
Jittor团队提出大核注意力,开源新的骨干网络VAN
2022年2月22日,清华大学计图团队和南开大学程明明教授团队合作,在ArXiv上发布一篇关于视觉骨干网络的论文Visual Attention Network,介绍了一个新的骨干网络 VAN,在图像分类、目标检测和语义分割任务上均取得了优异的效果。
Part1
最近,各种基于注意力机制的视觉模型层出不穷,并迅速应用在了计算机视觉的各种任务中。2021年 11 月,清华大学的计图团队和南开大学程明明教授团队合作发布了一篇计算机视觉中的注意力机制的综述[1],曾列arXiv的周排行榜第一名。
通过完成这篇综述,作者意识到,如果从 transformer 的角度去看自注意力机制,那么自注意力机制是transformer 中不可或缺的一部分,但是从注意力机制的角度去看自注意力机制,那么自注意力机制就是一种特殊的注意力机制,完全可能被替代。
这篇文章中,计图团队提出了一种全新的针对于视觉任务的注意力机制 ——大核注意力(Large-Kernel Attention, LKA),其机理和self-attention不同。基于这种大核注意力机制,作者提出了一种简单且有效的视觉骨干网络 Visual Attention Network (VAN), 该网络在图像分类、目标检测和语义分割任务上均取得了优异的效果。
Part2
自注意力擅长处理一维的序列结构,如果直接用于处理图像,会忽略图像自身的二维结构信息,而数据自身的结构信息是重要的。
由于自注意力自身复杂度的问题,难以用于处理高分辨率图像。
自注意力机制仅仅考虑了空间维度上的自适应性,而忽略了通道维度上的自适应性,而通道自适应性已经在 SENet[2] 等工作中证明了在视觉任务中的重要性。
自注意力机制可以捕获长距离依赖。
自注意力具有空间自适应性。
卷积可以高效地利用图像的局部信息。
卷积可以利用图像的二维结构信息。
Part3
注意力机制
注意力机制可以理解为:计算机视觉系统在模拟人类视觉系统中可以迅速高效地关注到重点区域的特性。注意力过程是一个自适应(动态)过程,根据输入去调节输出的过程。
注意力机制大概可以分成两个步骤: 1)得到注意力图(attention map),2)根据注意力图对输入进行处理。
如何判断一个点的重要程度呢 ?
由于缺乏语义信息,根据单个点的信息,你难以判断这个点重要还是不重要,你需要知道它周围点的信息你才可以进行判断。所以我们需要得到周围点的信息,并且点越多(long-range dependence),可能判断的就越准确。如图1所示,attention map表示表示每个点的重要程度,你需要知道周围点的信息,才能判断一个黄色点的重要性。
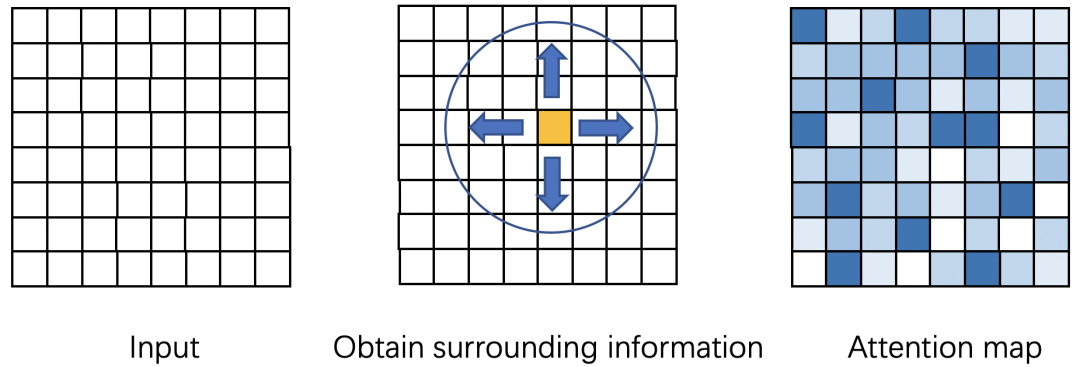
