Global Contrast based Salient Region Detection
Ming-Ming Cheng1 Guo-Xin Zhang1 Niloy J. Mitra2 Xiaolei Huang3 Shi-Min Hu1
1TNList, Tsinghua University, Beijing 2KAUST/IIT Delhi 3Lehigh University

Figure. Given input images (top), a global contrast analysis is used to compute high resolution saliency maps (middle), which can be used to produce masks (bottom) around regions of interest.
Abstract
Reliable estimation of visual saliency allows appropriate processing of images without prior knowledge of their content, and thus remains an important step in many computer vision tasks including image segmentation, object recognition, and adaptive compression. We propose a regional contrast based saliency extraction algorithm, which simultaneously evaluates global contrast differences and spatial coherence. The proposed algorithm is simple, efficient, and yields full resolution saliency maps. Our algorithm consistently outperformed existing saliency detection methods, yielding higher precision and better recall rates, when evaluated using one of the largest publicly available data sets. We also demonstrate how the extracted saliency map can be used to create high quality segmentation masks for subsequent image processing.
Paper
Ming-Ming Cheng, Guo-Xin Zhang, Niloy J. Mitra, Xiaolei Huang, Shi-Min Hu. Global Contrast based Salient Region Detection. IEEE CVPR, p. 409-416, Colorado Springs, Colorado, USA, June 21-23, 2011. [Project page] [Bib] [Pdf 5MB] [Pdf 15M] [Pdf 中文版] [C++] [Poster] [FAQs] [Journal Version]
Comparisons with state of the art methods
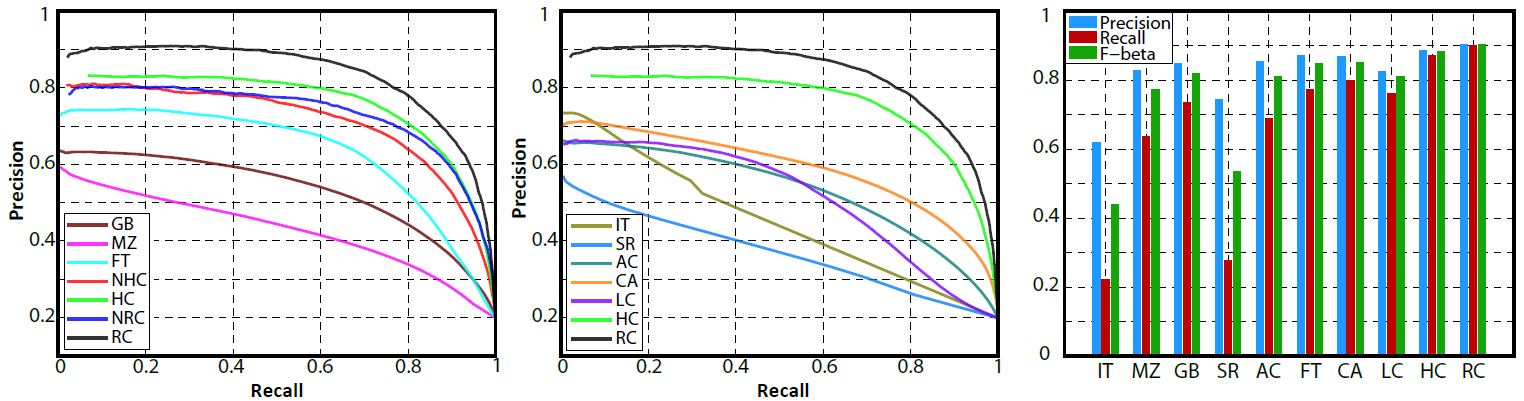
Figure. Precision-recall curve for naive thresholding of saliency maps using 1000 publicly available benchmark images. (Left, middle) Different options of our method compared to GB[13], MZ[21], FT[2], IT[16], SR[14], AC[1], CA[10], and LC[28]. NHC denotes naive version of our HC method with color space smoothing disabled, and NRC denotes our RC method with spatial related weighting disabled. (Right) Precision-recall bars for our saliency cut algorithm using different saliency maps as initialization. Our method RC shows high precision, recall, and F values over the 1000 image database.
