|
|
Publications
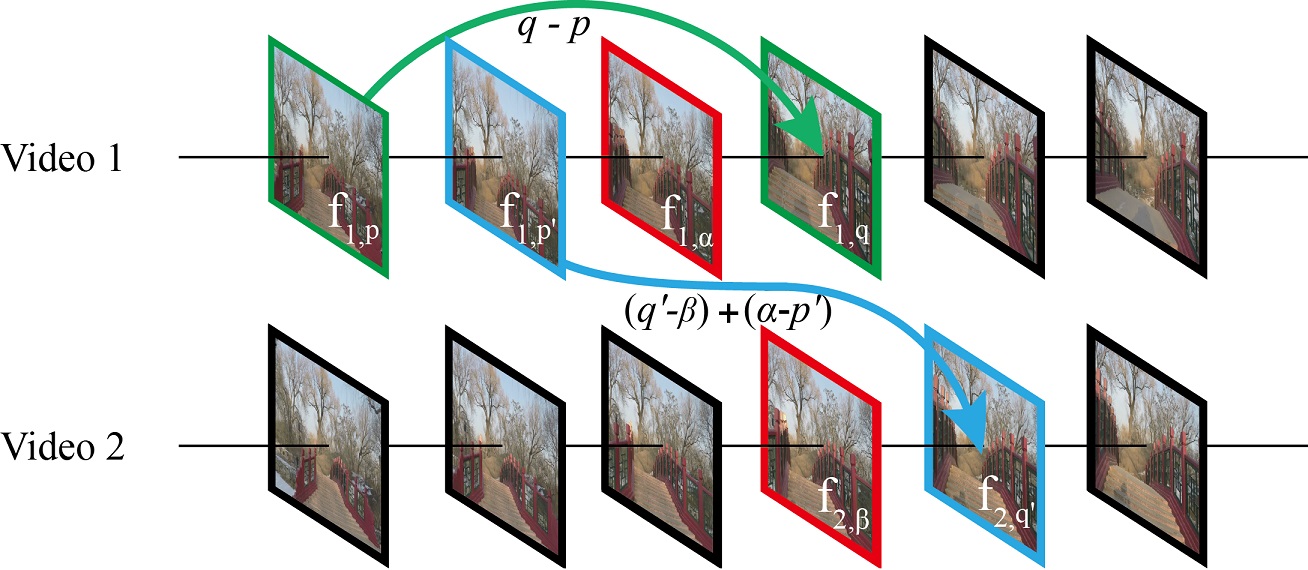 |
Hyper-lapse from Multiple Spatially-overlapping Videos
Miao Wang, Jun-Bang Liang, Song-Hai Zhang, Shao-Ping Lu, Ariel Shamir, and Shi-Min Hu
IEEE Transactions on Image Processing. 2017.
Hyper-lapse video with high speed-up rate is an efficient way to overview long videos such as a human activity in first-person view. Existing hyper-lapse video creation methods produce a fast-forward video effect using only one video source. In this work, we present a novel hyper-lapse video creation approach based on multiple spatially-overlapping videos. We assume the videos share a common view or location, and find transition points where jumps from one video to another may occur. We represent the collection of videos using a hyper-lapse transition graph; the edges between nodes represent possible hyper-lapse frame transitions. To create a hyper-lapse video, a shortest path search is performed on this digraph to optimize frame sampling and assembly simultaneously. Finally, we render the hyper-lapse results using video stabilization and appearance smoothing techniques on the selected frames. Our technique can synthesize novel virtual hyper-lapse routes which may not exist originally. We show various application results on both indoor and outdoor video collections with static scenes, moving objects, and crowds.
[paper] [bibtex]
|

|
Efficient Depth-aware Image Deformation Adaptation for Curved Screen Displays
Shao-Ping Lu, Ruxandra-marina Florea, Pablo Cesar, Peter
Schelkens, and Adrian Munteanu
ACM Conference on Multimedia (ACM MM) Thematic Workshop, 2017.
