jittor.mpi
计图分布式基于MPI(Message Passing Interface),本文档主要阐述使用计图MPI,进行多卡和分布式训练的教程。
计图MPI安装
计图依赖OpenMPI,用户可以使用如下命令安装OpenMPI:
sudo apt install openmpi-bin openmpi-common libopenmpi-dev
也可以参考 OpenMPI 文档,自行编译安装。
计图会自动检测环境变量中是否包含mpicc,如果计图成功的检测到了mpicc,那么会输出如下信息:
[i 0502 14:09:55.758481 24 __init__.py:203] Found mpicc(1.10.2) at /usr/bin/mpicc
如果计图没有在环境变量中找到mpi,用户也可以手动指定mpicc的路径告诉计图,添加环境变量即可:export mpicc_path=/you/mpicc/path
OpenMPI安装完成以后,用户无需修改代码,需要做的仅仅是修改启动命令行,计图就会用数据并行的方式自动完成并行操作。
# 单卡训练代码
python3.7 -m jittor.test.test_resnet
# 分布式多卡训练代码
mpirun -np 4 python3.7 -m jittor.test.test_resnet
# 指定特定显卡的多卡训练代码
CUDA_VISIBLE_DEVICES="2,3" mpirun -np 2 python3.7 -m jittor.test.test_resnet
这种便捷性的背后是计图的分布式算子的支撑,计图支持的mpi算子后端会使用nccl进行进一步的加速。计图所有分布式算法的开发均在Python前端完成,这让分布式算法的灵活度增强,开发分布式算法的难度也大大降低。
如何从单卡代码适配多卡代码
使用mpirun时,以下几种模块会自动检测mpi环境并且自动切换成多卡版本:
jittor.optimizer: 自动同步梯度
jittor.nn.BatchNorm*: 同步batch norm
jittor.dataset: 自动数据并行
用户在使用MPI进行分布式训练时,计图内部的Dataset类会自动并行分发数据,需要注意的是Dataset类中设置的Batch size是所有节点的batch size之和,也就是总batch size, 不是单个节点接收到的batch size。
大部分情况下,单卡训练的代码可以直接使用mpirun实现分布式多卡运行。 但仍然如下几种情况下,需要对代码进行调整:
对硬盘进行写操作(保存模型,保存曲线)
需要统计全局信息(validation 上的全局准确率)
对硬盘进行写操作
对于第一点,假设原来您的代码如下:
for i, (images, labels) in enumerate(dataset):
output = model(images)
loss = nn.cross_entropy_loss(output, labels)
acc1 = accuracy(output, labels)
SGD.step(loss)
loss_data = loss.data
writer.add_scalar("Train/loss")
更改后的代码如下:
for i, (images, labels) in enumerate(dataset):
output = model(images)
loss = nn.cross_entropy_loss(output, labels)
acc1 = accuracy(output, labels)
SGD.step(loss)
loss_data = loss.data
if jt.rank == 0:
writer.add_scalar("Train/loss")
这里我们使用了 jt.rank 来限制,只允许第一个进程可以写 loss,这个代码在单卡下也是有效的,因为单卡的 jt.rank 值为 0, 需要注意的是,在 if jt.rank == 0 代码块里面的代码,不允许调用任何jittor的api,因为这很有可能导致多卡之间的api调用不一致而产生死锁!
需要统计全局信息
统计全局信息有两种方法,第一种是使用提供的 mpi op 来实现全局信息统计, 如下所示, 是一个validation的代码:
def val(epoch):
global min_error
model.eval()
correct_nums = 0
for i, (images, labels) in enumerate(valdataset):
output = model(images)
correct_nums += top1error(output, labels)
correct_nums.sync()
top1_error = (valdataset.total_len - correct_nums.data[0]) / valdataset.total_len
if top1_error < min_error:
print("[*] Best model is updated ...")
model.save('model_best.pkl')
更改方案如下:
def val(epoch):
global min_error
model.eval()
correct_nums = 0
for i, (images, labels) in enumerate(valdataset):
output = model(images)
correct_nums += top1error(output, labels)
correct_nums.sync()
if jt.in_mpi:
correct_nums = correct_nums.mpi_all_reduce()
top1_error = (valdataset.total_len - correct_nums.data[0]) / valdataset.total_len
if jt.rank == 0 and top1_error < min_error:
print("[*] Best model is updated ...")
model.save('model_best.pkl')
可以留意到我们首先使用了 mpi_all_reduce, 来统计多卡的正确数量(mpi_all_reduce会将多个mpi进程的结果累加起来), 然后在 jt.rank == 0 的情况下才更新模型。
第二种方法是使用@jt.single_process_scope(),被装饰的代码会直接以单进程的方式执行,无需处理多卡。
@jt.single_process_scope()
def val(epoch):
......
