
综述 | 计算机视觉中的注意力机制
https://github.com/MenghaoGuo/Awesome-Vision-Attentions专门用于收集注意力机制的相关论文。
该综述论文的第一作者是胡事民教授的博士生国孟昊。他也是计图团队发布的点云Transformer(PCT)一文的第一作者;其他作者还包括清华大学张松海副教授、穆太江博士,以及清华和南开的多名博士生。
Part 1
人类视觉系统可以自然高效地找到复杂场景中的重要的区域,受到这种现象的启发,注意力机制(Attention Mechanisms)被引入到计算机视觉系统中。注意力机制已经在计算机视觉的各种任务(如:图像识别、目标检测、语义分割、动作识别、图像生成、三维视觉等)中取得了巨大的成功。
但是,研究人员在研究不同任务的注意力机制的时候,往往注重的是任务本身,而忽略了注意力机制本身就是一个研究方向,是一个尝试用计算机视觉系统模拟人类视觉系统的研究方向。
该综述尝试从两个角度将视觉中不同任务中的注意力机制连接成一个整体——从注意力机制本身出发,对整个领域进行了系统地总结归纳,并给出了未来潜在的研究方向。
Part 2
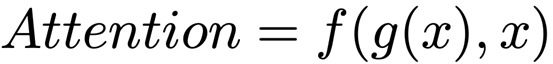
其中 g(x) 表示对输入特征进行处理并产生注意力的过程,f(g(x),x) 表示结合注意力对输入特征进行处理的过程。举两个具体的例子self-attention[2]和senet[3],对于 self-attention 来说,可以将上述公式具体化为:
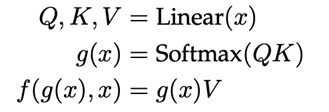
对于 senet 来说,可以将上述公式具体化为:
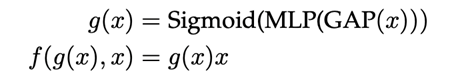
接下来,该综述尝试将不同的注意力机制进行具体化,即明确 g 过程和 f 过程。这是该综述对注意力机制的第一个统一的角度:定义上的统一。
Part 3
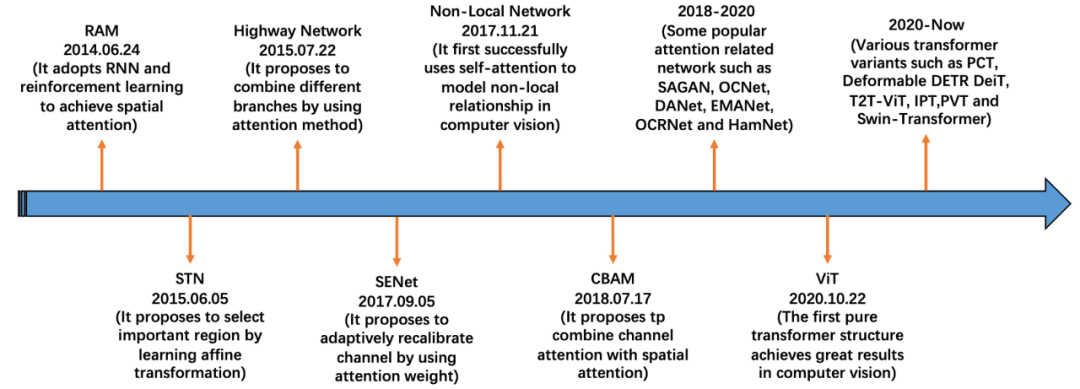
