
计图开源:三维几何模型的可微变形分析与编辑方法
近期,中科院计算所高林团队于IEEE TPAMI发表了一项重要的研究成果[1],提出了一种新颖的三维模型局部变形基底分析方法和可微几何模型编辑建模方法,并已开源了基于计图实现的代码,网络模型的训练速度较Tensorflow提升53%。
Part 1
三维几何模型的交互式变形是计算机图形学中被广泛研究的主题。在工业界,动画、电影和游戏制作,也经常通过几何模型变形的方式使虚拟人物运动起来。这涉及到通过操控预先定义好的控制顶点或骨架,来驱动几何模型运动得到运动序列。
一种常用的几何变形方法是基于数据驱动的方法,它通过对变形基底进行加权混合得到变形结果。一个复杂动作可以被分解为多个简单动作,比如人扎马步的动作,可以被拆解为单个胳膊与腿部的运动。
创作者通过找到一系列简单的动作,对这些动作做组合,就可以得到大量的复杂动作。这简化了创作流程,提高了创作效率。因此,这类变形方法的任务之一,是分析复杂的变形过程,提取得到模型的基本动作,即所谓的变形基底。
高林团队提出的方法通过频域上的图卷积实现模型几何变形特征的编码,并且提出了可微的区域动态稀疏编码方法用于分析复杂几何模型的局部变形基底,进一步的提出了可微分的几何模型建模方法,提高了几何建模的效率和质量。图1展示了基于该方法的可微几何模型编辑结果。
Part 2
变形基底需要具有一个非常关键的性质——稀疏性。例如,当用户编辑人体模型变形时,若只对胳臂进行编辑,通常并不希望腿也会跟着运动,即编辑局部区域不会影响其他区域。若一个变形基底同时涉及到胳臂和腿的运动,那最后组合的复杂运动很难实现单独的编辑胳臂或编辑腿的效果。
在本方法中,作者通过神经网络自动提取变形基底,同时考虑了变形基底的稀疏性。网络首先需要对网格模型数据进行编码,而数据集中具有的大尺度变形很难直接用深度学习方法编码。因此,作者采用了可表示大尺度变形的ACAP特征[2]来表示三维模型,然后通过变分自编码器网络将特征编码至低维的隐含层空间中,隐含层特征每一维的变化代表一个变形基底的变化。
但此时经过网络编码得到的隐含层特征,并不具备表示稀疏变形基底的能力。直接编码学习得到的隐含层特征与模型的每个顶点都有关联,而变形基底的“稀疏性”则要求一个基底只与部分顶点相关联,这需要对网络添加额外的约束。因此,作者对顶点与基底之间的网络权重添加约束,惩罚那些远离变形区域的点,使得他们的权重趋向于0,具体定义如下:
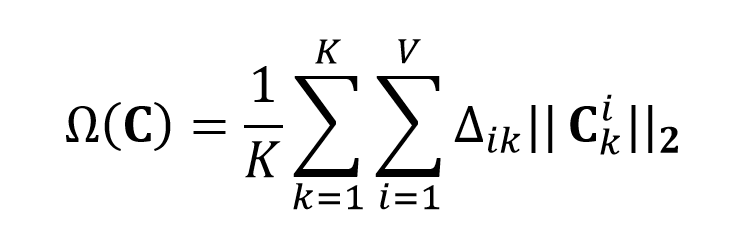
以权重最大的点作为该区域的中心点,对到中心点测地线距离超过一定阈值的顶点的权重进行惩罚,因此惩罚项的权重计算如下:
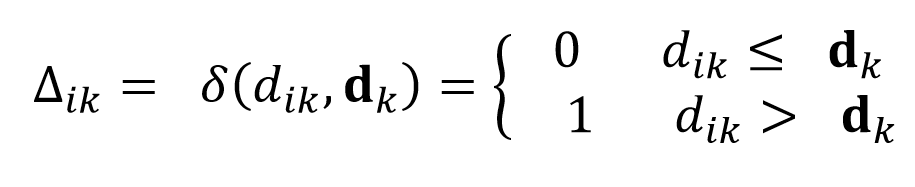
对于阈值的确定,传统方法会人工预先定义好后进行计算,而本文利用网络学习得到不同区域的阈值大小,这使得提取出来的基更加有效和合理。从惩罚项的公式中可以看出网络训练过程中倾向于增加阈值的大小,使得结果失去稀疏性,因此,作者引入了对阈值的L2正则项约束,防止阈值过大。另外,由于上述分段函数无梯度,作者采用Bengio等人[3]的方法来计算近似梯度。
除了上述用于保证提取局部基底的损失函数,作者还使用了均方误差(MSE)的重建损失函数和KL散度损失函数等。网络使用Adam优化器,学习率设定为0.001。
基于本文的变形基底提取网络,作者进一步提出了一个新颖的可微模型编辑方法,不需要显式的提取基底,将基底提取与模型变形两个步骤均用一个网络实现。具体来说,将模板模型输入到训练好的网络中,对用户指定的控制顶点添加损失函数,通过梯度下降对隐含层特征进行优化,得到最终的变形结果。其中,损失函数定义如下:
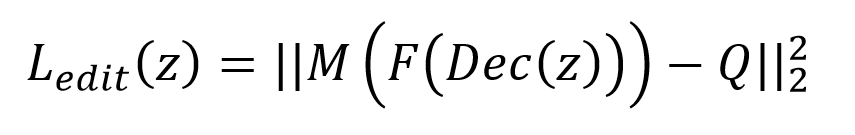
F表示从ACAP特征重建顶点坐标的可微网络层。M表示提取用户指定控制顶点的函数,Q表示控制顶点的目标移动坐标。通过对上述损失函数进行优化,在控制顶点位置移动的驱动下,模板模型逐渐变形至满足控制顶点目标位置的形态。由于网络采用了稀疏约束,并且学习到了模型的合理动作空间,通过少量的控制顶点即可实现高效高质量的模型编辑效果。
Part 3
下面的表格展示了该方法在Swing, Face, Jumping, Humanoid, Fat, SCAPE和Female等常见数据集上与现有几何变形方法的对比结果,该方法在绝大部分数据集上取得了业界最优的效果。

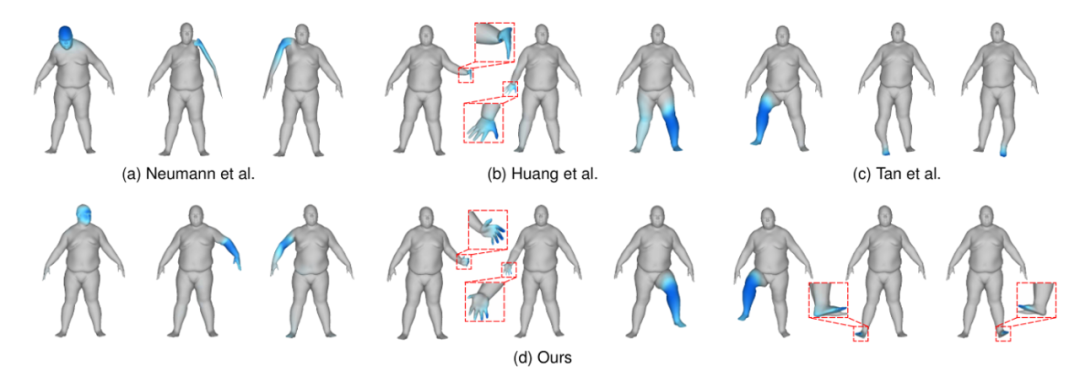
图2 不同尺度的变形基底提取结果的对比
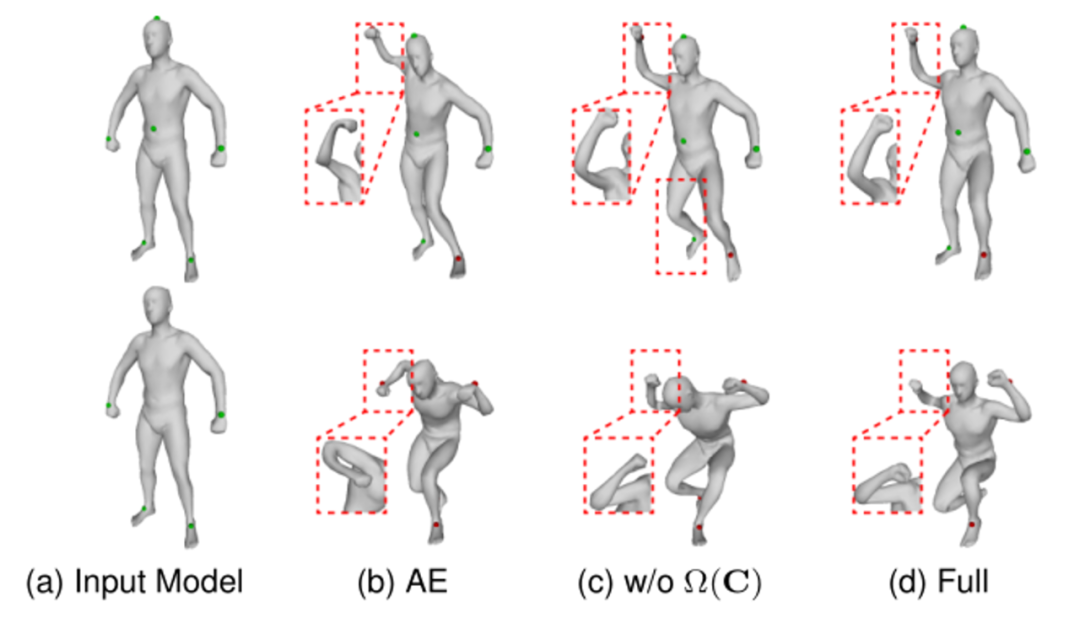
图3 可微几何模型编辑结果对比
图4 更多可微几何模型编辑结果
Part 4
