
计图AI算法挑战赛评测已开放,看数据集解读,赢大奖发论文!
计图 (Jittor) 人工智能算法挑战赛是在国家自然科学基金委信息科学部指导下,由北京信息科学与技术国家研究中心和清华大学-腾讯互联网创新技术联合实验室于 2021 年创办、基于清华大学Jittor深度学习框架的人工智能算法大赛。今年,该赛事将同时作为中国软件开源创新大赛中开源任务挑战赛的赛事之一,开展 AI 算法竞赛。
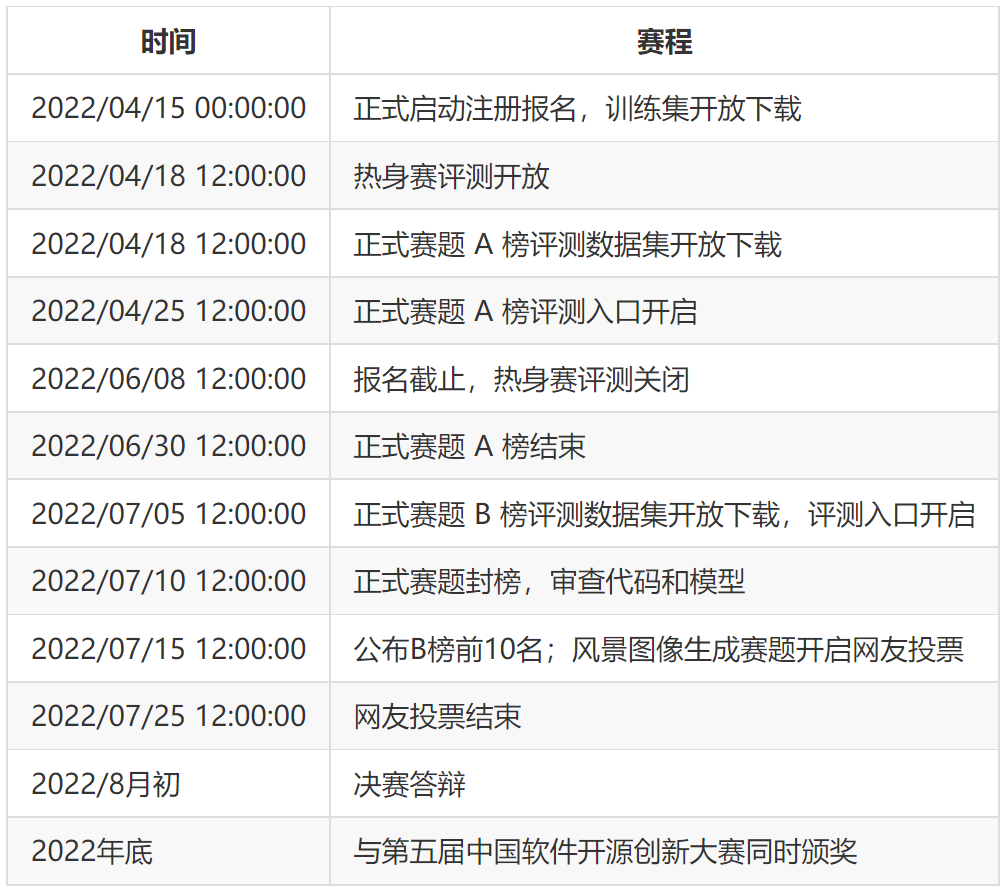
计图人工智能算法挑战赛已经于4月25日正式开放评测,大赛日程如下图所示。
截至今天,已经有相当多的选手通过了计图热身赛,并通过gitlink开源,祝贺这些选手们!
