
目标检测是计算机视觉的一项重要任务,本教程使用JITTOR框架参考[1]实现了SSD目标检测模型[2]。
SSD论文链接:https://arxiv.org/pdf/1512.02325.pdf
完整代码:https://github.com/Jittor/ssd-jittor
1. 数据集
1.1 数据准备
VOC数据集是目标检测、语义分割等任务常用的数据集之一,本教程使用VOC数据集的2007 trainval和2012 trainval作为训练集,2007 test作为验证集和测试集。您可以从下面的链接下载数据。
VOC数据集中的物体共包括20个类别:'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'

将三个文件解压在同一文件夹data下,并使用utils.py里的create_data_lists()函数生成训练所需的json文件。
函数的参数voc07_path和voc12_path分别是./data/VOCdevkit/VOC2007/和./data/VOCdevkit/VOC2012/,output_folder可自行设置,比如./dataset/,您将在output_folder中得到label_map.json、TEST_images.json、TEST_objects.json、TRAIN_images.json、TRAIN_objects.json五个文件。
最终数据集的文件组织如下。
# 文件组织
根目录
|----data
| |----VOCdevkit
| | |----VOC2007
| | | |----Annotations
| | | |----ImageSets
| | | |----JPEGImages
| | | |----SegmentationClass
| | | |----SegmentationObject
| | |----VOC2012
| | |----Annotations
| | |----ImageSets
| | |----JPEGImages
| | |----SegmentationClass
| | |----SegmentationObject
|----dataset
|----label_map.json
|----TEST_images.json
|----TEST_objects.json
|----TRAIN_images.json
|----TRAIN_objects.json
1.2 数据加载
使用jittor.dataset.dataset的基类Dataset可以构造自己的数据集,需要实现__init__、__getitem__、__len__以及collate_batch等函数。
__init__: 定义数据路径,这里的data_folder需设置为之前您设定的output_folder路径。同时需要调用self.set_attrs来指定数据集加载所需的参数batch_size,total_len、shuffle。__getitem__: 返回单个item的数据。__len__: 返回数据集的数据总数。collate_batch: 由于训练集中不同的图片的gt框个数不同,需要重写collate_batch函数将不同item的boxes和labels放入list,返回batch_size的数据。
from jittor.dataset.dataset import Dataset
import json
import os
import cv2
import numpy as np
from utils import random_crop, random_bright, random_swap, random_contrast, random_saturation, random_hue, random_flip, random_expand
import random
class PascalVOCDataset(Dataset):
def __init__(self, data_folder, split, keep_difficult=False, batch_size=1, shuffle=False):
self.split = split.upper()
assert self.split in {'TRAIN', 'TEST'}
self.data_folder = data_folder
self.keep_difficult = keep_difficult
self.batch_size = batch_size
self.shuffle = shuffle
self.mean = [0.485, 0.456, 0.406]
self.std = [0.229, 0.224, 0.225]
with open(os.path.join(data_folder, self.split + '_images.json'), 'r') as j:
self.images = json.load(j)
with open(os.path.join(data_folder, self.split + '_objects.json'), 'r') as j:
self.objects = json.load(j)
assert len(self.images) == len(self.objects)
self.total_len = len(self.images)
self.set_attrs(batch_size = self.batch_size, total_len = self.total_len, shuffle = self.shuffle)
def __getitem__(self, i):
image = cv2.imread(self.images[i])
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB).astype("float32")
objects = self.objects[i]
boxes = np.array(objects['boxes']).astype("float32")
labels = np.array(objects['labels'])
difficulties = np.array(objects['difficulties'])
if not self.keep_difficult:
boxes = boxes[1 - difficulties]
labels = labels[1 - difficulties]
difficulties = difficulties[1 - difficulties]
# 数据增强
if self.split == 'TRAIN':
data_enhance = [random_bright, random_swap, random_contrast, random_saturation, random_swap]
random.shuffle(data_enhance)
for d in data_enhance:
image = d(image)
image, boxes = random_expand(image, boxes, filler=self.mean)
image, boxes, labels, difficulties = random_crop(image, boxes, labels, difficulties)
image, boxes = random_flip(image, boxes)
height, width, _ = image.shape
image = cv2.resize(image, (300, 300))
image /= 255.