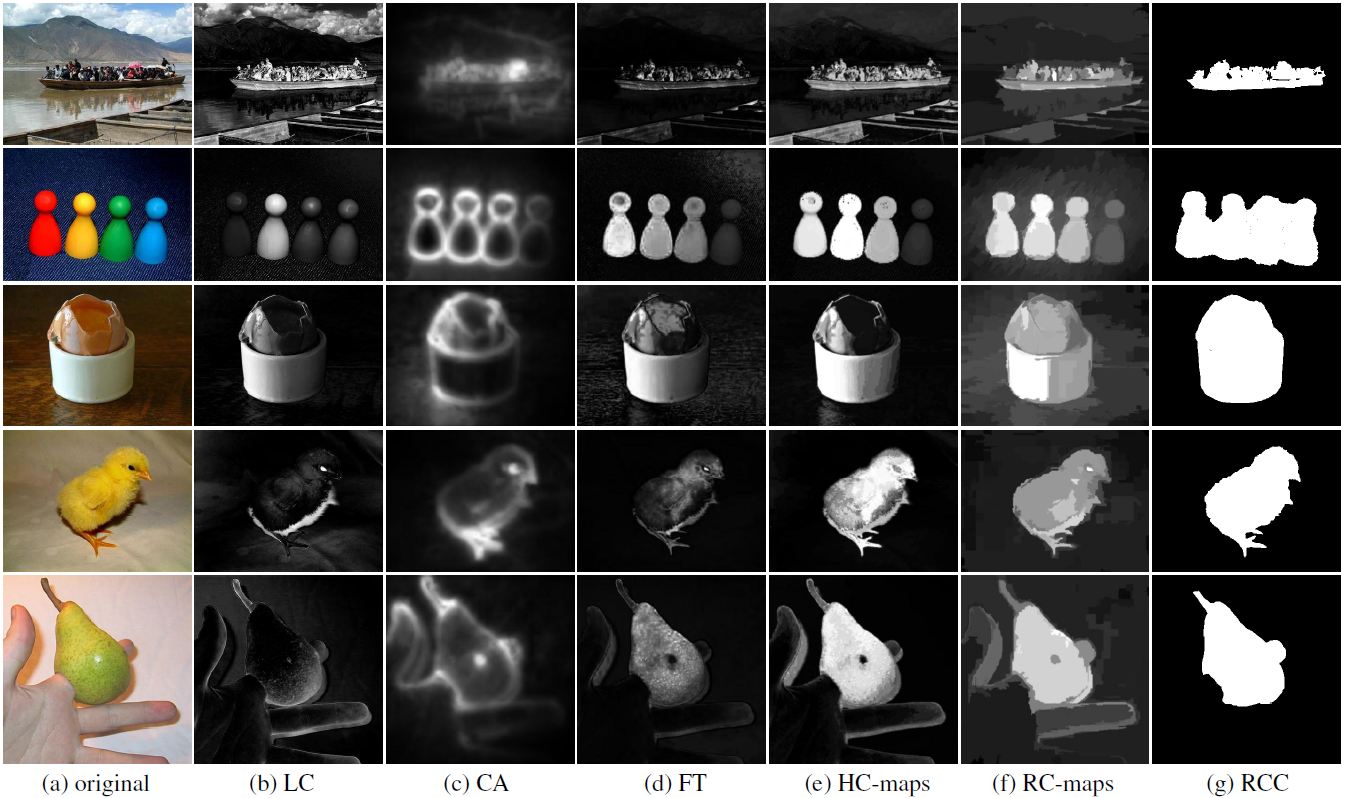
Figure. Visual comparison of saliency maps. (a) original images, saliency maps produced using (b) Zhai and Shah [28], (c) Goferman et al. [10], (d) Achanta et al. [2], (e) our HC and (f) RC methods, and (g) RC-based saliency cut results. Our methods generate uniformly highlighted salient regions.
Downloads
1. Data
Saliency detection results for our methods as well as other 8 state of the art methods, including GB[13], MZ[21], FT[2], IT[16], SR[14], AC[1], CA[10], and LC[28]. We use the ground truth data of Achanta et al. for comparisons. The ground truth annotations for 1000 images can be found in their project page.
2. Windows executable
We supply an windows msi for install our prototype software, which includes our implementation for FT[2], SR[14], LC[28], our HC, RC and saliency cut method. More powerful version (requires tbb).
3. C++ source code
The C++ implementation of our paper as well as several other state of the art works.
4. Supplemental material
Supplemental materials including comparisons with other 8 state of the art algorithms are now available.
FAQs
Until now, more than 1000+ readers (according to email records) have request to get the source code for this project. Some of them have questions about using the code. Here are some frequently asked questions for new users to refer:
Q: I’m confused with the sentence in the paper: “In our experiments, the threshold is chosen empirically to be the threshold that gives 95% recall rate in our fixed thresholding experiments”. But all most the case, people have not the ground truth, so cannot compute the call rate. When I use your Cut application, I need to guess threshold value to have good cut image.
A: The recall rate is just used to evaluate the algorithm. When you use it, you typically don't have to evaluate the algorithm itself very often. This sentence is used to explain what the fixed threshold we use typically means. Actually, when initialized using RC saliency maps, this threshold is 70 with saliency values normalized to [0,255]. It doesn’t mean that the saliency values corresponds to recall rate of 95% for every image, but empirically corresponds to recall rate of 95% for a large number of images. So, just use the suggested threshold of 70 is OK.
Q: I use you code to get results for the same database you used. But the results seem to have some difference from yours.
A: It seems that the cvtColor function in OpenCV 1.x is different from those in OpenCv 2.X. I suggest users to use those in recent versions. The segmentation method I used sometimes generates strange results, leading to strange results of saliency maps. This happens at low frequency. When this happens, I rerun the exe again and it becomes OK. I don't know why, but this really happens when I use the exe first time after compiling (Very strange, maybe because some default initializations). If someone find the bug, please report to me.