MPI接口
下面是 jittor 的 mpi api reference. 目前MPI开放接口如下:
jt.in_mpi: 当计图不在MPI环境下时,jt.mpi == False, 用户可以用这个判断是否在mpi环境下。jt.world_size: 获取当前进程总数量,如果没有用mpi,则为1。jt.rank: 获取当前进程的编号,区间为0 ~ jt.world_size-1, 如果没有用mpi,则为0。jt.mpi: 计图的MPI模块。jt.Module.mpi_param_broadcast(root=0): 将模块的参数从root节点广播给其他节点。jt.mpi.mpi_reduce(x, op='add', root=0): 将所有节点的变量x使用算子op,reduce到root节点。如果op是’add’或者’sum’,该接口会把所有变量求和,如果op是’mean’,该接口会取均值。
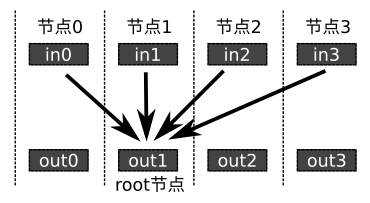
jt.mpi.mpi_broadcast(x, root=0): 将变量x从root节点广播到所有节点。

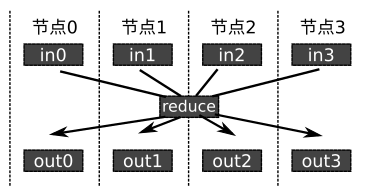
jt.mpi.mpi_all_reduce(x, op='add'): 将所有节点的变量x使用一起reduce,并且吧reduce的结果再次广播到所有节点。如果op是’add’或者’sum’,该接口会把所有变量求和,如果op是’mean’,该接口会取均值。
实例:MPI实现分布式同步批归一化层
下面的代码是使用计图实现分布式同步批归一化层的实例代码,在原来批归一化层的基础上,只需增加三行代码,就可以实现分布式的batch norm,添加的代码如下:
# 将均值和方差,通过all reduce同步到所有节点
if self.sync and jt.mpi:
xmean = xmean.mpi_all_reduce("mean")
x2mean = x2mean.mpi_all_reduce("mean")
注:计图内部已经实现了同步的批归一化层,用户不需要自己实现
分布式同步批归一化层的完整代码:
class BatchNorm(Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=None, is_train=True, sync=True):
assert affine == None
self.sync = sync
self.num_features = num_features
self.is_train = is_train
self.eps = eps
self.momentum = momentum
self.weight = init.constant((num_features,), "float32", 1.0)
self.bias = init.constant((num_features,), "float32", 0.0)
self.running_mean = init.constant((num_features,), "float32", 0.0).stop_grad()
self.running_var = init.constant((num_features,), "float32", 1.0).stop_grad()
def execute(self, x):
if self.is_train:
xmean = jt.mean(x, dims=[0,2,3], keepdims=1)
x2mean = jt.mean(x*x, dims=[0,2,3], keepdims=1)
# 将均值和方差,通过all reduce同步到所有节点
if self.sync and jt.mpi:
xmean = xmean.mpi_all_reduce("mean")
x2mean = x2mean.mpi_all_reduce("mean")
xvar = x2mean-xmean*xmean
norm_x = (x-xmean)/jt.sqrt(xvar+self.eps)
self.running_mean += (xmean.sum([0,2,3])-self.running_mean)*self.momentum
self.running_var += (xvar.sum([0,2,3])-self.running_var)*self.momentum
else:
running_mean = self.running_mean.broadcast(x, [0,2,3])
running_var = self.running_var.broadcast(x, [0,2,3])
norm_x = (x-running_mean)/jt.sqrt(running_var+self.eps)
w = self.weight.broadcast(x, [0,2,3])
b = self.bias.broadcast(x, [0,2,3])
return norm_x * w + b