三维模型变形基底提取以及模型编辑,是三维模型处理的重要研究内容之一,传统的基于数据驱动的模型编辑方法,需要显式的提取变形基底进行编辑,本文介绍的方法通过一个网络将变形基底提取与模型编辑两个步骤融合,实现了高效高质量的可微模型编辑。
该论文作者还包括中科院计算所的张凌霄,美国马里兰大学的Qingyang Tan博士和英国卡迪夫大学的Yu-Kun Lai教授等人。该研究项目已发布基于计图实现的代码,链接为
https://github.com/IGLICT/MeshVAE_neural_editing。
在Jittor框架的加持下,模型所需的显存空间仅为Tensorflow的75%,能够有效节省显存消耗。在相同显存空间的条件下,基于计图实现的网络模型训练速度是Tensorflow的1.53倍,能够在相同的配置条件下有效提升训练的效率。
Qingyang Tan#, Ling-Xiao Zhang#,Jie Yang, Yu-Kun Lai, and Lin Gao*, Variational Autoencoders for Localized Mesh Deformation Component Analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021. Lin Gao, Yu-Kun Lai, Jie Yang, Ling-Xiao Zhang, Shihong Xia, and Leif Kobbelt, Sparse Data Driven Mesh Deformation, IEEE Transactions on Visualization and Computer Graphics, 2021, Vol. 27, No.3, 2085-2100. Bengio Yoshua, Nicholas Léonard, and Aaron Courville. Estimating or Propagating Gradients through Stochastic Neurons for Conditional Computation. arXiv preprint, arXiv:1308.3432, 2013.
GGC往期回顾
您可通过下方二维码,关注清华大学图形学实验室,了解计算机图形学、Jittor深度学习框架、CVMJ期刊和CVM会议的相关资讯。