The curved screen has attracted considerable attentions in recent years, since it enables to enlarge the view angle and to enhance the immersive perception for users. However, existing curved surface projections are frequently prone to geometric distortion or loss of content. This paper presents a content-aware and depth-aware image adaptation solution for curved displays. An efficient optimization approach of image deformation is proposed to preserve local scene content and to minimize scene geometry distortion. To follow the original 3D perception of objects in different depth layers, the depth information is re-mapped for individual content scaling. Objective evaluation results reveal that our approach can effectively preserve foreground objects. We also perform a subjective evaluation of the proposed solution, and compare it to two alternative mapping methods, which are tested on different curvatures on both a traditional screen and an ad-hoc curvature-controllable curved display. Experimental results demonstrate that our approach outperforms other existing mapping methods for immersive display of rectangle images on curved screens.
[paper] [video(96MB)] [bibtex]
|

|
Color Correction for Large-baseline Multiview Video
Siqi Ye, Shao-Ping Lu, and Adrian Munteanu
Signal Processing: Image Communication. 53: 40-50, 2017.
Color misalignment correction is an important, yet unsolved problem, especially for multiview video captured by large disparity camera setups. In this paper, we introduce a robust large-baseline color correction method that preserves the original manifold structure of the input video. The manifold structure is extracted by locally linear embedding (LLE), aimed at linearly representing each pixel based on its neighbors, assuming that they are all clustered in a high-dimensional feature space. Besides the proposed manifold structure preservation constraint, the proposed method enforces spatio-temporal color consistencies and gradient preservation. The multiview color correction solution is obtained by solving a global optimization problem. Thorough objective and subjective experimental results demonstrate that our proposed approach significantly and systematically outperforms the state-of-the-art color correction methods on large-baseline multiview video data.
[paper] [bibtex]
|
|
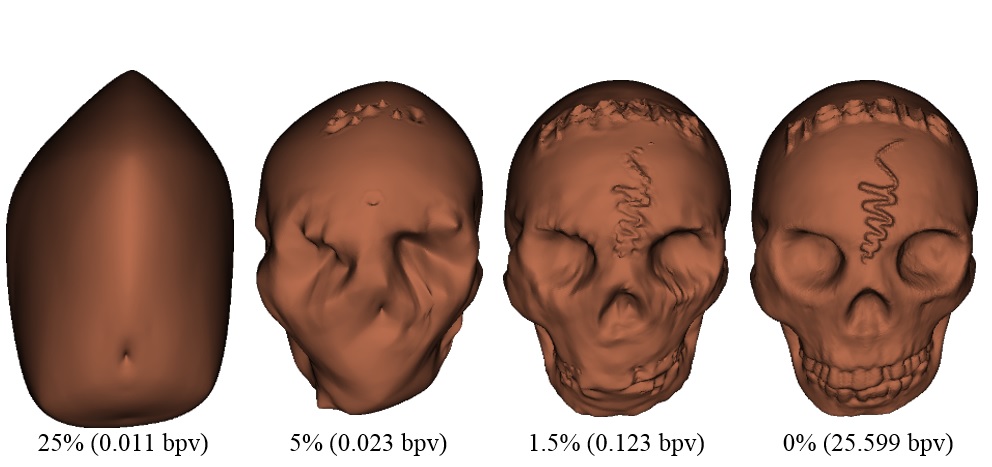
Wavelet-based L∞ Semi-regular Mesh Coding
Ruxandra-marina Florea, Adrian Munteanu, Shao-Ping Lu, and Peter
Schelkens
IEEE Transactions on Multimedia. 19(2): 236-250, 2017.
Polygonal meshes are popular 3D virtual representations employed in a wide range of applications. Users have very high expectations with respect to the accuracy of these virtual representations, fueling a steady increase in the processing power and performance of graphics processing hardware. This accuracy is closely related to how detailed the virtual representations are. The more detailed these representations become, the higher the amount of data that will need to be displayed, stored or transmitted. Efficient compression techniques are of critical importance in this context. State-of the art compression performance of semi-regular mesh coding systems has been achieved through the use of subdivision-based wavelet coding techniques. However, the vast majority of these codecs are optimized with respect to the distortion metric, i.e. the average error. This makes them unsuitable for applications where each input signal sample has a certain significance. To alleviate this problem, we propose to optimize the mesh codec with respect to the metric, which allows for the control of the local reconstruction error. This paper proposes novel data-dependent formulations for the distortion. The proposed estimators are incorporated in a state-of-the-art wavelet-based semi-regular mesh codec. The resulting coding system offers scalability in sense. The experiments demonstrate the advantages of coding in providing a tight control on the local reconstruction error. Furthermore, the proposed data-dependent approaches significantly improve estimation accuracy, reducing the classical low-rate gap between the estimated and actual distortion observed for previous estimators.
