
计图开源:基于动态编码云的深度隐式函数学习
三维形状表示是三维计算机视觉领域的基础问题之一,是分割、识别、渲染等许多下游任务的前提。深度隐式函数(DIF)作为一种有效的三维形状表示方法,得到了广泛的关注和应用。由于现有的DIF方法中局部潜在编码被限制在离散和规则的位置,使得这些方法的精度和效率受限。
近期,清华大学的刘玉身团队于CVPR 2022发表了一项重要成果DCC-DIF[1],提出通过动态编码云的方式来学习深度隐式函数,并开源了基于计图(Jittor)的代码。
图1 DCC-DIF的重建效果
Part1
研究问题和背景
深度隐式函数(DIF)作为一种有效的三维形状表示方法,已经得到了广泛的应用。现有的三维形状隐式表达学习[2-6]的方法可大致分为两类:1) 基于全局的深度隐式函数,2) 基于局部的深度隐式函数。
基于全局的深度隐式函数将三维形状的几何和拓扑信息压缩到一个全局潜在编码中,但受限于固定长度的全局潜在编码,这类方法较难保留三维形状的局部细节,重建结果的精度和质量受限。
为了捕捉几何细节,基于局部的深度隐式函数通常将三维空间离散化为规则的三维网格或者八叉树,并将局部编码存储在网格点或者八叉树节点中。代表性工作包括MDIF[5]和NGLOD[6]等。这类方法通过局部的潜在编码保留了较多的局部形状细节,相对全局的深度隐式函数有更好的重建质量。
但这类方法中,局部潜在编码被限制在规则且离散的位置,如网格点,这使得编码的位置难以被优化,限制了模型的表达能力。为了解决这个问题,作者提出用动态编码云来学习深度隐式函数(称为DCC-DIF)。该方法将局部编码与可学习的位置向量显式关联起来,这些位置向量是连续的、可动态优化的,提高了表达能力。
此外,作者提出了一种新的编码位置损失函数来优化位置向量,该算法启发式地引导更多的局部编码分布在复杂的几何细节周围,从而更好地刻画局部形状。与现有的方法相比,DCC-DIF能更有效地表示三维形状,提高重建质量。
Part2
方法概述
基于全局的深度隐式方法利用一个全局的潜在编码来表示三维形状,对于一组查询点,这类方法以查询点和全局潜在编码为输入,通过解码器预测出到表面的有符号距离,并以预测值和真实值之间的误差作为损失函数,来优化全局潜在编码(如图2(a))。

图2 DCC-DIF网络概述
相比于基于全局的深度隐式方法,基于局部的深度隐式方法将全局潜在编码替换为一组局部潜在编码,但这些局部潜在编码被限制在规则且离散的位置(见图2(b))。
而本文的方法中,每个局部潜在编码都被显式地关联了位置向量,这些位置向量表示了对应的局部编码在三维空间中的(x,y,z)坐标,这些位置向量可取连续变化值,从而局部潜在编码的位置是连续且可被动态优化的(见图2(c));除了用预测的有符号距离和真实值之间的误差来优化局部编码外,作者还提出了编码位置损失函数(Code Position loss, CP loss)来优化位置向量。
Part3
结果展示和代码开源
本文在Thingi32和ShapeNet数据集上进行了定量和定性的实验比较。其中,Thingi32数据集用于单物体的拟合,该实验能够验证方法的表达能力和刻画局部细节的精度;ShapeNet数据集用于未见形状的重建,该实验能够验证方法学习形状先验和泛化的能力。
1)量化比较
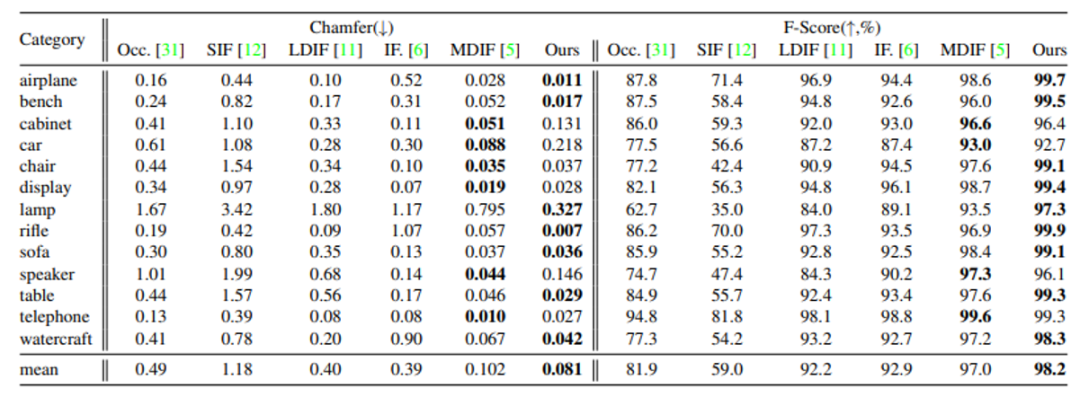
Thingi32数据集上的拟合实验中,本文采用Chamfer Distance(CD)和Intersection over Union(IoU)作为量化指标来度量精度和重建质量,同时用潜在编码的数量和网络参数量度量方法的效率和存储、计算代价。表1为此实验的量化结果,从表中可以看到本文的方法优于其它方法,在同等的参数量和潜在编码数量的条件下达到了更高的精度,在近似的精度下本文的方法使用更少的潜在编码,却具有更高的效率。
表1 Thingi32数据集上的拟合结果