Part2
赛题以及数据集分析
A赛道:风景画生成
比赛的任务是从语义分割图生成符合语义的风景图片。如下图,给出左侧的语义分割图,生成带有天空、草地、山川的高清真实图片。

图1 语义分割图和风景图片
Mask accuary: 根据用户生成的1000张图片,使用 SegFormer 模型对图片进行分割,然后计算分割图和gt分割图的mask accuary=(gt_mask== pred_mask).sum()/(H*W),确保生成的图片与输入的分割图相对应。Mask accuary 越大越好,其数值范围是0~1。
美学评分: 由深度学习美学评价模型为图片进行美学评分,大赛组委会参考论文 [2-4] 中的论文设计了自动美学评分。
该分数将归一化到 0~1。
FID(Frechet Inception Distance score): 计算生成的 1000 张图与训练图片的FID,该指标越小越好,将FID的100到0线性映射为 0 到 1。
由于 baseline 代码的 FID 在 100 以内,所以 FID 大于 100 的将置为 100。
B赛道:可微渲染新视角生成赛题
一、赛题及数据集介绍
可微渲染近年来已成为计算机视觉、计算机图形学等领域的研究热点。论文[7]发表仅2年就收获904次引用,引发了学术界对可微渲染新视角生成的研究热潮。

图2 数据集的场景图像样例
二、评价指标
峰值信噪比(PSNR)越大越好,在B榜中会将PSNR线性映射为0到1。
三、参赛指南及相关论文参考
首先请参赛选手前往Github的Jrender仓库下载我们的比赛Baseline,并依照Readme中教程跑通Baseline,如果在跑Baseline的过程中遇到任何问题,请随时联系我们解决,我们比赛的QQ群号为1018591346。 跑通Baseline后建议参赛选手通读参考文献[7],理解Baseline仓库config文件中各参数的含义根据具体场景进行调整。 NeRF虽然在漫反射场景上取得了不错的效果,但在高光、折射、布料复杂材质等场景上的效果仍需提高。在近期的SIGGRAPH,CVPR,ECCV,ICCV等会议上有很多论文针对NeRF的痛点进行了改进,具体请参考awesome-NeRF仓库 https://github.com/yenchenlin/awesome-NeRF 中给出的论文列表。期待大家在Baseline的基础上,实现更多更好的算法,更期待大家能有所创新,在可微渲染新视角生成领域做出新的贡献。
Part3
比赛奖励及成果发表
大赛组委会除了提供有腾讯赞助、高达28万的丰厚奖金,还将为选手提供以下福利:
比赛中表现优异的队伍有机会获得赛事专家委员会的推荐信(用于出国或推研)。 比赛中涌现出来的创新算法和AI模型,将被邀请提交论文到SCI期刊Computational Visual Media上发表。 可以获得腾讯校园招聘(包括实习)的绿色通道或其他便利,可提升简历曝光度及面试发起率。
欢迎大家积极报名参赛!
比赛报名: https://www.educoder.net/competitions/index/Jittor-3 选手可以在计图讨论社区的挑战赛专栏参与讨论:
https://discuss.jittor.cn/c/competion/7 赛事交流QQ群:1018591346,请填写“战队名称+真实姓名”提交入群申请。
此外,大赛还采用“腾讯乐享犀牛鸟校园”作为在线学习交流平台,后续将与QQ群同步开展
参考文献
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo, SegFormer: Simple and efficient design for semantic segmentation with transformers, NeurIPS 2021.
Dongyu She, Yu-Kun Lai, Gaoxiong Yi, Kun Xu, Hierarchical layout-aware graph convolutional network for unified aesthetics assessment, CVPR 2021, 8475-8484.
Hossein Talebi, Peyman Milanfar, NIMA: Neural image assessment, EEE Transactions on Image Processing, 2018, Vol. 27, No. 8, 3998-4011.
Jun-Tae Lee; Chang-Su Kim, Image aesthetic assessment based on pairwise comparison a unified approach to score regression, binary classification, and personalization, ICCV 2019, 1191-1200. Tero Karras, Samuli Laine, Timo Aila, A Style-Based Generator Architecture for Generative Adversarial Networks, CVPR 2019, 4401-4410. Tero Karras; Samuli Laine; Miika Aittala; Janne Hellsten; Jaakko Lehtinen; Timo Aila, Analyzing and Improving the Image Quality of StyleGAN, CVPR 2020, 8107-8116.
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi & Ren Ng, NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis, ECCV 2020, 405–421.