[paper] [bibtex]
|
|
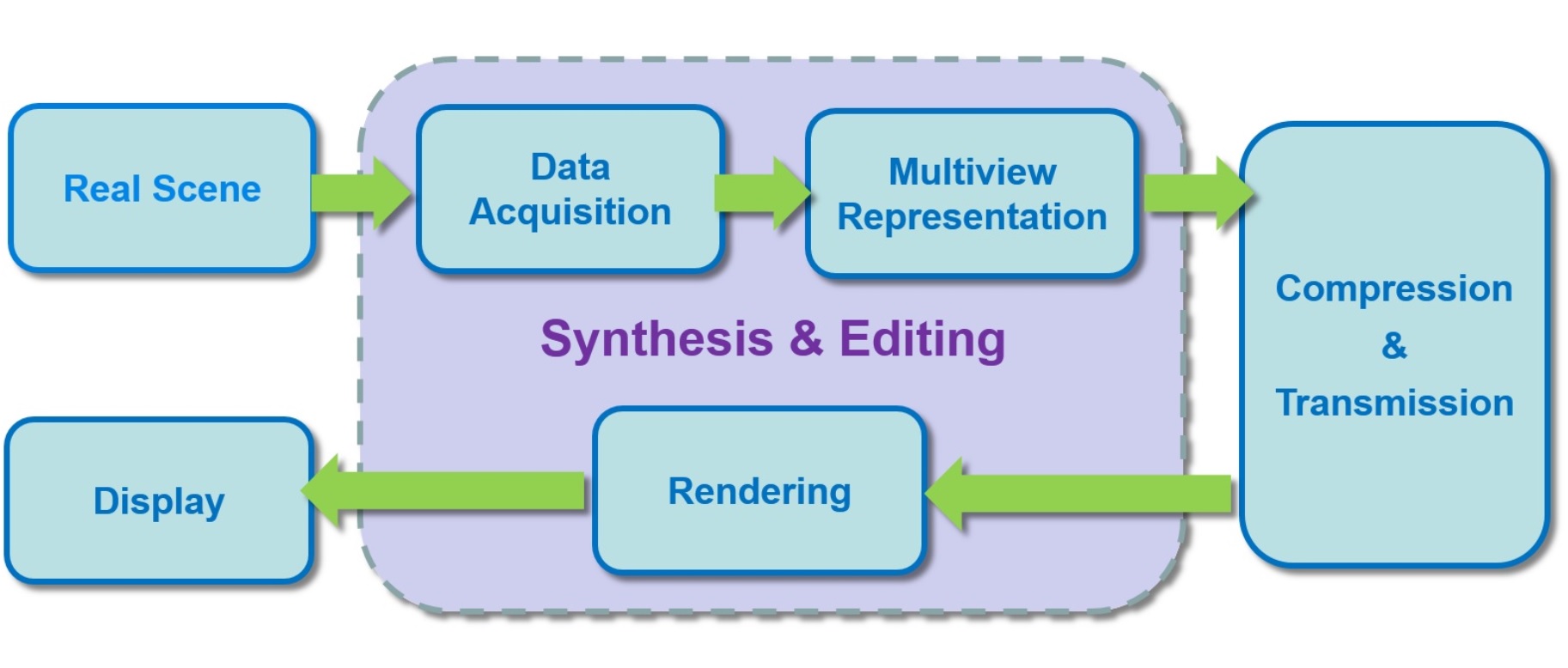
A Survey on Multiview Video Synthesis and Editing
Shao-ping Lu, Tai-Jiang Mu, and Song-Hai Zhang
Tsinghua Science and Technology. 21(6): 678-695, 2016.