image = (image - self.mean) / self.std
image = image.transpose((2,0,1)).astype("float32")
boxes[:,[0,2]] /= width
boxes[:,[1,3]] /= height
return image, boxes, labels, difficulties
def __len__(self):
return len(self.images)
def collate_batch(self, batch):
images = list()
boxes = list()
labels = list()
difficulties = list()
for b in batch:
images.append(b[0])
boxes.append(b[1])
labels.append(b[2])
difficulties.append(b[3])
images = np.stack(images, axis=0)
return images, boxes, labels, difficulties
2. 模型定义
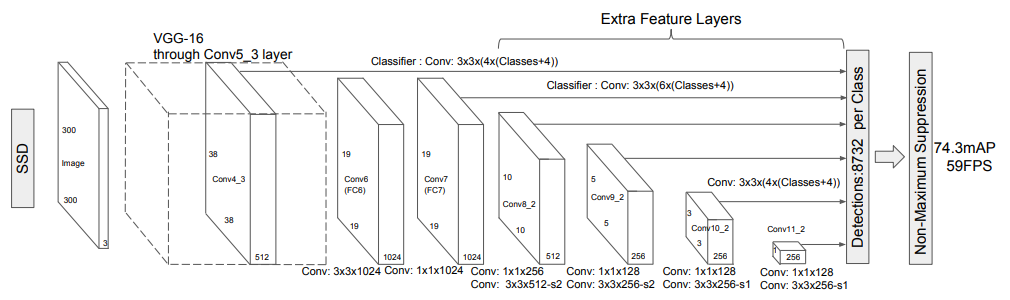
上图为SSD论文给出的网络架构图。
本教程采用VGG-16[3]为backbone。输入图像尺寸为300*300,采用VGG-16的中间层特征conv4_3、conv7以及Extra Feature Layers (AuxiliaryConvolutions)的中间特征层conv8_2、conv9_2、conv10_2和conv11_2。conv4_3、conv7、conv8_2、conv9_2、conv10_2和conv11_2的特征图大小分别是38*38、19*19、10*10、5*5、3*3、1*1,锚框Prior的scale分别为0.1、0.2、0.375、0.55、0.725、0.9,特征图上每个点产生的Prior数目分别为4、6、6、6、4、4,最终每个特征图产生的Prior数目为5776、2166、600、150、36、4。总计有8732个Prior。
class VGGBase(nn.Module):
def __init__(self):
super(VGGBase, self).__init__()
self.conv1_1 = nn.Conv(3, 64, kernel_size=3, padding=1)
self.conv1_2 = nn.Conv(64, 64, kernel_size=3, padding=1)
self.pool1 = nn.Pool(kernel_size=2, stride=2, op='maximum')
self.conv2_1 = nn.Conv(64, 128, kernel_size=3, padding=1)
self.conv2_2 = nn.Conv(128, 128, kernel_size=3, padding=1)
self.pool2 = nn.Pool(kernel_size=2, stride=2, op='maximum')
self.conv3_1 = nn.Conv(128, 256, kernel_size=3, padding=1)
self.conv3_2 = nn.Conv(256, 256, kernel_size=3, padding=1)
self.conv3_3 = nn.Conv(256, 256, kernel_size=3, padding=1)
self.pool3 = nn.Pool(kernel_size=2, stride=2, ceil_mode=True, op='maximum')
self.conv4_1 = nn.Conv(256, 512, kernel_size=3, padding=1)
self.conv4_2 = nn.Conv(512, 512, kernel_size=3, padding=1)
self.conv4_3 = nn.Conv(512, 512, kernel_size=3, padding=1)
self.pool4 = nn.Pool(kernel_size=2, stride=2, op='maximum')
self.conv5_1 = nn.Conv(512, 512, kernel_size=3, padding=1)
self.conv5_2 = nn.Conv(512, 512, kernel_size=3, padding=1)
self.conv5_3 = nn.Conv(512, 512, kernel_size=3, padding=1)
self.pool5 = nn.Pool(kernel_size=3, stride=1, padding=1, op='maximum')
self.conv6 = nn.Conv(512, 1024, kernel_size=3, padding=6, dilation=6)
self.conv7 = nn.Conv(1024, 1024, kernel_size=1)
def execute(self, image):
out = nn.relu(self.conv1_1(image))
out = nn.relu(self.conv1_2(out))
out = self.pool1(out)
out = nn.relu(self.conv2_1(out))
out = nn.relu(self.conv2_2(out))
out = self.pool2(out)
out = nn.relu(self.conv3_1(out))
out = nn.relu(self.conv3_2(out))
out = nn.relu(self.conv3_3(out))
out = self.pool3(out)
out = nn.relu(self.conv4_1(out))
out = nn.relu(self.conv4_2(out))
out = nn.relu(self.conv4_3(out))
conv4_3_feats = out
out = self.pool4(out)
out = nn.relu(self.conv5_1(out))
out = nn.relu(self.conv5_2(out))
out = nn.relu(self.conv5_3(out))
out = self.pool5(out)
out = nn.relu(self.conv6(out))
conv7_feats = nn.relu(self.conv7(out))
return (conv4_3_feats, conv7_feats)
class AuxiliaryConvolutions(nn.Module):
def __init__(self):
super(AuxiliaryConvolutions, self).__init__()
self.conv8_1 = nn.Conv(1024, 256, kernel_size=1, padding=0)
