
计图开源:隐蔽目标检测新任务在计图框架下推理性能大幅提升
近期,阿联酋起源人工智能研究院(IIAI)邵岭教授团队和南开大学程明明教授团队联合构建了隐蔽目标检测(Concealed Object Detection)新任务。团队发布了COD10K数据集,涵盖了真实场景中78个不同类别目标所组成的10,000张图像样本,并提出一种基于分组反向注意力的基线模型,该研究成果发表于IEEET-PAMI[1]。
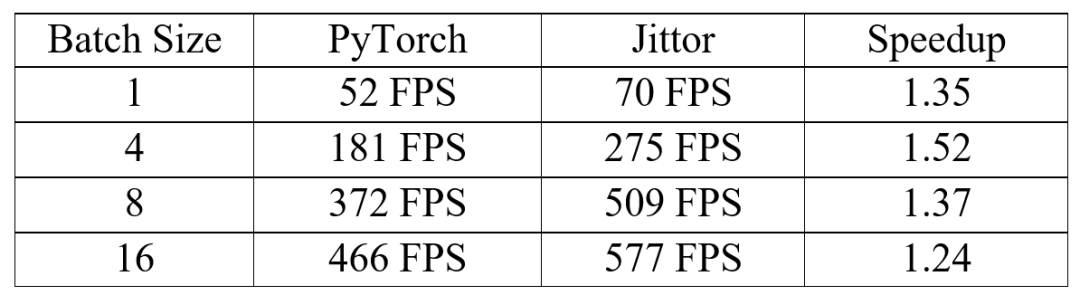
基于Jittor框架下的算法模型相比于PyTorch框架,网络推理性能大幅提升,在Batch Size为4时,在Nvidia RTX TITAN显卡上能实现1.52倍的推理加速。
Part1
让我们先看一张背景匹配伪装(Background Matching Camouflage)的示例。左图和右图分别隐藏了七只和六只小鸟。计算机能否自动检测到那些隐藏的目标呢?

图1 背景匹配伪装示例
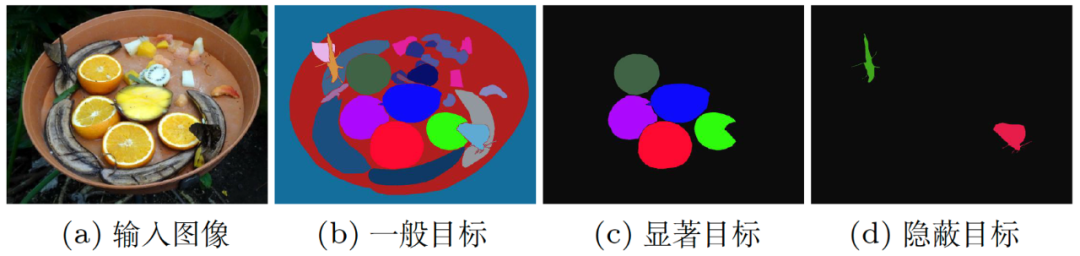
近年来,目标检测任务得到了越来越多的关注,但与隐蔽目标检测任务相关的研究却很少见,主要是因为缺乏超大规模的数据集和诸如Pascal-VOC[6]和ImageNet [7]这样标准的基准评测。本文的作者呈现了第一个基于深度学习的隐蔽目标检测任务的完备研究,从隐蔽视角来重新看待目标检测任务。
Part2
隐蔽目标与其周边环境之间高度的内在相似性使得COD 任务比传统的目标检测/分割任务更具挑战性。
为了更好地理解这项任务,团队作者收集了一个名为COD10K 的大规模数据集(见图3),由10,000 张图像组成,共计78个类别,这些隐蔽目标均来自各种真实场景。
图3给出了COD10K 数据集的统计信息和伪装类别示例,(a)为分类系统及其直方图分布,(b)为图像分辨率分布,(c)为词云分布, (d)为对象/实例的类别数量,(e)为子类示例。
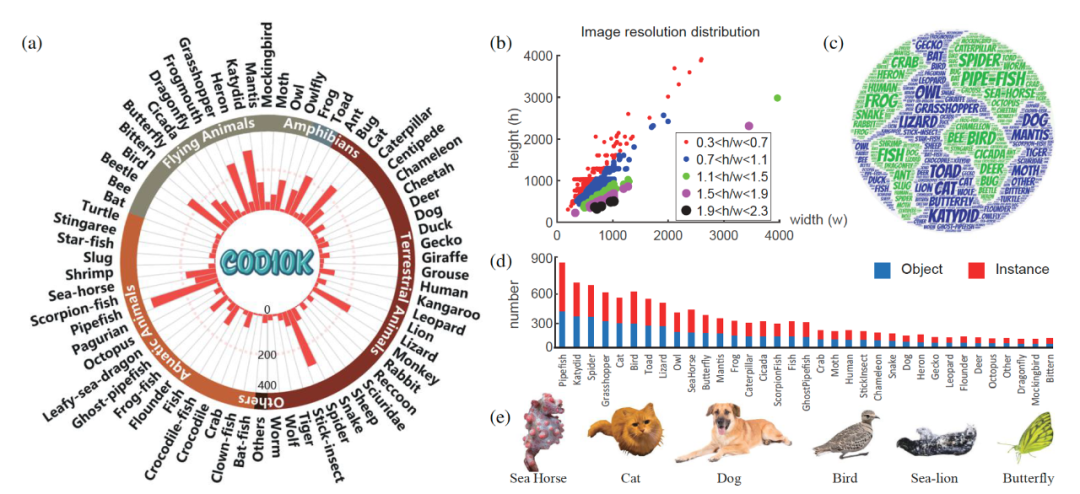
图3 COD10K 数据集