Multiview video can provide more immersive perception than traditional single 2-D video. It enables both interactive free navigation applications as well as high-end autostereoscopic displays on which multiple users can perceive genuine 3-D content without glasses. The multiview format also comprises much more visual information than classical 2-D or stereo 3-D content, which makes it possible to perform various interesting editing operations both on pixel-level and object-level. This survey provides a comprehensive review of existing multiview video synthesis and editing algorithms and applications. For each topic, the related technologies in classical 2-D image and video processing are reviewed. We then continue to the discussion of recent advanced techniques for multiview video virtual view synthesis and various interactive editing applications. Due to the ongoing progress on multiview video synthesis and editing, we can foresee more and more immersive 3-D video applications will appear in the future.
[paper] [bibtex]
|

|
Efficient MRF-based Disocclusion Inpainting in Multiview Video
Beerend Ceulemans, Shao-Ping Lu, Gauthier Lafruit, Peter
Schelkens, and Adrian Munteanu
International Conference on Multimedia and Expo (ICME). IEEE, 2016.
View synthesis using depth image-based rendering generates virtual viewpoints of a 3D scene based on texture and depth information from a set of available cameras. One of the core components in view synthesis is image inpainting which performs the reconstruction of areas that were occluded in the available cameras but are visible from the virtual viewpoint. Inpainting methods based on Markov random fields (MRFs) have been shown to be very effective in inpainting large areas in images. In this paper, we propose a novel MRF-based inpainting method for multiview video. The proposed method steers the MRF optimization towards completion from background to foreground and exploits the available depth information in order to avoid bleeding artifacts. The proposed approach allows for efficiently filling-in large disocclusion areas and greatly accelerates execution compared to traditional MRF-based inpainting techniques. The experimental results show that view synthesis based on the proposed inpainting method systematically improves performance over the state-of-the-art in multiview view synthesis. Average PSNR gains up to 1.88 dB compared to the MPEG View Synthesis Reference software were observed.