Q: Does your algorithm only get good results for images with single salient object?
A: Mostly yes. As described in our paper, our method is suitable for images with an unambiguous saliency object. Since saliency detection methods typically have no prior knowledge about the target object, thus is very difficult. Much recent researches focus on images with single saliency object. Even for this simple case, state of the art algorithm may also fail. It's understandable since supervised object detection which uses a large number of training data and prior knowledge also fails in many cases.
However, the value of saliency detection methods lies on their applications in many fields. Because they don't need large human annotation for learning, and typically much faster than object detection methods, it’s possible to automatically process a large number of images with low cost. Although many of the saliency detection results may be wrong (up to 60% for noise internet image) because of the ambiguous or even missing of salient objects, we can still use efficient algorithms to select those good results and use them in many interesting applications like:
- Image retrieval: Sketch2Photo: Internet Image Montage. Tao Chen, Ming-Ming Cheng, Ping Tan, Ariel Shamir, Shi-Min Hu. ACM Trans. Graph. 28, 5, 124:1-10, 2009.
- Image editing: Semantic Colorization with Internet Images, Yong Sang Chia, Shaojie Zhuo, Raj Kumar Gupta, Yu-Wing Tai, Siu-Yeung Cho, Ping Tan, Stephen Lin, ACM Transactions on Grapihcs (SIGGRAPH Asia) 2011.
- View selection: Web-Image Driven Best Views of 3D Shapes. The Visual Computer, 2011. Accepted. H Liu, L Zhang, H Huang
- Image Collage: Arcimboldo-like Collage Using Internet Images. ACM Transactions on Graphics, 30(6), 2011. H Huang, L Zhang, HC Zhang
- Image manipulation: Data-Driven Object Manipulation in Images. Chen Goldberg, Eurographics 2012, T Chen, FL Zhang, A Shamir, SM Hu.
- ...
Please report to me if you know more about such applications.
Links to source code of other methods
| FT | [1] R. Achanta, S. Hemami, F. Estrada, and S. Susstrunk,“Frequency-tuned salient region detection,” in IEEE CVPR, 2009, pp. 1597–1604. |
| AIM | [2] N. Bruce and J. Tsotsos, “Saliency, attention, and visual search: An information theoretic approach,” Journal of Vision, vol. 9, no. 3, pp. 5:1–24, 2009. |
| MSS | [3] R. Achanta and S. S ¨ usstrunk, “Saliency detection using maximum symmetric surround,” in IEEE ICIP, 2010, pp. 2653–2656. |
| SEG | [4] E. Rahtu, J. Kannala, M. Salo, and J. Heikkila, “Segmenting salient objects from images and videos,” ECCV, pp. 366–379, 2010. |
| SeR | [5] H. Seo and P. Milanfar, “Static and space-time visual saliency detection by self-resemblance,” Journal of vision, vol. 9, no. 12, pp. 15:1–27, 2009. |
| SUN | [6] L. Zhang, M. Tong, T. Marks, H. Shan, and G. Cottrell, “SUN: A bayesian framework for saliency using natural statistics,” Journal of Vision, vol. 8, no. 7, pp. 32:1–20, 2008. |
| SWD | [7] L. Duan, C. Wu, J. Miao, L. Qing, and Y. Fu, “Visual saliency detection by spatially weighted dissimilarity,” in IEEE CVPR, 2011, pp. 473–480. |
| IM | [8] N. Murray, M. Vanrell, X. Otazu, and C. A. Parraga, “Saliency estimation using a non-parametric low-level vision model,” in IEEE CVPR, 2011, pp. 433–440. |
| IT | [9] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE TPAMI, vol. 20, no. 11, pp. 1254–1259, 1998. |
| GB | [10] J. Harel, C. Koch, and P. Perona, “Graph-based visual saliency,” in NIPS, 2007, pp. 545–552. |
| SR | [11] X. Hou and L. Zhang, “Saliency detection: A spectral residual approach,” in IEEE CVPR, 2007, pp. 1–8. |
| CA | [12] S. Goferman, L. Zelnik-Manor, and A. Tal, “Context-aware saliency detection,” in IEEE CVPR, 2010, pp. 2376–2383. |
| LC | [13] Y. Zhai and M. Shah, “Visual attention detection in video sequences using spatiotemporal cues,” in ACM Multimedia, 2006, pp. 815–824. |
| AC | [14] R. Achanta, F. Estrada, P. Wils, and S. S ¨ usstrunk, “Salient region detection and segmentation,” in IEEE ICVS, 2008, pp. 66–75. |
| CB | [15] H. Jiang, J. Wang, Z. Yuan, T. Liu, N. Zheng, and S. Li,“Automatic salient object segmentation based on context and shape prior,” in British Machine Vision Conference, 2011, pp. 1–12. |