图1 attention map的计算原理
有两种常见的方法:1) 使用自注意力机制。在研究动机中已经讲述了在视觉中使用自注意力机制的不足。2) 使用大核卷积来捕捉长距离依赖。使用该方法的不足在于,大卷积核的参数量和计算量太大,难以接受。
本文针对 2) 进行了改进,提出了一种新的分解方式,用于减少大卷积的计算量和参数量。
如图2所示:我们可以将一个Kx K 的大卷积分解成三部分:
a) 一个(K/d) x (K/d) 的depth-wise dilation convolution,其中dilation的大小为d;
b) 一个(2d-1)x (2d-1) 的 depth-wise convolution;
c) 一个 1x1 卷积。
这种分解可以理解为如何选择三种基本的构件来布满整个卷积空间。图2展示了将一个 13 x 13 的卷积分解成一个 5 x 5 的 depth-wise convolution 、一个 5 x 5 的depth-wise dilation convolution,和一个 1 x 1 的卷积,其中 d = 3 。
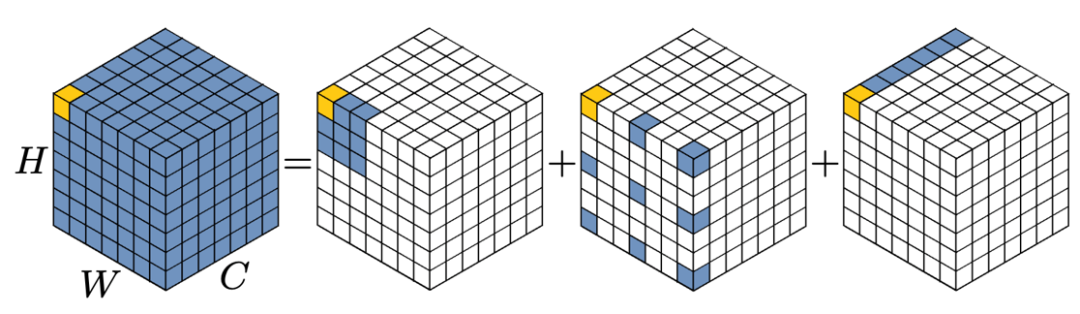
图2 13 x 13 卷积的分解
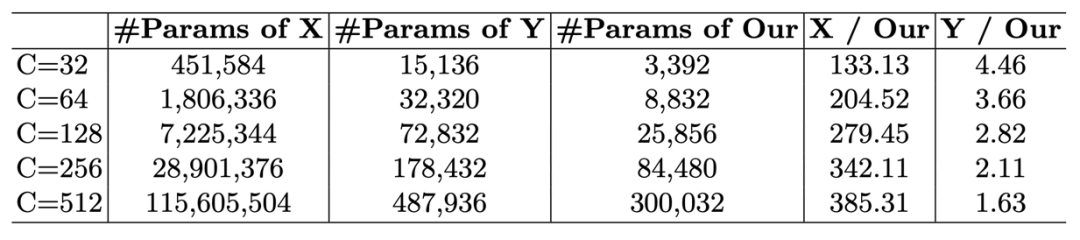
大核注意力 (LKA)
下面给出大核注意力的实现方式,
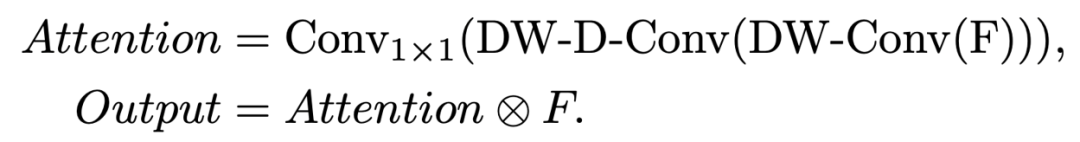
其中DW-Conv 表示 depth-wise convolution, DW-D-Conv 表示 depth-wise dilation convolution, Conv1x1 表示1 x 1 卷积。⊗ 表示逐元素相乘。
我们可以用图来表示神经网络模块,图5(a) 即为本文提出的大核注意力 (Large Kernel Attention);5(b)是传统的卷积网络模块;5(c)是自注意力模块;5(d)是 VAN 的一个Stage,CFF 表示卷积前馈网络。
可以看到,5(a) 和 5(b) 之间的区别是元素乘法。值得注意的是,5(c)最初是为一维序列设计的。
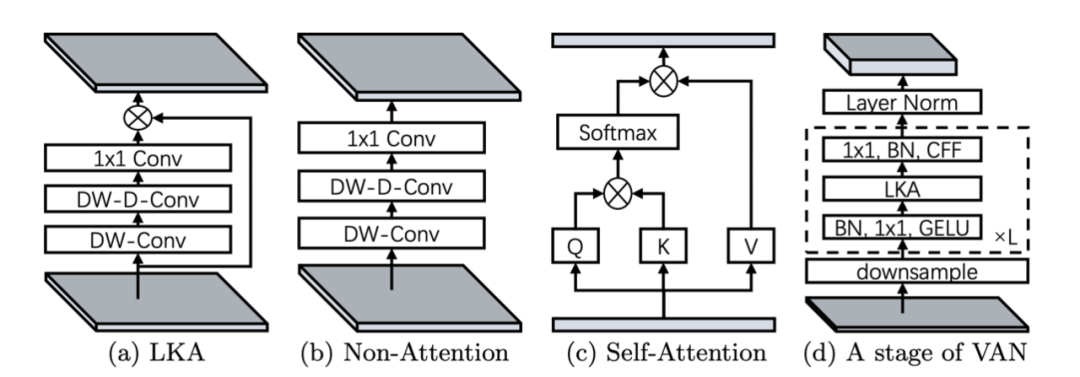
图3 不同模块的结构
视觉注意力网络VAN
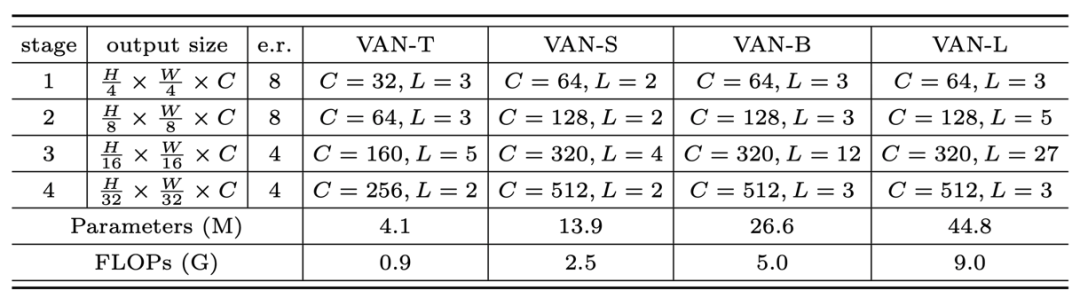
基于LKA,就可以搭建一个新的视觉骨干网络。文中使用了类似层次化transformer 的结构,即 Attention-FFN 结构,具体如表2所示。作者给出了四种不同大小的VAN网络 (Tiny, Small, Base, Large),具体配置如下。
Part4