self.conv8_2 = nn.Conv(256, 512, kernel_size=3, stride=2, padding=1)
self.conv9_1 = nn.Conv(512, 128, kernel_size=1, padding=0)
self.conv9_2 = nn.Conv(128, 256, kernel_size=3, stride=2, padding=1)
self.conv10_1 = nn.Conv(256, 128, kernel_size=1, padding=0)
self.conv10_2 = nn.Conv(128, 256, kernel_size=3, padding=0)
self.conv11_1 = nn.Conv(256, 128, kernel_size=1, padding=0)
self.conv11_2 = nn.Conv(128, 256, kernel_size=3, padding=0)
def execute(self, conv7_feats):
out = nn.relu(self.conv8_1(conv7_feats))
out = nn.relu(self.conv8_2(out))
conv8_2_feats = out
out = nn.relu(self.conv9_1(out))
out = nn.relu(self.conv9_2(out))
conv9_2_feats = out
out = nn.relu(self.conv10_1(out))
out = nn.relu(self.conv10_2(out))
conv10_2_feats = out
out = nn.relu(self.conv11_1(out))
conv11_2_feats = nn.relu(self.conv11_2(out))
return (conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats)
PredictionConvolutions将上述的6个Feature map经过若干层卷积操作最终concat在一起形成[bs, 8732, 4]的locs信息以及[bs, 8732, 1]的classes_scores信息。
class PredictionConvolutions(nn.Module):
def __init__(self, n_classes):
super(PredictionConvolutions, self).__init__()
self.n_classes = n_classes
n_boxes = {
'conv4_3': 4,
'conv7': 6,
'conv8_2': 6,
'conv9_2': 6,
'conv10_2': 4,
'conv11_2': 4,
}
self.loc_conv4_3 = nn.Conv(512, (n_boxes['conv4_3'] * 4), kernel_size=3, padding=1)
self.loc_conv7 = nn.Conv(1024, (n_boxes['conv7'] * 4), kernel_size=3, padding=1)
self.loc_conv8_2 = nn.Conv(512, (n_boxes['conv8_2'] * 4), kernel_size=3, padding=1)
self.loc_conv9_2 = nn.Conv(256, (n_boxes['conv9_2'] * 4), kernel_size=3, padding=1)
self.loc_conv10_2 = nn.Conv(256, (n_boxes['conv10_2'] * 4), kernel_size=3, padding=1)
self.loc_conv11_2 = nn.Conv(256, (n_boxes['conv11_2'] * 4), kernel_size=3, padding=1)
self.cl_conv4_3 = nn.Conv(512, (n_boxes['conv4_3'] * n_classes), kernel_size=3, padding=1)
self.cl_conv7 = nn.Conv(1024, (n_boxes['conv7'] * n_classes), kernel_size=3, padding=1)
self.cl_conv8_2 = nn.Conv(512, (n_boxes['conv8_2'] * n_classes), kernel_size=3, padding=1)
self.cl_conv9_2 = nn.Conv(256, (n_boxes['conv9_2'] * n_classes), kernel_size=3, padding=1)
self.cl_conv10_2 = nn.Conv(256, (n_boxes['conv10_2'] * n_classes), kernel_size=3, padding=1)
self.cl_conv11_2 = nn.Conv(256, (n_boxes['conv11_2'] * n_classes), kernel_size=3, padding=1)
def execute(self, conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats):
batch_size = conv4_3_feats.shape[0]
l_conv4_3 = self.loc_conv4_3(conv4_3_feats)
l_conv4_3 = jt.transpose(l_conv4_3, [0, 2, 3, 1])
l_conv4_3 = jt.reshape(l_conv4_3, [batch_size, -1, 4])
l_conv7 = self.loc_conv7(conv7_feats)
l_conv7 = jt.transpose(l_conv7, [0, 2, 3, 1])
l_conv7 = jt.reshape(l_conv7, [batch_size, -1, 4])
l_conv8_2 = self.loc_conv8_2(conv8_2_feats)
l_conv8_2 = jt.transpose(l_conv8_2, [0, 2, 3, 1])
l_conv8_2 = jt.reshape(l_conv8_2, [batch_size, -1, 4])
l_conv9_2 = self.loc_conv9_2(conv9_2_feats)
l_conv9_2 = jt.transpose(l_conv9_2, [0, 2, 3, 1])
l_conv9_2 = jt.reshape(l_conv9_2, [batch_size, -1, 4])
l_conv10_2 = self.loc_conv10_2(conv10_2_feats)
l_conv10_2 = jt.transpose(l_conv10_2, [0, 2, 3, 1])
