
计图开源:基于跨模态实例与类别对比学习的单张图像三维模型检索
近期,中科院计算所、阿里巴巴淘系、北京大学与英国卡迪大学的研究团队在IEEE ICCV 2021发表了一项研究工作[1]。该工作提出了一种新颖的基于跨模态对比学习 (contrastive learning) 的单张图像三维模型检索方法,大幅提高了三维模型检索的准确率,取得了SOTA的性能,并开源了基于计图实现的代码。
由于深度学习和具有丰富对象与类别的三维模型数据集的发展,及其在场景重建、三维打印、虚拟现实和电子商务平台等领域的广泛应用,基于单张真实图像的三维模型检索任务最近获得了较多的关注。

图1 检索可视化结果
由于二维检索图像与三维模型是不同模态的数据,因而无法直接进行相似度的计算。该方法先使用平面阴影渲染的方式将三维模型转化成其所对应的多视角单通道灰度图来进行表示。
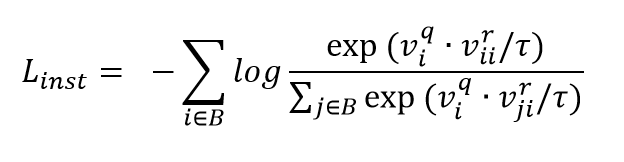
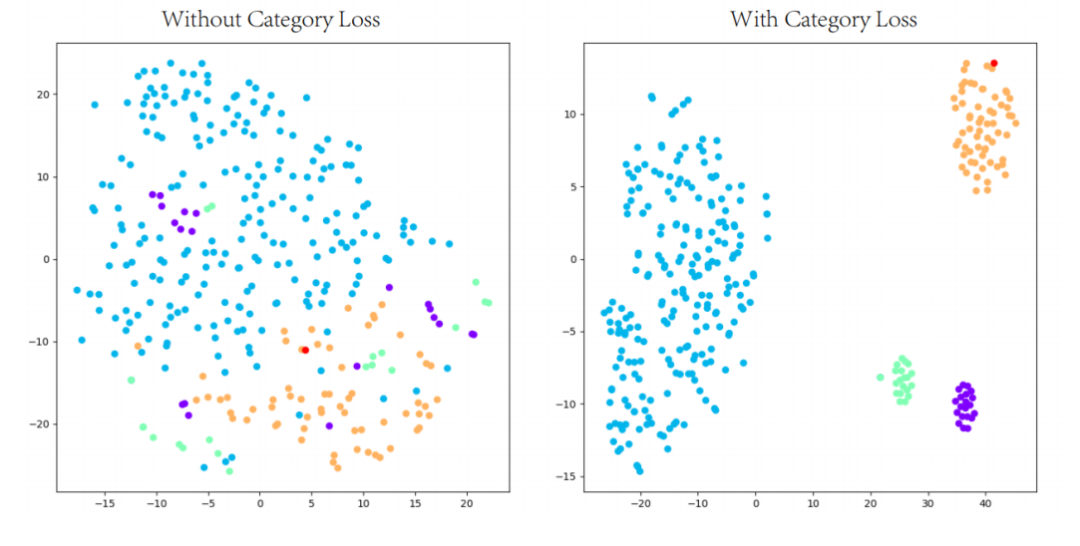
为了减小数据标签中类别信息对于检索网络的干扰,该方法从类别角度也进行监督。此时的正样本为其所对应的三维模型具有相同类别标签的其它所有三维模型。因此,类别级别的损失项以编码的形式表示为:
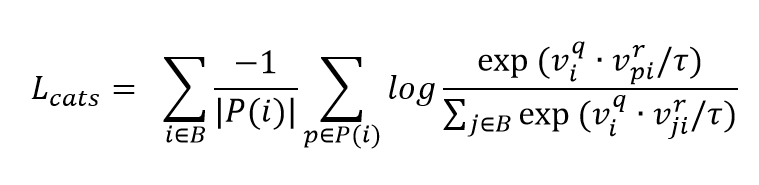
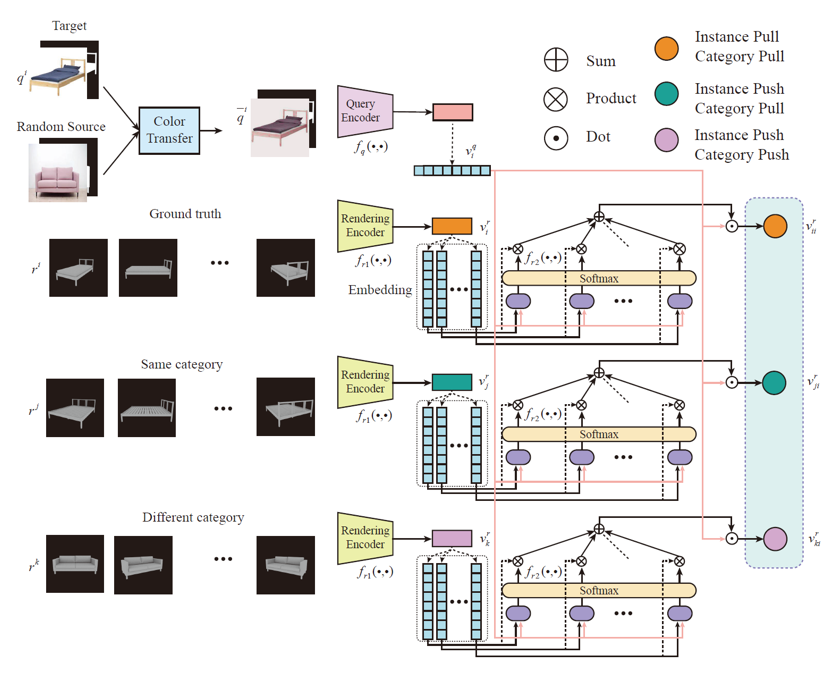
在测试过程中,检索图像编码器的输入不再经过颜色转换模块而被直接使用。通过计算检索图像与所有三维模型的相似度,选出相似度最高的模型作为检索结果。
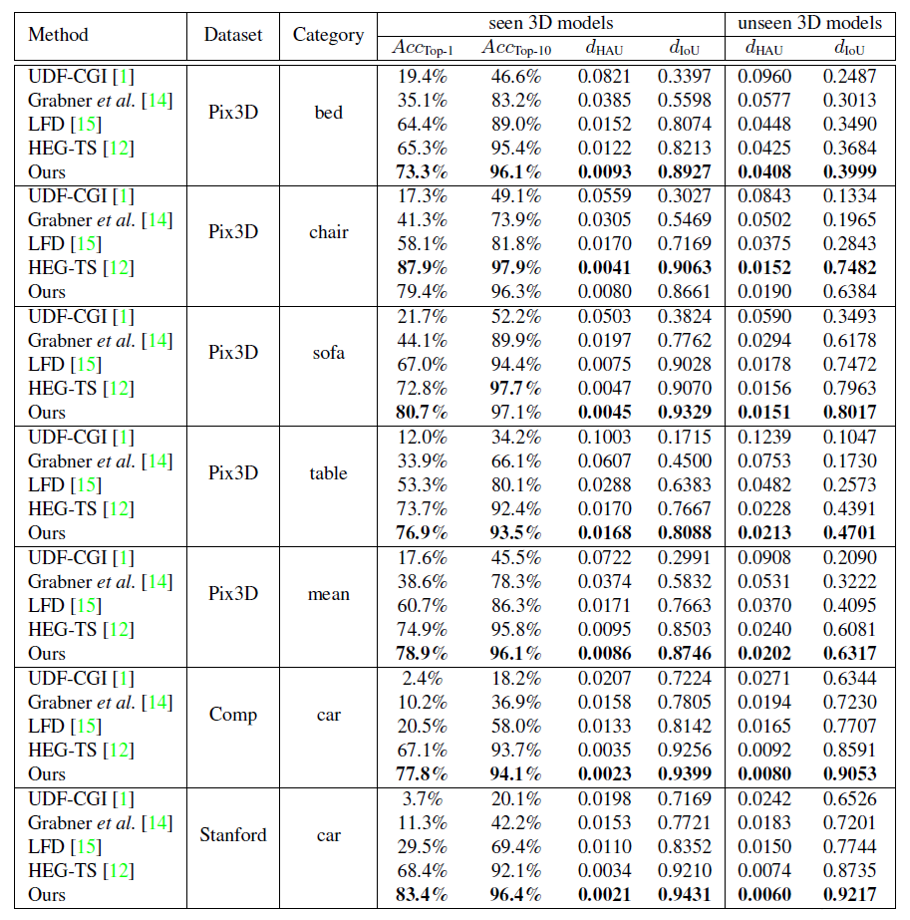
表1 与现有方法的量化指标对比结果

该论文作者包括中科院计算所的林明仙和高林副研究员 (通讯)、北京大学王鹤助理教授、英国卡迪夫大学Yu-Kun Lai教授、阿里巴巴淘系部门贾荣飞博士和赵斌强资深算法专家等。
该研究项目基于计图实现的代码链接为:
https://github.com/IGLICT/IBSR_jittor。
在Jittor框架的加持下,在相同参数条件下,基于计图实现的训练速度是PyTorch版本的1.78倍,推理速度是PyTorch版本的1.26倍。
参考文献
Ming-Xian Lin, Jie Yang, He Wang, Yu-Kun Lai, Rongfei Jia , Binqiang Zhao, Lin Gao*, Single Image 3D Shape Retrieval via Cross-Modal Instance and Category Contrastive Learning. IEEE International Conference on Computer Vision (ICCV),2021.
Alexander Grabner, Peter M. Roth, and Vincent Lepetit, Location field descriptors: Single image 3D model retrieval in the wild. In International Conference on 3D Vision (3DV), 583–593, 2019.
Huan Fu, Shunming Li, Rongfei Jia, Mingming Gong, Binqiang Zhao, and Dacheng Tao, Hard example generation by texture synthesis for cross-domain shape similarity learning. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan,and H. Lin, editors, Advances in Neural Information Processing Systems, Vol. 33, 14675–14687. Curran Associates, Inc., 2020.
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan, Supervised contrastive learning. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin,editors, Advances in Neural Information Processing Systems, Vol. 33, 18661–18673. Curran Associates, Inc., 2020.
Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. Colortransfer between images. IEEE Computer graphics and applications, Vol. 21, No. 5, 34–41,2001.
您可通过下方二维码,关注清华大学图形学实验室,了解计算机图形学、Jittor深度学习框架、CVMJ期刊和CVM会议的相关资讯。