[paper] [bibtex]
|
|
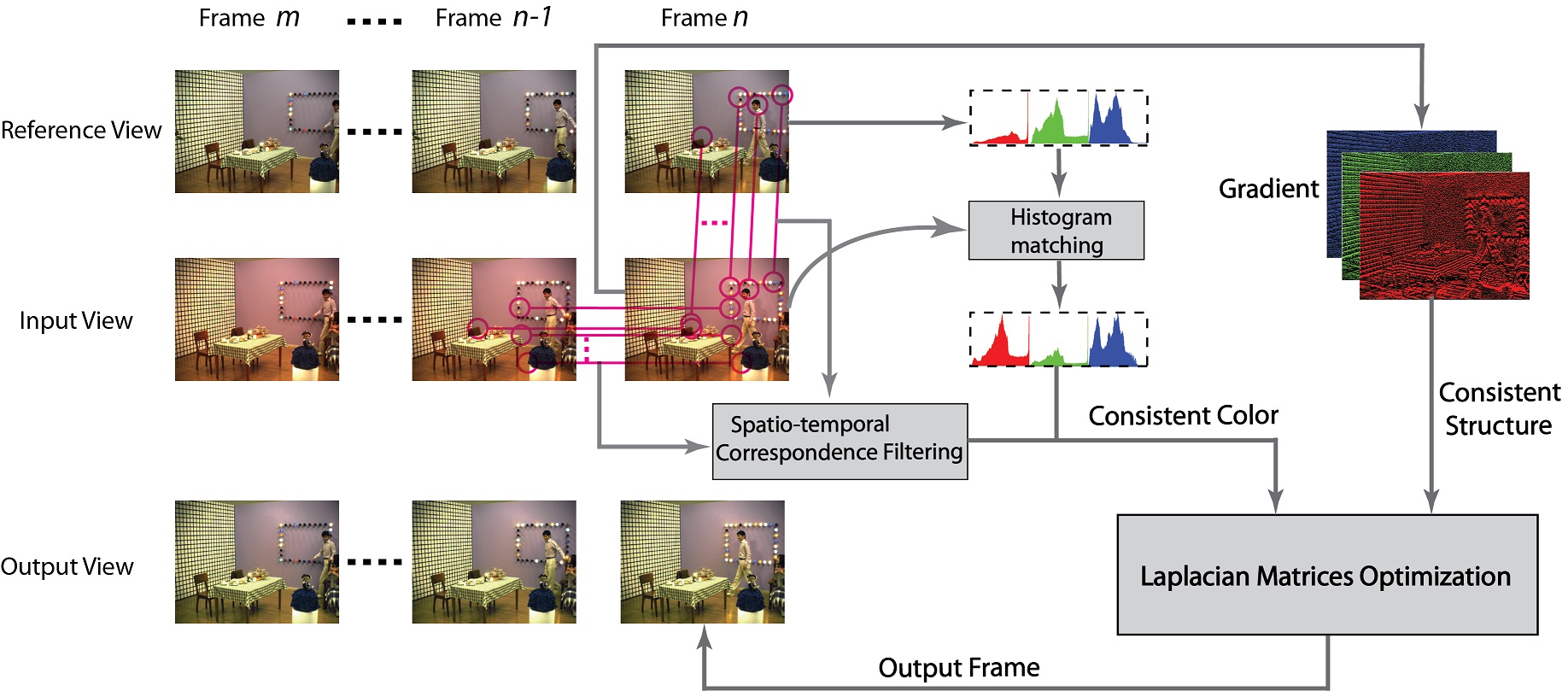
Spatio-temporally Consistent Color and Structure Optimization for Multiview Video Color Correction
Shao-ping Lu, Beerend Ceulemans, Adrian Munteanu and Peter
Schelkens
IEEE Transactions on Multimedia. 17(5): 577-590, 2015.
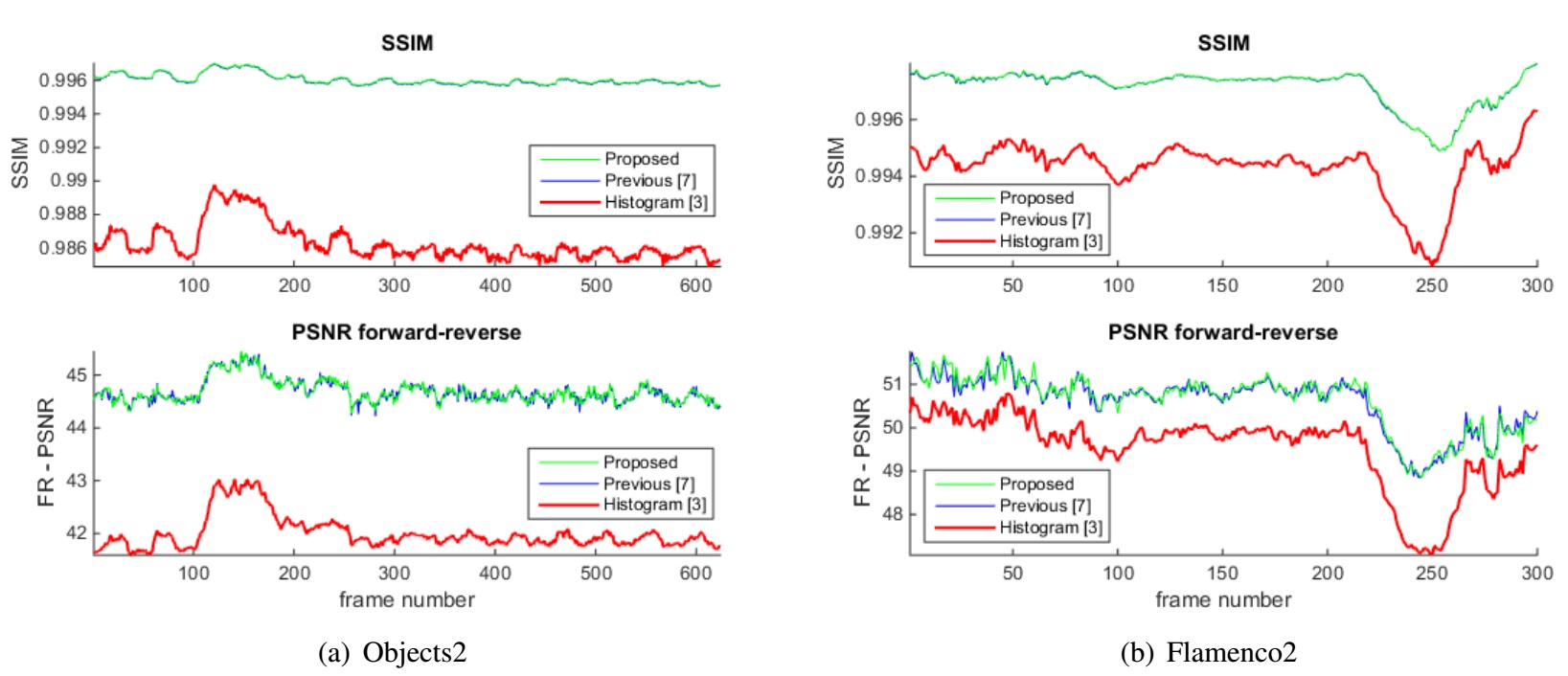
When compared to conventional 2D video, multiview video can significantly enhance the visual 3D experience in 3D applications by offering horizontal parallax. However, when processing images originating from different views, it is common that the colors between the different cameras are not well calibrated. To solve this problem, a novel energy function-based color correction method for multiview camera setups is proposed to enforce that colors are as close as possible to those in the reference image but also that the overall structural information is well preserved. The proposed system introduces a spatiotemporal correspondence matching method to ensure that each pixel in the input image gets bijectively mapped to a reference pixel. By combining this mapping with the original structural information, we construct a global optimization algorithm in a Laplacian matrix formulation and solve it using a sparse matrix solver. We further introduce a novel forward-reverse objective evaluation model to overcome the problem of lack of ground truth in this field. The visual comparisons are shown to outperform state-of-the-art multiview color correction methods, while the objective evaluation reports PSNR gains of up to 1.34 dB and SSIM gains of up to 3.2% respectively.
[paper] [video(72MB)] [bibtex]
|

|
Color Retargeting: Interactive Time-varying Color Image Composition from Time-lapse Sequences
Shao-ping Lu, Guillaume Dauphin, Gauthier Lafruit, and Adrian Munteanu
Computational Visual Media Journal, 1(4), 321-330, 2015.
