
生成对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。GAN模型由生成器(Generator)和判别器(Discriminator)两个部分组成。在训练过程中,生成器的目标就是尽量生成真实的图片去欺骗判别器。而判别器的目标就是尽量把生成器生成的图片和真实的图片分别开来。这样,生成器和判别器构成了一个动态的“博弈过程”。许多相关的研究工作表明GAN能够产生效果非常真实的生成效果。
本教程使用Jittor框架实现了一种经典GAN模型LSGAN[1]。LSGAN将GAN的目标函数由交叉熵损失替换成最小二乘损失,以此拒绝了标准GAN生成的图片质量不高以及训练过程不稳定这两个缺陷。本教程通过LSGAN的实现介绍了Jittor数据加载、模型定义、模型训练的使用方法。
LSGAN论文:https://arxiv.org/abs/1611.04076
LSGAN-Jittor源码:https://github.com/Jittor/lsgan-jittor
1.数据集准备
本教程使用两种数据集进行LSGAN的训练,分别是Jittor自带的数据集MNIST,和用户构建的数据集CelebA。您可以通过以下链接下载CelebA数据集。
- CelebA 数据集: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
使用Jittor自带的MNIST数据加载器方法如下。使用jittor.transform可以进行数据归一化及数据增强,这里本教程通过transform将图片归一化到指定区间,并resize到标准大小112*112。。通过set_attrs函数可以修改数据集的相关参数,如batch_size、shuffle及transform等。
from jittor.dataset.mnist import MNIST
import jittor.transform as transform
transform = transform.Compose([
transform.Resize(size=img_size),
transform.ImageNormalize(mean=[0.5], std=[0.5])
])
train_loader = MNIST (train=True, transform=transform)
.set_attrs(batch_size=batch_size, shuffle=True)
val_loader = MNIST (train=False, transform = transform)
.set_attrs(batch_size=1, shuffle=True)
使用用户构建的CelebA数据集方法如下,通过通用数据加载器jittor.dataset.dataset.ImageFolder,输入数据集路径即可构建用户数据集。
from jittor.dataset.dataset import ImageFolder
import jittor.transform as transform
transform = transform.Compose([
transform.Resize(size=img_size),
transform.ImageNormalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dir = './data/celebA_train'
train_loader = ImageFolder(train_dir)
.set_attrs(transform=transform, batch_size=batch_size, shuffle=True)
val_dir = './data/celebA_eval'
val_loader = ImageFolder(val_dir)
.set_attrs(transform=transform, batch_size=1, shuffle=True)
2.模型定义
2.1.网络结构
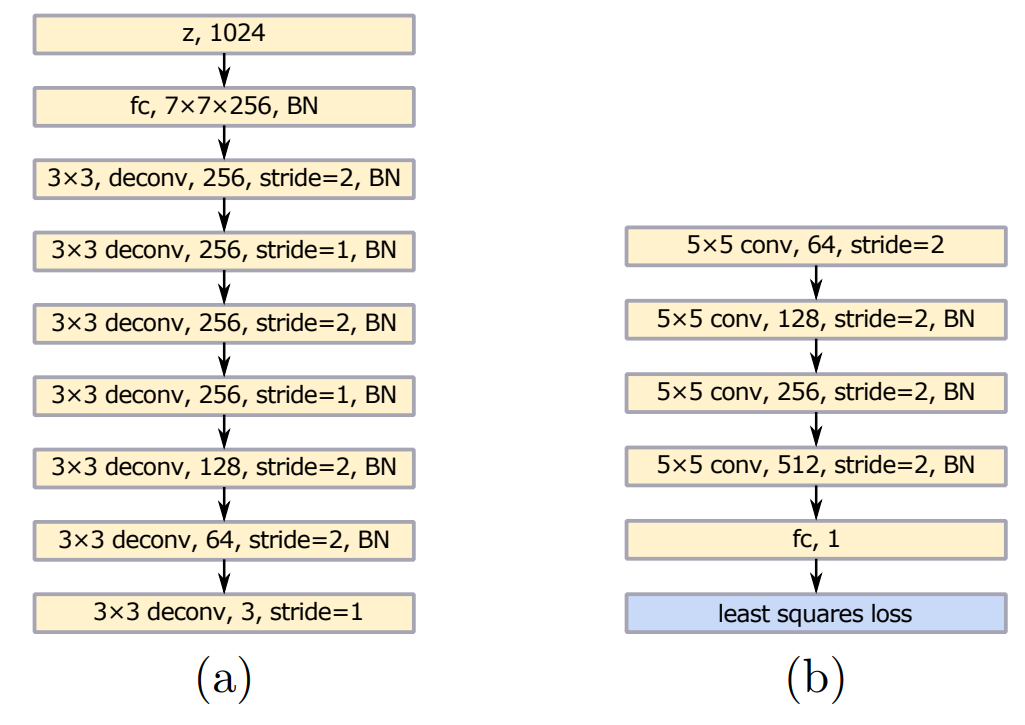
本教程使用LSGAN进行图像生成,下图为LSGAN论文给出的网络架构图,其中(a)为生成器,(b)为判别器。生成器网络输入一个1024维的向量,生成分辨率为112*112的图像;判别器网络输入112*112的图像,输出一个数字表示输入图像为真实图像的可信程度。
受到VGG[2]模型的启发,生成器在与DCGAN[3]的结构基础上在前两个反卷积层之后增加了两个步长=1的反卷积层。除使用最小二乘损失函数外判别器的结构与DCGAN中的结构相同。与DCGAN相同,生成器和判别器分别使用了ReLU激活函数和LeakyReLU激活函数。
下面将介绍如何使用Jittor定义一个网络模型。定义模型需要继承基类jittor.Module,并实现__init__和execute函数。__init__函数在模型声明时会被调用,用于进行模型内部op或其他模型的声明及参数的初始化。该模型初始化时输入参数dim表示训练图像的通道数,对于MNIST数据集dim为1,对于CelebA数据集dim为3。
execute函数在网络前向传播时会被调用,用于定义前向传播的计算图,通过autograd机制在训练时Jittor会自动构建反向计算图。
import jittor as jt
from jittor import nn, Module
class generator(Module):
def __init__(self, dim=3):
super(generator, self).__init__()
self.fc = nn.Linear(1024, 7*7*256)