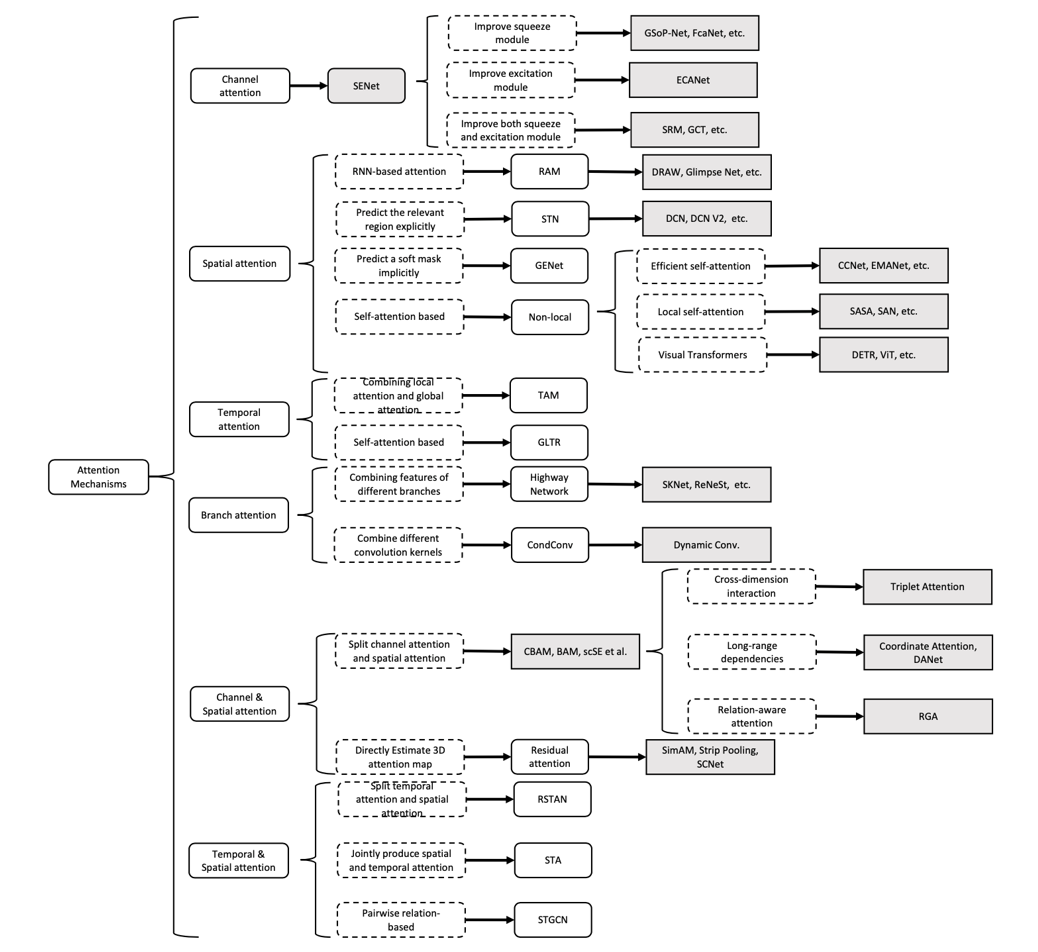
图2 视觉中注意力机制的发展过程
Part 4
作者根据注意力方法本身对视觉中不同的注意力机制进行了分类,而不是根据不同的应用,从而对注意力机制的研究给了一个统一的视角。
如图三所示,作者根据注意力作用的不同维度将注意力分成了四种基本类型:通道注意力、空间注意力、时间注意力和分支注意力,以及两种组合注意力:通道-空间注意力和空间-时间注意力。
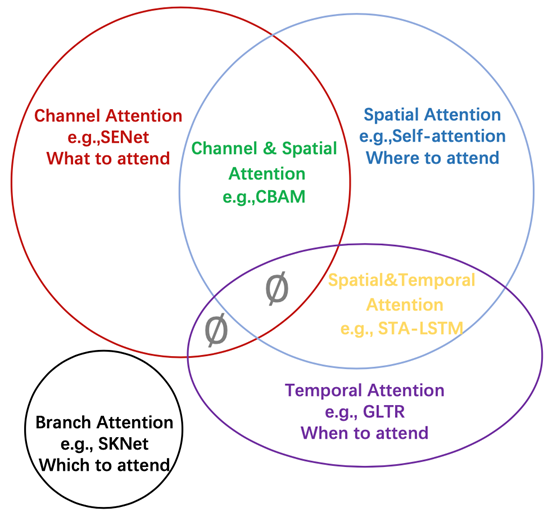
图3 将视觉中注意力机制的分类示意图
图4进一步给出图3中注意力的具体解释。
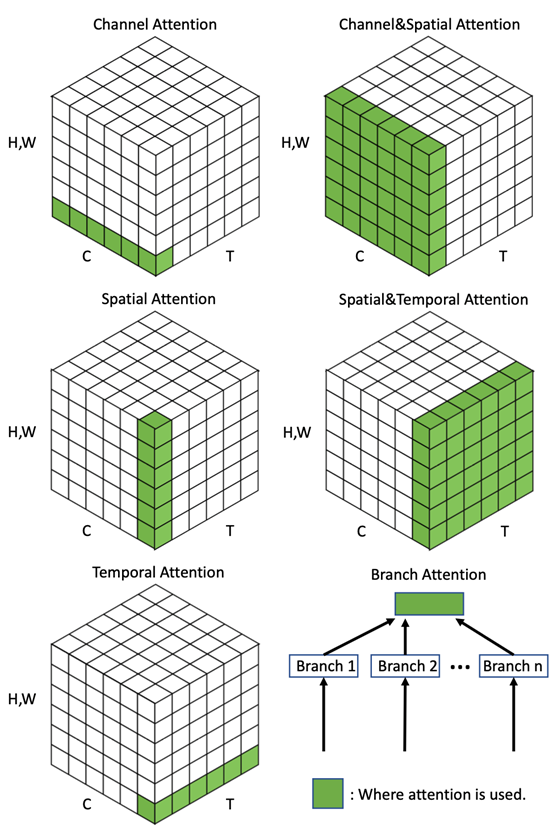
图4 注意力机制的分类的可视化展示
不难发现,对于不同的注意力机制,他们有着不同的含义,比如对于通道注意力,它关注于选择重要的通道,而在深度特征图中,不同的通道往往表示不同的物体,所以它的含义是关注什么(物体),即what to attend。
同理,空间注意力对应 where to attend, 时间注意力对应 when to attend,分支注意力对应 which to attend。具体的注意力机制请参见论文。
Part 5
注意力机制的充分必要条件 更加通用的注意力模块 注意力机制的可解释性 注意力机制中的稀疏激活 基于注意力机制的预训练模型 适用于注意力机制的优化方法 部署注意力机制的模型
M.-H. Guo, T.-X. Xu, J.-J. Liu, Z.-N. Liu, P.-T. Jiang, T.-J. Mu, S.-H. Zhang, R. R. Martin, M.-M. Cheng and S.-M. Hu, Attention Mechanisms in Computer Vision: A Survey,arXiv 2111.07624.
X. Wang, R. Girshick, A. Gupta, K. He, Non-local neural networks, CVPR 2018, 7794-7803.
J. Hu, L. Shen, S. Albanie, G. Sun, E. Wu, Squeeze-and-excitation networks, IEEE TPAMI, 2020,Vol. 42, No. 8, 2011-2023
V. Mnih, N. Heess, A. Graves, K. Kavukcuoglu, Recurrent models of visual attention, NeurIPS 2014,2204-2212.
M. Jaderberg, K. Simonyan, A. Zisserman, K. Kavukcuoglu, Spatial transformer networks, NeurIPS 2015, 2017-2025.
J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, Y. Wei, Deformable convolutional networks, ICCV 2017, 764-773.
X. Zhu, H. Hu, S. Lin, J. Dai, Deformable convnets v2: More deformable, better results, CVPR 2019, 9308-9316.
S. Woo, J. Park, J. Lee, and I. S. Kweon, CBAM: convolutional block attention module, ECCV 2018, 3-19.
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, An image is worth 16x16 words: Transformers for image recognition at scale, ICLR, 2021, 1-21.
您可通过下方二维码,关注清华大学图形学实验室,了解图形学、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