ShapeNet数据集上的重建实验中,本文采用Chamfer Distance(CD)和F-Score作为量化指标,表2为此实验的量化结果,可以看出,该方法在CD和F-Score两个指标上都超越了已有的方法,证明了DCC-DIF学习形状先验和泛化的能力。
表2.ShapeNet数据集上的重建结果
2)可视化比较
在图3和图4中,本文分别在Thingi32和ShapeNet数据集上与已有方法进行了可视化比较。从图中可以看到,相较于现有方法,本文的DCC-DIF能够重建出更高精度的结果,尤其在具有复杂形状的局部区域,如褶皱、细条、孔洞等。

图3.Thingi32可视化结果
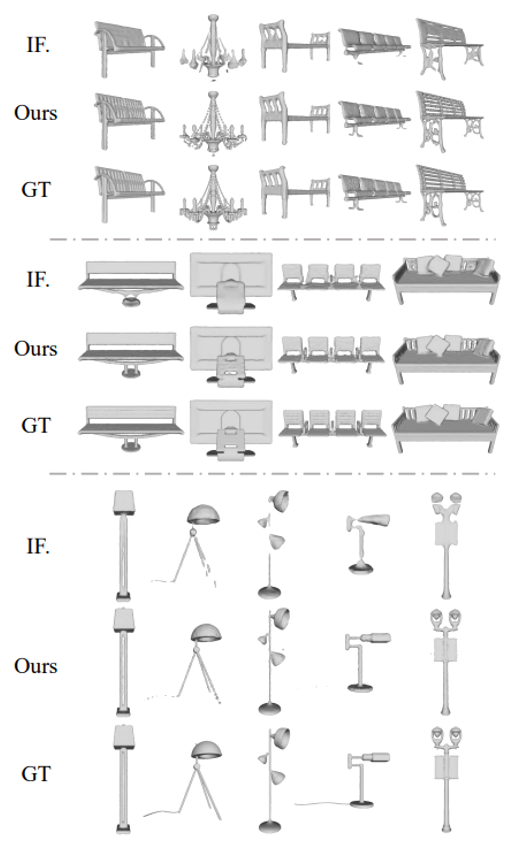
图4.ShapeNet可视化结果
该方法目前已开源了基于计图(Jittor)实现的代码。相较于PyTorch,基于计图的实现在推理阶段,显存占用降低了约25%,计算时间减少了约29% 。
项目主页:
https://lity20.github.io/DCCDIF_project_page
代码开源:
https://github.com/lity20/DCCDIF-jittor
点击下方的"阅读原文",可浏览论文的全文。
参考文献
Tianyang Li, Xin Wen, Yu-Shen Liu, Hua Su, and Zhizhong Han, Learning Deep Implicit Functions for 3D Shapes with Dynamic Code Clouds, IEEE/CVF CVPR, 2022.
Baorui Ma, Yu-Shen Liu, Matthias Zwicker, Zhizhong Han, Surface Reconstruction from Point Clouds by Learning Predictive Context Priors, IEEE/CVF CVPR, 2022.
Baorui Ma, Yu-Shen Liu, Zhizhong Han, Reconstructing Surfaces for Sparse Point Clouds with On-Surface Priors, IEEE/CVF CVPR, 2022.
Baorui Ma, Zhizhong Han, Yu-Shen Liu, Matthias Zwicker, Neural-Pull: Learning Signed Distance Functions from Point Clouds by Learning to Pull Space onto Surfaces, ICML, 2021.
Zhang Chen, Yinda Zhang, Kyle Genova, Sean Fanello, Sofien Bouaziz, Christian Hane, Ruofei Du, Cem Keskin, Thomas Funkhouser, and Danhang Tang, Multiresolution Deep Implicit Functions for 3D Shape Representation, IEEE/CVF ICCV, 2021, 13087-13096.
Towaki Takikawa, Joey Litalien, K. Yin, Karsten Kreis, Charles T. Loop, Derek Nowrouzezahrai, Alec Jacobson, Morgan McGuire, and Sanja Fidler, Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes, IEEE/CVF CVPR, 2021, 11358-11367.
GGC往期回顾
1. Daniel Cohen-Or和黄惠担任大会主席,CVM 2023开始征文了!
4. 平面四边形网格自支撑曲面的构造 | CVMJ Spotlight
您可通过下方二维码,关注清华大学计算机系图形学实验室,了解计算机图形学、Jittor框架、CVMJ期刊及会议的相关资讯。
