已被ACM SIGGRAPH 2022接收,并将刊登在著名期刊ACM
Transactions on Graphics上。该项目研究团队包括中科院计算所的高林副研究员(本文通讯作者)、李淳芃副研究员、陈姝宇助理研究员、研究生刘锋林、英国卡迪夫大学的来煜坤教授和香港城市大学傅红波教授,有关论文的更多细节,及论文、视频、代码的下载,请浏览项目主页:http://www.geometrylearning.com/DeepFaceVideoEditing/目前智能人脸编辑软件已经发布计图(Jittor)版本,Jittor是清华大学计算机图形学实验室开源的自主深度学习框架。开源代码见:https://github.com/IGLICT/DeepFaceVideoEditingDeepFaceVideoEditing的计图开源代码中还包括了发表在SIGGRAPH 2022的PTI [7]、发表在SIGGRAPH 2021的E4E [6]、发表在NeurlPS 2021的StyleGAN3 [5]的计图开源代码。参考文献
Sutherland, Ivan E. Sketch Pad a Man-Machine
Graphical Communication System, 1964.
Tao Chen, Ming-Ming Cheng, Ping Tan, Ariel Shamir, Shi-Min Hu, Sketch2Photo: Internet Image Montage, ACM Transactions on Graphics, Vol. 28, No. 5, 2009, 124:1-124:10.
Shu-Yu Chen, Wanchao Su, Lin Gao, Shihong Xia, Hongbo
Fu. DeepFaceDrawing: Deep Generation of Face Images from Sketches, ACM
Transactions on Graphics, Vol. 39, No. 4, 2020, 72:1-72:16.
Shu-Yu Chen, Feng-Lin Liu, Yu-Kun Lai, Paul L. Rosin,
Chunpeng Li, Hongbo Fu, Lin Gao. DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control, ACM
Transactions on Graphics, Vol. 40, No. 4, 2021, 90:1–90:15.
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen,
Janne Hellsten, Jaakko Lehtinen, Timo Aila, Alias-free Generative Adversarial Networks, Advances in Neural Information Processing Systems, 2021, 852-863.
Daniel Roich, Ron Mokady, Amit H. Bermano, Daniel
Cohen-Or, Pivotal Tuning for Latent-based Editing of Real Images, ACM Transactions
on Graphics, 2022, doi: 10.1145/3544777.
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, Daniel Cohen-Or, Designing an Encoder for StyleGAN Image Manipulation, ACM Transactions on Graphics, Vol. 40, No. 4, 2021, 133:1–133:14.
GGC往期回顾
1. 第二届计图挑战赛B榜前十名产生,风景图片生成赛题投票通道开启!
2. Computational Visual Media第8卷第4期导读
3. 董士海教授和马利庄教授分获Chinagraph贡献奖和杰出奖
4. CVMJ获得首个SCI影响因子4.127,进入Q1区
5. Scopus发布2021年度影响因子, CVMJ从4.0升至5.9
您可通过下方二维码,关注清华大学计算机系图形学实验室,了解计算机图形学、Jittor框架、CVMJ期刊及会议的相关资讯。