In this paper, we present an interactive static image composition approach, namely color retargeting, to flexibly represent time-varying color editing effect based on time-lapse video sequences. Instead of performing precise image matting or blending techniques, our approach treats the color composition as a pixel-level resampling problem. In order to both satisfy the user's editing requirements and avoid visual artifacts, we construct a globally optimized interpolation field. This field defines from which input video frames the output pixels should be resampled. Our proposed resampling solution ensures that (i) the global color transition in the output image is as smooth as possible, (ii) the desired colors/objects specified by the user from different video frames are well preserved, and (iii) additional local color transition directions in the image space assigned by the user are also satisfied. Various examples have been shown to demonstrate that our efficient solution enables the user to easily create time-varying color image composition results.
[paper] [video(70MB)] [bibtex]
|

|
Accuracy and Robustness Evaluation in Stereo Matching
Duc M Nguyen, Jan Hanca, Shao-Ping Lu, Peter
Schelkens, and Adrian Munteanu
Proc. SPIE Optical Engineering+ Applications. 99710M-99710M-12, 2016.
Robust Stereo Matching Using Census Cost, Discontinuity-preserving Disparity Computation and View-consistent Refinement
Duc M Nguyen, Jan Hanca, Shao-ping Lu, and Adrian Munteanu
International Conference on 3D Imaging (IC3D). IEEE, 2015.
Stereo matching has been one of the most active research topics in computer vision domain for many years resulting in a large number of techniques proposed in the literature. Nevertheless, improper combinations of available tools cannot fully utilize the advantages of each method and may even lower the performance of the stereo matching system. Moreover, state-of-the-art techniques are usually optimized to perform well on a certain input dataset. In this paper we propose a framework to combine existing tools into a stereo matching pipeline and three different architectures combining existing processing steps to build stereo matching systems which are not only accurate but also efficient and robust under different operating conditions. Thorough experiments on three well-known datasets confirm the effectiveness of our proposed systems on any input data.