self.fc_bn = nn.BatchNorm(256)
self.deconv1 = nn.ConvTranspose(256, 256, 3, 2, 1, 1)
self.deconv1_bn = nn.BatchNorm(256)
self.deconv2 = nn.ConvTranspose(256, 256, 3, 1, 1)
self.deconv2_bn = nn.BatchNorm(256)
self.deconv3 = nn.ConvTranspose(256, 256, 3, 2, 1, 1)
self.deconv3_bn = nn.BatchNorm(256)
self.deconv4 = nn.ConvTranspose(256, 256, 3, 1, 1)
self.deconv4_bn = nn.BatchNorm(256)
self.deconv5 = nn.ConvTranspose(256, 128, 3, 2, 1, 1)
self.deconv5_bn = nn.BatchNorm(128)
self.deconv6 = nn.ConvTranspose(128, 64, 3, 2, 1, 1)
self.deconv6_bn = nn.BatchNorm(64)
self.deconv7 = nn.ConvTranspose(64 , dim, 3, 1, 1)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def execute(self, input):
x = self.fc(input).reshape((-1, 256, 7, 7))
x = self.relu(self.fc_bn(x))
x = self.relu(self.deconv1_bn(self.deconv1(x)))
x = self.relu(self.deconv2_bn(self.deconv2(x)))
x = self.relu(self.deconv3_bn(self.deconv3(x)))
x = self.relu(self.deconv4_bn(self.deconv4(x)))
x = self.relu(self.deconv5_bn(self.deconv5(x)))
x = self.relu(self.deconv6_bn(self.deconv6(x)))
x = self.tanh(self.deconv7(x))
return x
class discriminator(nn.Module):
def __init__(self, dim=3):
super(discriminator, self).__init__()
self.conv1 = nn.Conv(dim, 64, 5, 2, 2)
self.conv2 = nn.Conv(64, 128, 5, 2, 2)
self.conv2_bn = nn.BatchNorm(128)
self.conv3 = nn.Conv(128, 256, 5, 2, 2)
self.conv3_bn = nn.BatchNorm(256)
self.conv4 = nn.Conv(256, 512, 5, 2, 2)
self.conv4_bn = nn.BatchNorm(512)
self.fc = nn.Linear(512*7*7, 1)
self.leaky_relu = nn.Leaky_relu()
def execute(self, input):
x = self.leaky_relu(self.conv1(input), 0.2)
x = self.leaky_relu(self.conv2_bn(self.conv2(x)), 0.2)
x = self.leaky_relu(self.conv3_bn(self.conv3(x)), 0.2)
x = self.leaky_relu(self.conv4_bn(self.conv4(x)), 0.2)
x = x.reshape((x.shape[0], 512*7*7))
x = self.fc(x)
return x
2.2.损失函数
损失函数采用最小二乘损失函数,其中判别器损失函数如下。其中x为真实图像,z为服从正态分布的1024维向量,a取值为1,b取值为0。
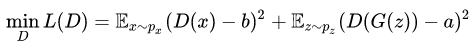
生成器损失函数如下。其中z为服从正态分布的1024维向量,c取值为1。
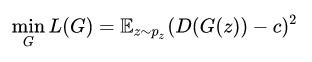
具体实现如下,x为生成器的输出值,b表示该图像是否希望被判别为真。
def ls_loss(x, b):
mini_batch = x.shape[0]
y_real_ = jt.ones((mini_batch,))
y_fake_ = jt.zeros((mini_batch,))
if b:
return (x-y_real_).sqr().mean()
else:
return (x-y_fake_).sqr().mean()
3.模型训练
3.1.参数设定
参数设定如下。
# 通过use_cuda设置在GPU上进行训练
jt.flags.use_cuda = 1
# 批大小
batch_size = 128
# 学习率
lr = 0.0002
# 训练轮数
train_epoch = 20 if task=="MNIST" else 50
# 训练图像标准大小
img_size = 112
# Adam优化器参数
betas = (0.5,0.999)
# 数据集图像通道数,MNIST为1,CelebA为3
dim = 1 if task=="MNIST" else 3