l_conv10_2 = jt.reshape(l_conv10_2, [batch_size, -1, 4])
l_conv11_2 = self.loc_conv11_2(conv11_2_feats)
l_conv11_2 = jt.transpose(l_conv11_2, [0, 2, 3, 1])
l_conv11_2 = jt.reshape(l_conv11_2, [batch_size, -1, 4])
c_conv4_3 = self.cl_conv4_3(conv4_3_feats)
c_conv4_3 = jt.transpose(c_conv4_3, [0, 2, 3, 1])
c_conv4_3 = jt.reshape(c_conv4_3, [batch_size, -1, self.n_classes])
c_conv7 = self.cl_conv7(conv7_feats)
c_conv7 = jt.transpose(c_conv7, [0, 2, 3, 1])
c_conv7 = jt.reshape(c_conv7, [batch_size, -1, self.n_classes])
c_conv8_2 = self.cl_conv8_2(conv8_2_feats)
c_conv8_2 = jt.transpose(c_conv8_2, [0, 2, 3, 1])
c_conv8_2 = jt.reshape(c_conv8_2, [batch_size, -1, self.n_classes])
c_conv9_2 = self.cl_conv9_2(conv9_2_feats)
c_conv9_2 = jt.transpose(c_conv9_2, [0, 2, 3, 1])
c_conv9_2 = jt.reshape(c_conv9_2, [batch_size, -1, self.n_classes])
c_conv10_2 = self.cl_conv10_2(conv10_2_feats)
c_conv10_2 = jt.transpose(c_conv10_2, [0, 2, 3, 1])
c_conv10_2 = jt.reshape(c_conv10_2, [batch_size, -1, self.n_classes])
c_conv11_2 = self.cl_conv11_2(conv11_2_feats)
c_conv11_2 = jt.transpose(c_conv11_2, [0, 2, 3, 1])
c_conv11_2 = jt.reshape(c_conv11_2, [batch_size, -1, self.n_classes])
locs = jt.contrib.concat([l_conv4_3, l_conv7, l_conv8_2, l_conv9_2, l_conv10_2, l_conv11_2], dim=1)
classes_scores = jt.contrib.concat([c_conv4_3, c_conv7, c_conv8_2, c_conv9_2, c_conv10_2, c_conv11_2], dim=1)
return (locs, classes_scores)
3. 模型训练
模型训练参数设定如下:
# parameters
batch_size = 20 # batch大小
iterations = 120000 # 一共要训的轮数
decay_lr_at = [80000, 100000] # 在这些轮的时候学习率乘以0.1
start_epoch = 0 # 开始epoch
print_freq = 20 # train的时候,多少个iter打印一次信息
lr = 3e-4 # 学习率
momentum = 0.9 # SGD的momentum
weight_decay = 5e-4 # SGD的weight_decay
grad_clip = 1 # 设置是否要把梯度clamp到[-grad_clip, grad_clip],如果是None则不clip
定义模型、优化器、损失函数、训练/验证数据加载器。
model = SSD300(n_classes=n_classes)
optimizer = nn.SGD(model.parameters(),
lr,
momentum=momentum,
weight_decay=weight_decay)
criterion = MultiBoxLoss(priors_cxcy=model.priors_cxcy)
train_loader = PascalVOCDataset(data_folder,
split='train',
keep_difficult=keep_difficult,
batch_size=batch_size,
shuffle=False)
val_loader = PascalVOCDataset(data_folder,
split='test',
keep_difficult=keep_difficult,
batch_size=batch_size,
shuffle=False)
epochs = iterations // (len(train_loader) // 32) # 原论文batch_size为32跑了120000个iters,由此计算出epoches
decay_lr_at = [it // (len(train_loader) // 32) for it in decay_lr_at] # 并计算出需要降lr的epochs集合
for epoch in range(epochs):
if epoch in decay_lr_at:
optimizer.lr *= 0.1
train(train_loader=train_loader,
model=model,
criterion=criterion,
optimizer=optimizer,
epoch=epoch)
if epoch % 5 == 0 and epoch > 0:
evaluate(test_loader=val_loader, model=model)
损失函数设计:使用L1损失函数L1Loss监督predicted_locs和boxes的差距,使用交叉熵损失函数CrossEntropyLoss来监督predicted_scores和labels的差距。其中正负样本比例为1:3。
class L1Loss(nn.Module):
def __init__(self, size_average=None, reduce=None, reduction='mean'):
self.size_average = size_average
self.reduce = reduce
self.reduction = reduction
def execute(self, input, target):
ret = jt.abs(input - target)
if self.reduction != None:
ret = jt.mean(ret) if self.reduction == 'mean' else jt.sum(ret)
return ret
class CrossEntropyLoss(nn.Module):
def __init__(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean'):
self.ignore_index = ignore_index
self.reduction = reduction
def execute(self, input, target):
bs_idx = jt.array(range(input.shape[0]))
ret = (- jt.log(nn.softmax(input, dim=1)))[bs_idx, target]
if self.reduction != None:
ret = jt.mean(ret) if self.reduction == 'mean' else jt.sum(ret)
return ret
class MultiBoxLoss(nn.Module):
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.0):
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = L1Loss()
self.cross_entropy = CrossEntropyLoss(reduce=False, reduction=None)
def execute(self, predicted_locs, predicted_scores, boxes, labels):
# 使用L1Loss监督predicted_locs和boxes的差距
loc_loss = self.smooth_l1(
(predicted_locs * positive_priors.broadcast([1,1,4], [2])),
(true_locs * positive_priors.broadcast([1,1,4], [2]))
)
# 使用交叉熵CrossEntropyLoss来监督predicted_scores和labels的差距
conf_loss_all = self.cross_entropy(
jt.reshape(predicted_scores, [-1, n_classes]), jt.reshape(true_classes, [-1,])
)
# ... 省略部分代码
conf_loss = ((conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.float32().sum())
return (conf_loss + (self.alpha * loc_loss))
模型训练。
def train(train_loader, model, criterion, optimizer, epoch):
global best_loss, exp_id
model.train()
for i, (images, boxes, labels, _) in enumerate(train_loader):
images = jt.array(images)
predicted_locs, predicted_scores = model(images)
loss, conf_loss, loc_loss = criterion(predicted_locs, predicted_scores, boxes, labels)
if grad_clip is not None:
optimizer.grad_clip = grad_clip
optimizer.step(loss)
if i % print_freq == 0:
print(f'Experiment id: {exp_id} || Epochs: [{epoch}/{epochs}] || Iters: [{i}/{length}] || Loss: {loss} || Best mAP: {best_mAP}')
writer.add_scalar('Train/Loss', loss.numpy()[0], global_step=i + epoch * length)
writer.add_scalar('Train/Loss_conf', conf_loss.numpy()[0], global_step=i + epoch * length)
writer.add_scalar('Train/Loss_loc', loc_loss.numpy()[0], global_step=i + epoch * length)
4. 结果
我们在VOC的test数据集(4952张图片)上测试了mAP,下表是在不同的类别上Pytorh与Jittor的mAP对比。最后一行是平均mAP。
| 类别 | mAP (Pytorch) | mAP (Jittor) |
| aeroplane | 0.7886 | 0.7900 |
| bicycle | 0.8303 | 0.8285 |
| bird | 0.7593 | 0.7452 |
| boat | 0.7100 | 0.6903 |
| bottle | 0.4408 | 0.4369 |
| bus | 0.8403 | 0.8495 |
| car | 0.8470 | 0.8464 |
| cat | 0.8768 | 0.8725 |
| chair | 0.5668 | 0.5737 |
| cow | 0.8267 | 0.8204 |
| diningtable | 0.7365 | 0.7546 |
| dog | 0.8494 | 0.8550 |
| horse | 0.8689 | 0.8769 |
| motorbike | 0.8246 | 0.8214 |
| person | 0.7724 | 0.7694 |
| pottedplant | 0.4872 | 0.4987 |
| sheep | 0.7448 | 0.7643 |
| sofa | 0.7637 | 0.7532 |
| train | 0.8377 | 0.8517 |
| tvmonitor | 0.7499 | 0.7373 |
| average | 0.756 | 0.757 |
下面展示了一些图片测试的结果。








参考文献
[1] https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection
[2] Liu, Wei, et al. “Ssd: Single shot multibox detector.” European conference on computer vision. Springer, Cham, 2016.
[3] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.