[paper] [bibtex]
|
|
Globally Optimized Multiview Video Color Correction Using Dense Spatio-temporal Matching
Beerend Ceulemans, Shao-ping Lu, Peter
Schelkens, and Adrian Munteanu
International Conference on 3DTV. IEEE, 2015.
Multiview video is becoming increasingly popular as the format for 3D video systems that use autostereoscopic displays or free viewpoint navigation capabilities. However, the algorithms that drive these applications are not yet mature and can suffer from subtle irregularities such as color imbalances in between different cameras. Regarding the problem of color correction, state-of-the-art methods directly apply some form of histogram matching in blocks of pixels between an input frame and a target frame containing the desired color distribution. These methods, however, typically suffer from artifacts in the gradient domain, as they do not take into account local texture information. This paper presents a novel method to correct color differences in multiview video sequences that uses a dense matching-based global optimization framework. The proposed energy function ensures preservation of local structures by regulating deviations from the original image gradients.
[paper] [bibtex]
|
|
Performance
Optimization for PatchMatch-based Pixel-level Multiview Inpainting
Shao-ping Lu, Beerend Ceulemans, Adrian Munteanu and Peter
Schelkens
International Conference on 3D Imaging (IC3D). IEEE, 2013.
As 3D content is becoming ubiquitous in today's media landscape, there is a rising interest for 3D displays that do not demand wearing special headgear in order to experience the 3D effect. Autostereoscopic displays realize this by providing multiple different views of the same scene. It is however unfeasible to record, store or transmit the amount of data that such displays require. Therefore, there is a strong need for real-time solutions that can generate multiple extra viewpoints from a limited set of originally recorded views. The main difficulty in current solutions is that the synthesized views contain disocclusion holes where the pixel values are unknown. In order to seamlessly fill-in these holes, inpainting techniques are being used. In this work we consider a depth-based pixel-level inpainting system for multiview video. The employed technique operates in a multi-scale fashion, fills in the disocclusion holes on a pixel-per-pixel basis and computes approximate Nearest Neighbor Fields (NNF) to identify pixel correspondences. To this end, we employ a multi-scale variation on the well-known PatchMatch algorithm followed by a refinement step to escape from local minima in the matching-cost function. In this paper we analyze the performance of different cost functions and search methods within our existing inpainting framework.
[paper] [bibtex]
|

|
Depth-based
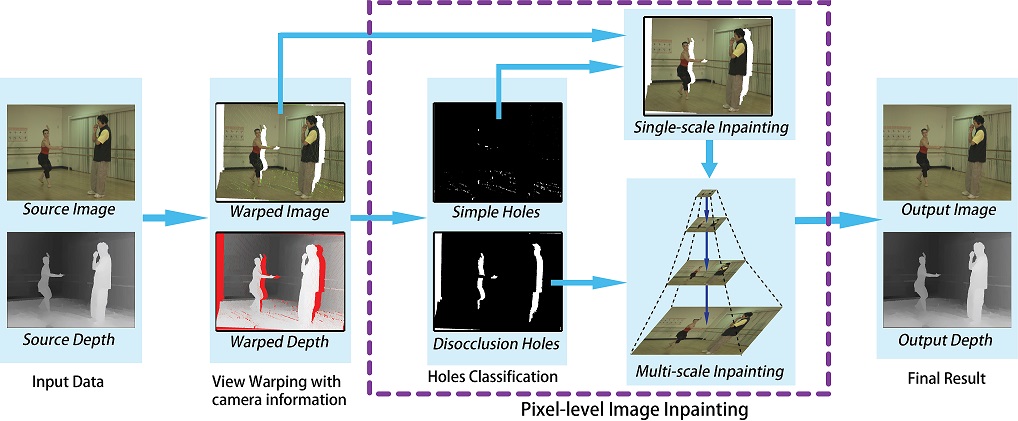
View Synthesis Using Pixel-level Image Inpainting
Shao-ping Lu, Jan Hanca, Adrian Munteanu and Peter
Schelkens
18th International Conference on Digital Signal
Processing (DSP), IEEE, 2013.