3.2.模型、优化器声明
分别声明生成器和判别器,并使用Adam作为优化器。
# 生成器
G = generator (dim)
# 判别器
D = discriminator (dim)
# 生成器优化器
G_optim = nn.Adam(G.parameters(), lr, betas=betas)
# 判别器优化器
D_optim = nn.Adam(D.parameters(), lr, betas=betas)
3.3.训练与验证
def train(epoch):
for batch_idx, (x_, target) in enumerate(train_loader):
mini_batch = x_.shape[0]
# 判别器训练
D_result = D(x_)
D_real_loss = ls_loss(D_result, True)
z_ = init.gauss((mini_batch, 1024), 'float')
G_result = G(z_)
D_result_ = D(G_result)
D_fake_loss = ls_loss(D_result_, False)
D_train_loss = D_real_loss + D_fake_loss
D_train_loss.sync()
D_optim.step(D_train_loss)
# 生成器训练
z_ = init.gauss((mini_batch, 1024), 'float')
G_result = G(z_)
D_result = D(G_result)
G_train_loss = ls_loss(D_result, True)
G_train_loss.sync()
G_optim.step(G_train_loss)
if (batch_idx%100==0):
print('D training loss =', D_train_loss.numpy().mean())
print('G training loss =', G_train_loss.numpy().mean())
def validate(epoch):
D_losses = []
G_losses = []
G.eval()
D.eval()
for batch_idx, (x_, target) in enumerate(eval_loader):
mini_batch = x_.shape[0]
# 判别器损失计算
D_result = D(x_)
D_real_loss = ls_loss(D_result, True)
z_ = jt.init.gauss((mini_batch, 1024), 'float')
G_result = G(z_)
D_result_ = D(G_result)
D_fake_loss = ls_loss(D_result_, False)
D_train_loss = D_real_loss + D_fake_loss
D_losses.append(D_train_loss.numpy().mean())
# 生成器损失计算
z_ = jt.init.gauss((mini_batch, 1024), 'float')
G_result = G(z_)
D_result = D(G_result)
G_train_loss = ls_loss(D_result, True)
G_losses.append(G_train_loss.numpy().mean())
G.train()
D.train()
print("validate: epoch",epoch)
print(' D validate loss =', np.array(D_losses).mean())
print(' G validate loss =', np.array(G_losses).mean())
for epoch in range(train_epoch):
train(epoch)
validate(epoch)
4.结果与测试
4.1.生成结果
本教程分别使用MNIST和CelebA数据集分别进行了20个和50个epoch的训练。训练完成后各随机采样了25张图像,结果如下。


4.2.速度对比
本教程使用Jittor与主流的深度学习框架PyTorch进行了训练速度的对比,下表为PyTorch(是/否打开benchmark)及Jittor在两种数据集上进行1次训练迭带的平均使用时间。得益于Jittor的异步接口及特有的元算子融合技术,其训练速度(平均每秒训练iter数)比PyTorch快了约50%~60%。
| MNIST | CelebA | |
|---|---|---|
| pytorch | 0.4584 s | 0.4929 s |
| pytorch-benchmark | 0.4356 s | 0.4698 s |
| Jittor | 0.2871 s | 0.3108 s |
| speed up (pytorch) | 59.7% | 58.6% |
| speed up (pytorch-benchmark) | 51.7% | 51.2% |
5.参考文献
[1] Mao, Xudong, et al. “Least squares generative adversarial networks.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
[2] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[3] Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).