此外,作者还提供了丰富的标签,包括目标类别、目标边界、具有挑战性的属性、目标级别掩膜和实例级别掩膜。如图4所示,与以往工作中仅提供粗糙的目标级别标签相比,本文为每一张图片提供了六种不同的标签,包括属性和类别(第一行)、边界框(第二行)、目标级别标签(第三行)、实例级别标签(第四行)和边缘标签(第五行)。

图4 COD10K 数据集的标签多样性
受到动物在野生环境下狩猎过程的启发,作者还设计了一个简单且鲁棒的基线模型,名为搜索识别网络(Search andIdentification Network, SINet)。
如图5所示,SINet包含了三个主要的部件:纹理增强模块(TEM)、近邻连接解码器(NCD)和分组反向注意力(GRA)。TEM 用于模仿人类视觉系统中感受野对特征的抽取。NCD 则在TEM 的协助下负责定位候选区域。GRA 模块则会重现动物狩猎的识别阶段。
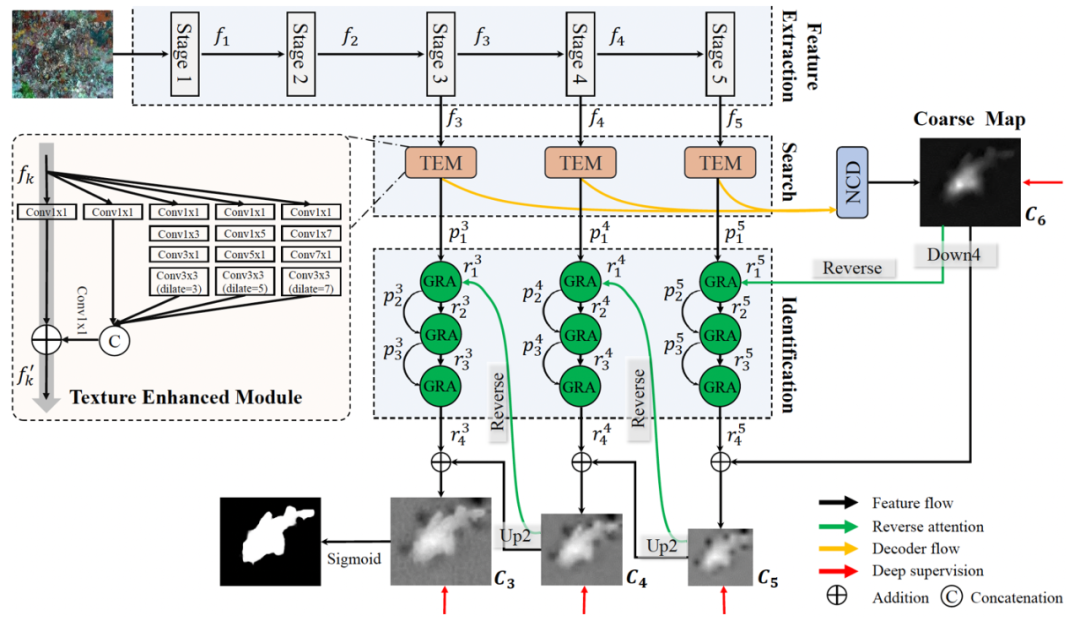
图5 COD框架
如图6所示,名为分组反向注意力的GRA模块是一个残差学习过程,其借助于反向引导和分组引导操作来达到特征学习的目的。通过进一步组合多个GRA 模块来逐步提纯来自不同特征金字塔的粗糙预测结果。
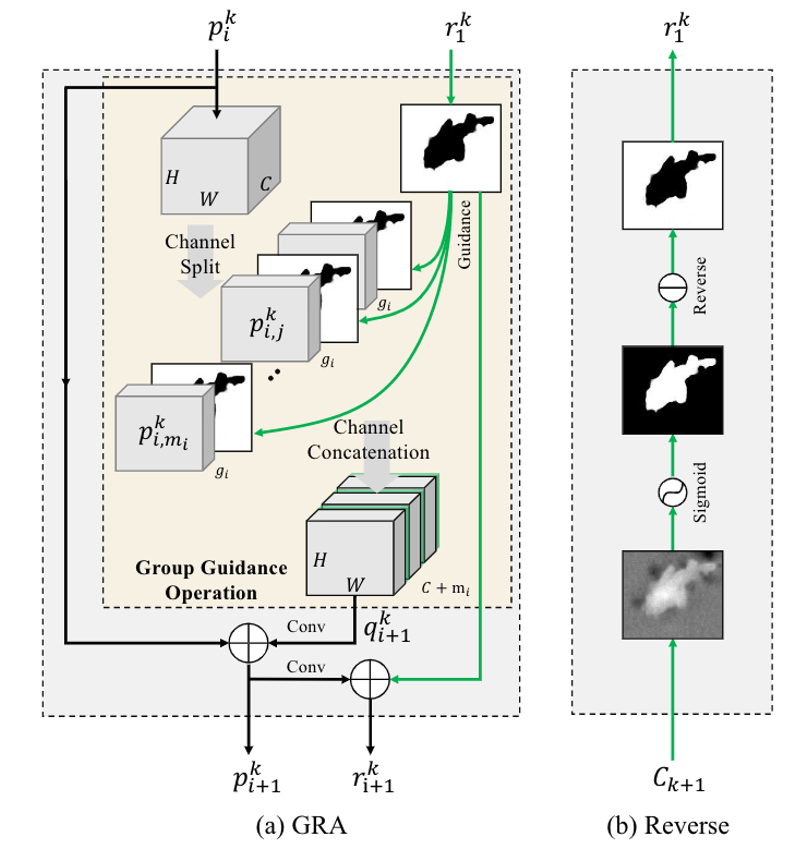
图6 分组反向注意力模块细节
由于Jittor开发的自定义(元算子融合和统一计算图)代码比PyTorch更精简,效率更高,我们从表中可以看到,在RTX TITAN显卡上,Jittor框架相对于PyTorch框架平均有1.37倍左右的加速(见表1)。特别地,在Batch Size为4时,能达到1.52倍的推理加速,并且计算精度与PyTorch一致。
附 图1中所对应的正确答案

图7 图1中小鸟藏在哪里?
Deng-Ping Fan, Ge-Peng Ji, Ming-Ming Cheng, Ling Shao, Concealed Object Detection, IEEE TPAMI, 2021.
Innes C. Cuthill, Martin Stevens, Jenna Sheppard, Tracey Maddocks, C. Alejandro Pa´rraga and Tom S. Troscianko, Disruptive coloration and background pattern matching. Nature, Vol. 434, 2005.
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, Piotr Dollar, Panoptic segmentation, CVPR, 2019, 9404-9413.
Li Liu, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu and Matti Pietikäinen, Deeplearning for generic object detection: A survey, IJCV, Vol. 128, 261-318, 2019.
Deng-Ping Fan, Jing Zhang, Gang Xu, Ming-Ming Cheng, Ling Shao, Salient objects in clutter. arXiv, 2105.03053, 2021.
Mark Everingham, Luc Van Gool, Christopher K. I. Williams, John Winn & Andrew Zisserman, Thepascal visual object classes (voc) challenge. IJCV, Vol. 88, 303-338, 2010.
Jia Deng; Wei Dong; Richard Socher; Li-Jia Li; Kai Li; Li Fei-Fei, ImageNet: A large-scale hierarchical image database, CVPR, 248-255, 2009.
GGC往期回顾
您可通过下方二维码,关注清华大学图形学实验室,了解图形学、Jittor框架、CVMJ期刊和CVM会议的相关资讯。