作者针对图像分类、检测和分割等任务做了实验,并和 Swin Transformer[4] 以及 ConvNeXt[5]进行了详尽的对比和分析,具体详见论文的实验章节。这里仅展示分类实验结果和可视化结果。
在ImageNet上,不同骨干网络的分类实验结果如下:
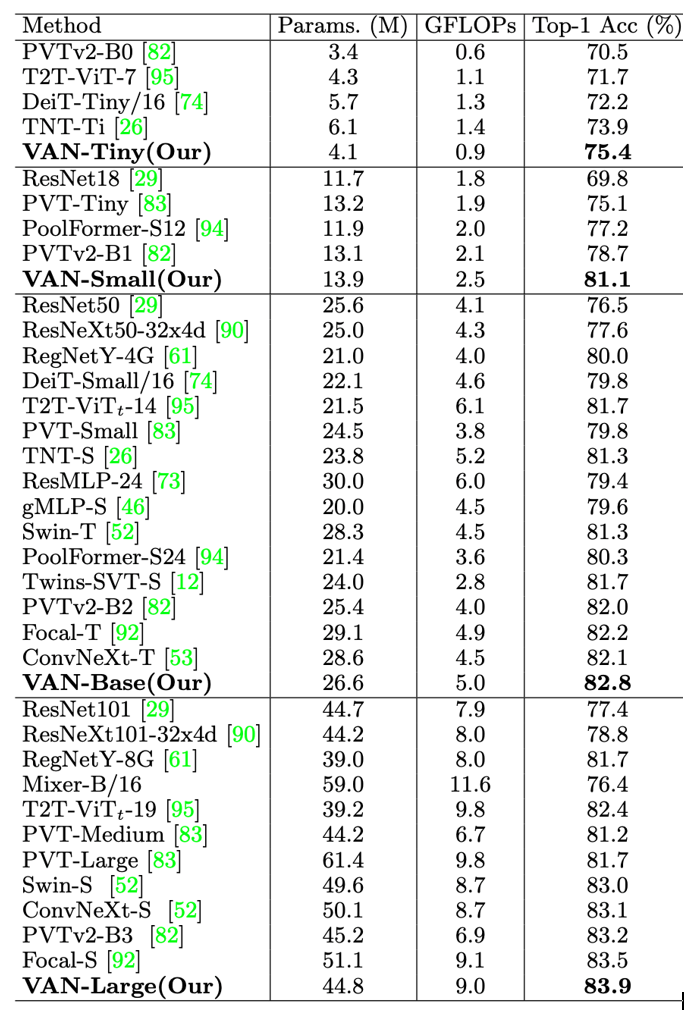

图4 表3中VAN-base的可视化效果
论文的第一作者是清华大学的博士生国孟昊,其他作者还包括南开大学硕士生陆承泽、清华大学博士生刘政宁、南开大学程明明教授和清华大学胡事民教授。VAN论文的arXiv链接为
https://arxiv.org/abs/2202.09741
VAN的计图代码已经在Github开源,链接为
https://github.com/Visual-Attention-Network/VAN-Jittor
参考文献
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R. Martin, Ming-Ming Cheng, Shi-Min Hu, Attention Mechanisms in Computer Vision: A Survey, Computational Visual Media, 2022, Vol. 8, 35 pages.
Jie Hu, Shen Li, Samuel Albanie, Sun Sun, Enhua Wu, Squeeze-and-excitation networks, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, Vol. 42, No. 8, 2011-2023.
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Heng Zhang, Stephen Lin, Baining Guo, Swin transformer: Hierarchical vision transformer using shifted windows, IEEE ICCV 2021, 10012-10022.
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, A convnet for the 2020s, arXiv:2201.03545, 2022.
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. IEEE ICCV, 2017, 618-626.
2. 计算机图形学教学研讨会1月18日举行,18位知名学者共议图形学教学与人才培养
3. 第六期“计图”论坛:计算机视觉中的注意力模型,将于1月6日举办
4. 首届JDC召开,计图技术委员会评出2021年度优秀Jittor开源项目