Depth-based view synthesis can produce novel realistic
images of a scene by view warping and image inpainting.
This paper presents a depth-based view synthesis approach performing
pixel-level image inpainting. The proposed
approach provides great flexibility in pixel
manipulation and prevents random effects in texture propagation. By
analyzing the process generating image holes in view warping, we firstly
classify such areas into simple holes and disocclusion areas. Based on depth information constraints and different strategies for
random propagation, an approximate nearest-neighbor match based pixel-level inpainting is introduced to complete holes from
the two classes. Experimental results demonstrate that the proposed view
synthesis method can effectively produce smooth textures and reasonable
structure propagation. The proposed depth-based pixel-level inpainting is well suitable to multi-view video and
other higher dimensional view synthesis settings.
[paper] [bibtex]
|
|

|
Time-Line
Editing of Objects in Video
Shao-Ping Lu, Song-Hai Zhang, Jin Wei, Shi-Min Hu and Ralph R. Martin
IEEE Transactions on Visualization and Computer
Graphics, 19(7), 1218-1227, 2013.
We present a video editing technique based on changing the time-lines of
individual objects in video, which leaves them in their original places but
puts them at different times. This allows the production of object level
slow motion effects, fast motion effects, or even time reversal. This is
more flexible than simply applying slow or fast motion to whole frames, as
new relationships between objects can be created. As we restrict object
interactions to the same spatial locations as in the original video, our
approach can produce high-quality results using only coarse matting of video
objects. Coarse matting can be done efficiently using video object
segmentation, avoiding tedious manual matting. To design the output, the
user interactively indicates the desired new life-spans of objects, and may
also change the overall running time of the video. Our method rearranges the
time-lines of objects in the video whilst applying appropriate object
interaction constraints. We demonstrate that although this editing technique
is somewhat restrictive, it still allows many interesting results.
[paper] [video
(96MB)] [bibtex]
|
|

|
Saliency-Based Fidelity
Adaptation Preprocessing for Video Coding
Shao-Ping Lu and Song-Hai Zhang
Journal of Computer Science and Technology. 26(1): 195-202, 2011
In this paper, we present a video coding scheme which applies the
technique of visual saliency computation to adjust image fidelity before
compression. To extract visually salient features, we construct a
spatio-temporal saliency map by analyzing the video using a combined
bottom-up and top-down visual saliency model. We then use an extended
bilateral filter, in which the local intensity and spatial scales are
adjusted according to visual saliency, to adaptively alter the image
fidelity. Our implementation is based on the H.264 video encoder JM12.0. Besides
evaluating our scheme with the H.264 reference software, we also compare it
to a more traditional foreground-background segmentation based method and a
foveation-based approach which employs Gaussian blurring. Our results show
that the proposed algorithm can improve the compression ratio significantly
while effectively preserving perceptual visual quality.
[paper] [bibtex]
|
Visual Importance based Painterly
Rendering for Images
Shao-Ping Lu and Song-Hai Zhang
Journal of Computer-Aided Design Computer Graphics. (in Chinese). 22(7): 1120-1125, 2010.
Blind Re-convolution based Image
Upsampling
Shao-Ping Lu
Proceedings of 6th Joint Conference on Harmonious Human Machine Environment.
(in Chinese). Luoyang, China, 2010.
Professional services:
- Review for journals:
IEEE Trans: TIP, TVCG, TMM, TCSVT, TBME
Others: IEEE STSP, SPIC, TVCJ, JCST, Science China (F), CVMJ, etc.
- Review for conferences:
SIGGRAPH ASIA, PG, CGI, ICIP, ICME, CVM, etc.
|
Links
|
Some
collaborators:
Shi-Min Hu, Ralph R. Martin, Ariel Shamir, Song-Hai Zhang, Miao Wang, Zhe Zhu, Adrian Munteanu,
Peter
Schelkens,
Gauthier Lafruit, Pablo Cesar, Ruxandra-marina Florea, Jan Hanca,
Duc M Nguyen, Siqi Ye
|
|
